- JavaScript | Как получить все ссылки на HTML-странице?
- Все ссылки на HTML-странице из консоли браузера, работающего на Chrome
- Все ссылки на HTML-странице с выводом результатов на текущую страницу (в эту же вкладку браузера)
- Куда вводить эти команды?
- Может ты хочешь знать как получить ВСЕ ССЫЛКИ САЙТА ?
- Видео инструкция по получению всех ссылок на HTML-странице
- Пошаговая инструкция — для тех кто хочет разобраться в вопросе сбора ссылок
- 1. Открываем страницу сайта в браузере
- 2. Открываем инструменты разработчика
- 3. Находим в инструментах вкладку Console
- 4. Получаем HTML-коллекцию элементов A
- 5. Преобразовываем HTML-коллекцию в Массив
- 6. Достаём из элементов массива значения ключа href
- 7. Массив перегоняем в строку и добавляем разделитель между элементами
- 8. Выводим строку на страницу текущего документа
- Что дальше?
- Для кого эта статья?
- Ссылки
- Extract Links From HTML
- What is a HTML?
- What Is Link?
- Why Extract URLs From HTML?
- How Do You Extract URLs From HTML?
- My HTML Document Has Duplicate Links. What Can You Do?
- Извлечь все ссылки с веб-страницы
- Метод 1. Извлечение ссылок через консоль браузера
- Метод 2. Извлечение ссылок через плагины браузера
- Метод 3. Извлечение ссылок через онлайн сервисы
- Метод х. Извлечение ссылок через
- Нет комментариев
- Добавить комментарий
JavaScript | Как получить все ссылки на HTML-странице?
Вернёт объект-прототип класса HTMLCollection с объектами ссылок (HTML-элементами ). Эта команда для разработчиков, которые понимают, что делать дальше.
Все ссылки на HTML-странице из консоли браузера, работающего на Chrome
$x(path) возвращает массив элементов DOM, соответствующих заданному выражению XPath.
Все ссылки на HTML-странице с выводом результатов на текущую страницу (в эту же вкладку браузера)
document.write(((Array.from(document.getElementsByTagName("a"))).map(i => return i.href>)).join("
")) или document.write(([. document.getElementsByTagName("a")].map(i=>i.href)).join(" "))

Для удобства. Выведет в столбик все адреса из ссылок в текущий документ. Разметка страницы перезапишется, результат легко закинуть в EXCEL или WORD или туда, куда тебе это нужно.
Куда вводить эти команды?
Открываете HTML-страницу, с которой хотите получить все веб-ссылки. Включаете «Инструменты разработчика» в браузере (CTRL + SHIFT + i). Находите вкладку «Console«. Тыкаете курсор в белое поле справа от синей стрелочки. Вставляете команду. Жмёте клавишу ENTER.
Для тех кто не понял длинную строчку кода выше, предлагаю упрощённую для понимания версию. Пошаговая инструкция по извлечению ссылок со страницы, и видео ниже.
Может ты хочешь знать как получить ВСЕ ССЫЛКИ САЙТА ?
Специально для тебя написана статья «JavaScript | Список ссылок сайта«. Она о том, каким образом ты можешь собрать все ссылки любого сайта при помощи JavaScript, который работает на ЧПУ-адресах.
Видео инструкция по получению всех ссылок на HTML-странице
Этот метод также работает и с XML-документами.
Пошаговая инструкция — для тех кто хочет разобраться в вопросе сбора ссылок
1. Открываем страницу сайта в браузере
Для примера возьмём страницу любого интернет-магазина с товарами. Пусть это будут фены. На странице со списком фенов будет большое количество ссылок, как на сами товары, так и на пункты навигации по сайту.

2. Открываем инструменты разработчика
Включаете «Инструменты разработчика» в браузере (CTRL + SHIFT + i). Мы не будем использовать редакторы кода т. к. задача очень примитивная. С редактором кода нужно постоянно прыгать из окна в окно — это неудобно. Мы будем пользоваться консолью браузера для ввода команд JavaScript.

3. Находим в инструментах вкладку Console
Ввод команд осуществляется в белое поле справа от синей стрелочки в форме уголка 90 градусов. Иногда, при вводе команд, будут ошибки самого ввода. Любые ошибки ввода команд легко исправлять простым нажатием клавиши «вверх» на клавиатуре (стрелочка вверх) и исправлением команды. Опечатки возможны и неизбежны.
В консоли мы сразу будем видеть результат своей работы.
4. Получаем HTML-коллекцию элементов A
Вводим команду для получения всех HTML-элементов с текущий страницы (с текущего документа) в браузере:
var a = document.getElementsByTagName("a")
В результате мы получим объект HTMLCollection который будет состоять из узлов (HTML-элементов ). Это массиво-подобный объект, но он не умеет работать с методами массивов.
Выводим переменную a в консоль:

5. Преобразовываем HTML-коллекцию в Массив
Используем метод from() конструктора Array , чтобы получить массив:
Выводим переменную a в консоль:

Эта операция необходима для того, чтобы иметь возможность трансформировать элементы массива при помощи метода прототипов объекта Array — map()
С коллекций HTML мы не сможем так работать.
6. Достаём из элементов массива значения ключа href
Из «грязного» массива получаем «чистый». Очищаем элементы массива от лишнего при помощи метода прототипов объекта Array — map() . Нас интересуют только ссылки. Задача такая. Ключ «href» вернёт нам полный URI — это значит что все относительные ссылки будут преобразованы в абсолютные.
var c = b.map(i => return i.href>)
Если бы нас интересовали относительные ссылки, то мы бы собирали новый массив из ключей «pathname«.
Выводим переменную a в консоль:

7. Массив перегоняем в строку и добавляем разделитель между элементами
Нам нужно просто слепить все элементы массива в одну длинную строку, которая будет на странице переноситься в столбец при помощи HTML-элемента
. Для этой цели мы используем метод прототипов объекта Array — join() .
Выводим переменную a в консоль:

8. Выводим строку на страницу текущего документа
Эта операция очистит содержимое страницы и выведет список. При обновлении страницы в браузере можно будет вернуться к оригинальной странице с фенами.

Что дальше?
Теперь можно пользоваться результатом вывода и скопировать список себе в эксель таблицу, например. Потом можно почистить дубли до получения уникальных ссылок. Можно попробовать отделить ссылки по типу «внешние/внутренние«.
Можно поискать применение «фрагмента» URI (это решётка #) на предмет качественной разметки страницы. Как правило большие страницы, в которых много контента имеют дополнительную семантическую разметку при помощи фрагмента URI. То есть любой пользователь может получить ссылку на конкретный фрагмент текста в документе. (как правило это будет текст на HTML-странице)
Можно понять правильно ли оформлены ссылки на изображения. Можно поискать ссылки с «запросами» URI (это знак вопроса ?), которые могут транслироваться в рекламные сети. Можно поискать «корявые» ЧПУ для SEO.
Можно поискать «непопрятанные» ссылки на технические разделы сайта, которыми пользуются разработчики. Из них можно «подолбить» админ-панели на попытку входа в систему. Ну и т.д.. Информация о ссылочном профиле страницы может оказаться полезной.
Для кого эта статья?
Эта статья создана в образовательных целях, чтобы укрепить навыки программирования на JavaScript, а также поработать с готовыми API. Статья будет очень полезна тем людям, которые никогда не слышали слово JavaScript и которые ищут способы «Как собрать все ссылки со страницы?» или «Как извлечь все ссылки из HTML?». Эти люди знают свои потребности, но не знают о способах их реализации.
Ссылки
Читайте перевод полной версии стандарта «объектной модели документа», чтобы ознакомиться со всеми концепциями и интерфейсами.
DOM — Living Standard — https://dom.spec.whatwg.org
Читайте официальную документацию живого стандарта «объектной модели документа», чтобы быть в курсе последних изменений.
Extract Links From HTML
This is a free online tool to extract URLs from a HTML document. You can copy/paste any HTML document in the text area and hit the «Extract URLs» button to get list of all unique links on the HTML page.
This tool is also commonly called as href extractor tool due to HTML attribute HREF in the anchor tag a .
What is a HTML?
HTML (HyperText Markup Language) is used for web pages. All web pages on internet use this language. Browsers understand this language and render pages accordingly.
What Is Link?

A link or URL or HREF value is common name for web page address. A link uniquely identifies a page location on internet.
Why Extract URLs From HTML?
Extracting the URL from HTML pages can be done for many reasons. I like to do it for web scraping and content research. HTML is powerful language for browsers, however, human can not easily read HTML pages. This page can easily extract all reference link from a HTML page and you can use them as you like.
How Do You Extract URLs From HTML?
Every HTML document contains link in a specific format. We look for anchor tags in HTML document and extract the value of HREF attribute from it.
My HTML Document Has Duplicate Links. What Can You Do?
We automatically remove duplicate links from the results.
Извлечь все ссылки с веб-страницы


Как извлечь все ссылки с веб-страницы? Задался я вопросом когда возникла необходимость пакетной загрузки большого числа файлов по ссылкам с веб-страницы публичного ФТП серванта. Туда-сюда из браузера в менеджер загрузки тыкать заколебёт, а файлы потребно скачать все и разом. Искать сторонний спец.софт не вариант, нужно уметь обойтись стандартным набором инструментов входящих Дебиан Линух репозиторий или в сам браузер.
Метод 1. Извлечение ссылок через консоль браузера
Подумалось сначала извлечь все ссылки с веб-страницы путём парсинга curl запроса, но на это не было времени и побежал я анонировать поиском, и наанонировал вот такой кусок JavaScript кода:
var x = document.querySelectorAll("a"); var myarray = [] for (var i=0; ix.length; i++){ var nametext = x[i].textContent; var cleantext = nametext.replace(/\s+/g, ' ').trim(); var cleanlink = x[i].href; myarray.push([cleantext,cleanlink]); }; function make_table() { var table = 'Name Links '; for (var i=0; imyarray.length; i++) { table += ''; }; var w = window.open(""); w.document.write(table); } make_table() '+ myarray[i][0] + ' '+myarray[i][1]+'
Куда его вставлять? В «Инструменты разработчика» браузера, открываем комбинацией на клаве « CTRL + SHIFT + i ». На вкладке «Console» в левом нижнем углу окна браузера есть неприметные две синие стрелки указывающие на узкую строку — ото туды и вставляем весь тот код, жмём/давим ENTER . В новой вкладке (всплывающие/выползающие окна нужно будет разрешить) появится список ссылок:
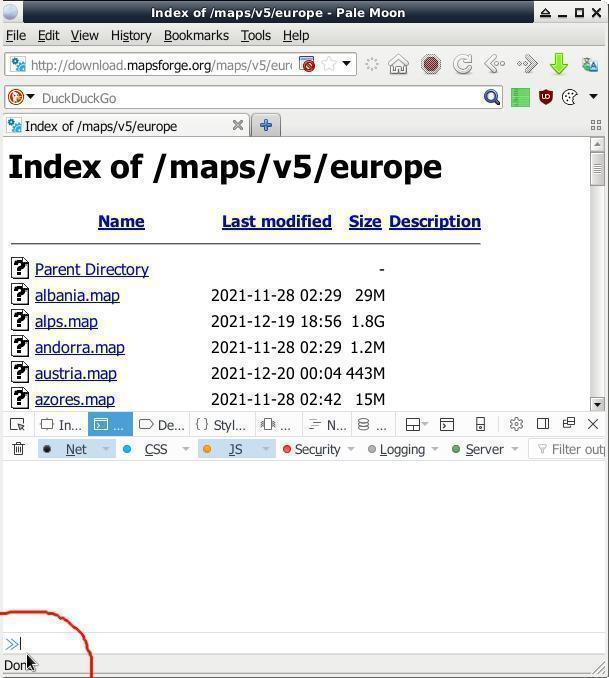
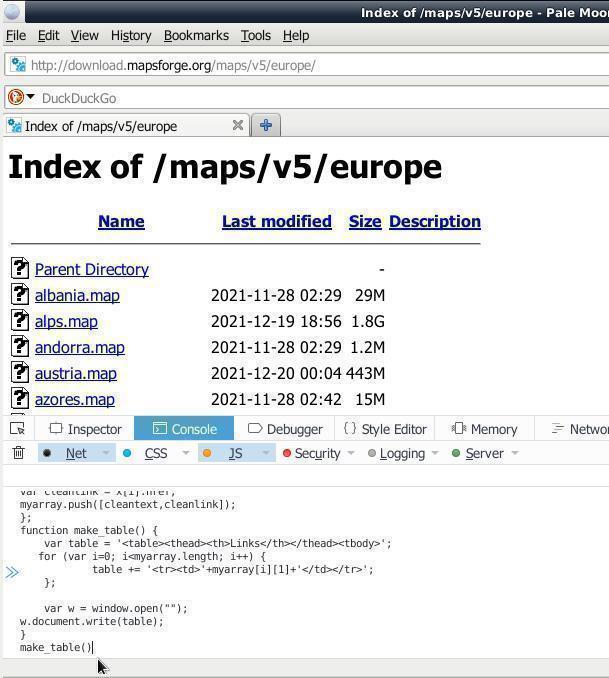
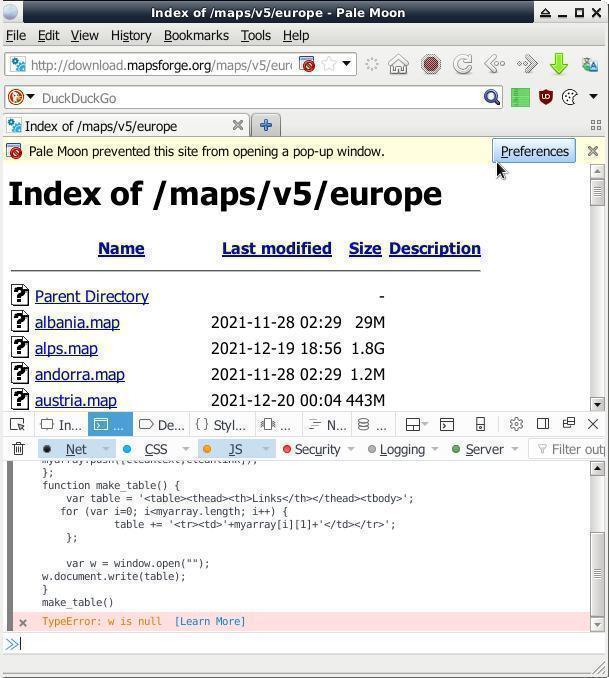
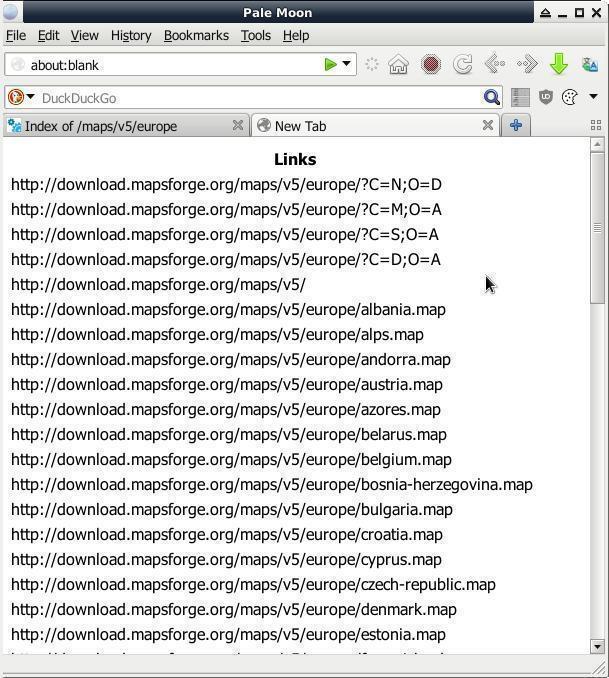 В данном примере извлекались ссылки с веб-страницы ФТП-серванта download.mapsforge.org для пакетной загрузки карт оффлайн-навигации. Можно также использовать для пакетной загрузки голых сисек/писек или кому чего угодно. Для насквозь мобилизированных киборгов/челоботов/андроидов, т.е. для мобильных юзеров, данный метод извлечения ссылок с веб-страницы наверно не вариант ибо могут возникнуть проблемы с комбинацией на клаве « CTRL + SHIFT + i » — тогда смотрим в сторону дополнений/плагинов к браузерам.
В данном примере извлекались ссылки с веб-страницы ФТП-серванта download.mapsforge.org для пакетной загрузки карт оффлайн-навигации. Можно также использовать для пакетной загрузки голых сисек/писек или кому чего угодно. Для насквозь мобилизированных киборгов/челоботов/андроидов, т.е. для мобильных юзеров, данный метод извлечения ссылок с веб-страницы наверно не вариант ибо могут возникнуть проблемы с комбинацией на клаве « CTRL + SHIFT + i » — тогда смотрим в сторону дополнений/плагинов к браузерам.
Метод 2. Извлечение ссылок через плагины браузера
- Link Gopher – Get this Extension for Firefox (en-US)
Extracts all links from web page, sorts them, removes duplicates, and displays them in a new tab for inspection or copy and paste into other systems.
Метод 3. Извлечение ссылок через онлайн сервисы
Извлечение ссылок через онлайн сервисы — это ещё тот квэст!
Куча сайто-говно-кодеров развелось, клепающих монструозные говно-сайты фреймворком «хуяк-хуяк» + конченная reCaptcha, и в продакшын. На такие «хуяк-хуяк-сервисы» уходит десятки МБ траффика, ресурсов железа, и хороший пучок нервов на пробивание пиЗЕ!данутой reCaptcha и часто + завал окна рекламой. В последнее время у меня впечатление, что кроме reCaptcha никакой иной на всей Планете уже нигде не осталось!
Но, местами нормальные онлайн сервисы извлечения ссылок попадаются (нарыто по запросу «Online Tool to Extract Links»):
- URL Extractor, Free Online Links Extractor, Extract HTML Links
На момент публикации был реально рабочий вариант онлайн сервиса для извлечения ссылок с веб-страницы
Метод х. Извлечение ссылок через
Через что ещё можно извлекать веб-ссылки? Через «питона»? Через «Ц», через «Ц++» или может через «Ж»? Вам через что бы ещё хотелося? В комменты пишите письма.
Пока усё, дасвидос/допобачендос/гудбай/аухфидерзейн.
АдМинь БагоИскатель ярый борец за безглючную работу любых механизмов и организмов во всей вселенной и потому пребывает в вечном поиске всяческих багов, а тот кто ищет как известно всегда находит. Когда что-то или кого-то вылечить не в состоянии, то со словами «Я в аду, а вы все черти» уходит в запой выйдя из которого снова берётся лечить неизлечимое.
Нет комментариев
Вы можете стать первым, кто добавит комментарий к этой записи.
Добавить комментарий
- Мессаги исключительно рекламного содержания, либо содержащие только одни оценочные суждения типа «круто» («отлично», «спасибо», «автор дебил» и т.п.) не публикуются;
- Злостным спамерам, пранкерам и прочей сетевой нечисти рекомендуем напрасно не тратить своего времени и удовлетворять свои больные фантазии на специализированных Интернет ресурсах!;
- Разумная обоснованная критика, замечания, дополнения приветствуются. Поля помеченные символом * обязательны к заполнению.
цену посылки то они специально занижают шоб на налогах экономить, выгодно обоим сторонам, а что фуфло парят, та кто бывает — просто наебизнес .
Тоже пользуюсь старым кнопочным и на днях получил слайд-шоу нарезку из 4 или 5 СМС, первое из которых начиналось: Бла-бла-бла . В Україні стартує .
костыль же высокоточный, под конкретную цель, а не универсальный. ip route flush default можно попробовать удалить, может и лишнее в некоторых .
Костыль 1 — если на машине две сети и подключена только wlan0, а проводная enp1s0 специально отключена, то wlan0 отвалится после строчки ip route flush .
оно ещё в марте-апреле как-то странно глюкало, с укр.ИП-адресов не пускало выдавая неизвестную ошибку, а через офшорные ИП заходи пожалуйста — украм .
-
- VMware сильно грузит хостовый HDD
- вероятно ответ малость запоздал. смотреть в диспетчере задач виндоса, сортирнуть.