- How to Read XML File with Python and Pandas
- Setup
- Step 1: Read XML File with read_xml()
- Step 2: Read XML File with read_xml() — remote
- Step 3: Read XML File as Python list or dict
- Step 4: Read multiple XML Files in Python
- Step 5: Read XML File — xmltodict
- Conclusion
- Reading and Writing XML Files in Python
- Using BeautifulSoup alongside with lxml parser
- Reading Data From an XML File
- Python3
- Writing an XML File
- Python3
- Using Elementtree
- Reading XML Files
- Python3
- Writing XML Files
How to Read XML File with Python and Pandas
In this quick tutorial, we’ll cover how to read or convert XML file to Pandas DataFrame or Python data structure.
Since version 1.3 Pandas offers an elegant solution for reading XML files: pd.read_xml() .
With the single line above we can read XML file to Pandas DataFrame or Python structure.
Below we will cover multiple examples in greater detail by using two ways:
Setup
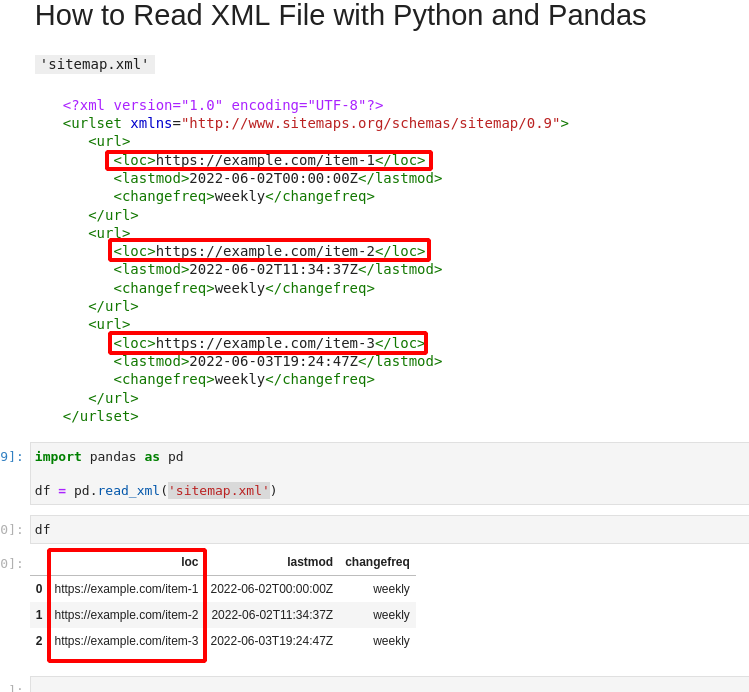
Suppose we have simple XML file with the following structure:
https://example.com/item-1 2022-06-02T00:00:00Z weekly https://example.com/item-2 2022-06-02T11:34:37Z weekly https://example.com/item-3 2022-06-03T19:24:47Z weekly which we would like to read as Pandas DataFrame like shown below:
| loc | lastmod | changefreq | |
|---|---|---|---|
| 0 | https://example.com/item-1 | 2022-06-02T00:00:00Z | weekly |
| 1 | https://example.com/item-2 | 2022-06-02T11:34:37Z | weekly |
| 2 | https://example.com/item-3 | 2022-06-03T19:24:47Z | weekly |
or getting the links as Python list:
['https://example.com/item-1', 'https://example.com/item-2', 'https://example.com/item-3'] Step 1: Read XML File with read_xml()
The official documentation of method read_xml() is placed on this link:
To read the local XML file in Python we can give the absolute path of the file:
import pandas as pd df = pd.read_xml('sitemap.xml') | loc | lastmod | changefreq | |
|---|---|---|---|
| 0 | https://example.com/item-1 | 2022-06-02T00:00:00Z | weekly |
| 1 | https://example.com/item-2 | 2022-06-02T11:34:37Z | weekly |
| 2 | https://example.com/item-3 | 2022-06-03T19:24:47Z | weekly |
The method has several useful parameters:
- xpath — The XPath to parse the required set of nodes for migration to DataFrame.
- elems_only — Parse only the child elements at the specified xpath. By default, all child elements and non-empty text nodes are returned.
- names — Column names for DataFrame of parsed XML data.
- encoding — Encoding of XML document.
- namespaces — The namespaces defined in XML document as dicts with key being namespace prefix and value the URI.
Step 2: Read XML File with read_xml() — remote
Now let’s use Pandas to read XML from a remote location.
The first parameter of read_xml() is: path_or_buffer described as:
String, path object (implementing os.PathLike[str]), or file-like object implementing a read() function. The string can be any valid XML string or a path. The string can further be a URL. Valid URL schemes include http, ftp, s3, and file.
So we can read remote files the same way:
import pandas as pd df = pd.read_xml( f'https://s3.example.com/sitemap.xml.gz') The final output will be exactly the same as before — DataFrame which has all values from the XML data.
Step 3: Read XML File as Python list or dict
Now suppose you need to convert XML file to Python list or dictionary.
We need to read the XML file first, then to convert the file to DataFrame and finally to get the values from this DataFrame by:
Example 1: List
['https://example.com/item-1', 'https://example.com/item-2', 'https://example.com/item-3'] Example 2: Dictionary
Example 3: Dictionary — orient index
df[['loc', 'changefreq']].to_dict(orient='index') Step 4: Read multiple XML Files in Python
Finally let’s see how to read multiple identical XML files with Python and Pandas.
Suppose that files are identical with the following format:
We can use the following code to read all files in a given range and concatenate them into a single DataFrame:
import pandas as pd df_temp = [] for i in (range(1, 10)): s = f'https://s3.example.com/sitemap.xml.gz' df_site = pd.read_xml(s) df_temp.append(df_site) The result is a list of DataFrames which can be concatenated into a single one by:
Now we have information from all XML files into df_all.
Step 5: Read XML File — xmltodict
There is an alternative solution for reading XML file in Python by using the library: xmltodict .
To read XML file we can do:
import xmltodict with open('sitemap.xml') as fd: doc = xmltodict.parse(fd.read()) Accessing elements can be done by:
Conclusion
In this article, we covered several ways to read XML file with Python and Pandas. Now we know how to read local or remote XML files, using two Python libraries.
Different options and parameters make the XML conversion with Python — easy and flexible.
By using DataScientYst — Data Science Simplified, you agree to our Cookie Policy.
Reading and Writing XML Files in Python
Extensible Markup Language, commonly known as XML is a language designed specifically to be easy to interpret by both humans and computers altogether. The language defines a set of rules used to encode a document in a specific format. In this article, methods have been described to read and write XML files in python.
Note: In general, the process of reading the data from an XML file and analyzing its logical components is known as Parsing. Therefore, when we refer to reading a xml file we are referring to parsing the XML document.
In this article, we would take a look at two libraries that could be used for the purpose of xml parsing. They are:
Using BeautifulSoup alongside with lxml parser
For the purpose of reading and writing the xml file we would be using a Python library named BeautifulSoup. In order to install the library, type the following command into the terminal.
pip install beautifulsoup4
Beautiful Soup supports the HTML parser included in Python’s standard library, but it also supports a number of third-party Python parsers. One is the lxml parser (used for parsing XML/HTML documents). lxml could be installed by running the following command in the command processor of your Operating system:
Firstly we will learn how to read from an XML file. We would also parse data stored in it. Later we would learn how to create an XML file and write data to it.
Reading Data From an XML File
There are two steps required to parse a xml file:-
XML File used:

Python3

Writing an XML File
Writing a xml file is a primitive process, reason for that being the fact that xml files aren’t encoded in a special way. Modifying sections of a xml document requires one to parse through it at first. In the below code we would modify some sections of the aforementioned xml document.
Python3

Using Elementtree
Elementtree module provides us with a plethora of tools for manipulating XML files. The best part about it being its inclusion in the standard Python’s built-in library. Therefore, one does not have to install any external modules for the purpose. Due to the xmlformat being an inherently hierarchical data format, it is a lot easier to represent it by a tree. The module provides ElementTree provides methods to represent whole XML document as a single tree.
In the later examples, we would take a look at discrete methods to read and write data to and from XML files.
Reading XML Files
To read an XML file using ElementTree, firstly, we import the ElementTree class found inside xml library, under the name ET (common convension). Then passed the filename of the xml file to the ElementTree.parse() method, to enable parsing of our xml file. Then got the root (parent tag) of our xml file using getroot(). Then displayed (printed) the root tag of our xml file (non-explicit way). Then displayed the attributes of the sub-tag of our parent tag using root[0].attrib. root[0] for the first tag of parent root and attrib for getting it’s attributes. Then we displayed the text enclosed within the 1st sub-tag of the 5th sub-tag of the tag root.
Python3

Writing XML Files
Now, we would take a look at some methods which could be used to write data on an xml document. In this example we would create a xml file from scratch.
To do the same, firstly, we create a root (parent) tag under the name of chess using the command ET.Element(‘chess’). All the tags would fall underneath this tag, i.e. once a root tag has been defined, other sub-elements could be created underneath it. Then we created a subtag/subelement named Opening inside the chess tag using the command ET.SubElement(). Then we created two more subtags which are underneath the tag Opening named E4 and D4. Then we added attributes to the E4 and D4 tags using set() which is a method found inside SubElement(), which is used to define attributes to a tag. Then we added text between the E4 and D4 tags using the attribute text found inside the SubElement function. In the end we converted the datatype of the contents we were creating from ‘xml.etree.ElementTree.Element’ to bytes object, using the command ET.tostring() (even though the function name is tostring() in certain implementations it converts the datatype to `bytes` rather than `str`). Finally, we flushed the data to a file named gameofsquares.xml which is a opened in `wb` mode to allow writing binary data to it. In the end, we saved the data to our file.