- Saved searches
- Use saved searches to filter your results more quickly
- awbuana/basic-ALPR
- Name already in use
- Sign In Required
- Launching GitHub Desktop
- Launching GitHub Desktop
- Launching Xcode
- Launching Visual Studio Code
- Latest commit
- Git stats
- Files
- README.md
- About
- Распознавание рукописных чисел на Python с использованием OpenCV
- Представление и конфигурация
- Установка OpenCV
- Подготовка к обработке
- Обработка изображений
- Чтение изображения
- Очистка изображения
- Функция распознавания
- Извлечение всех цифр
- Пример использования
Saved searches
Use saved searches to filter your results more quickly
You signed in with another tab or window. Reload to refresh your session. You signed out in another tab or window. Reload to refresh your session. You switched accounts on another tab or window. Reload to refresh your session.
Number Recognition using Python, OpenCV, Keras
awbuana/basic-ALPR
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
Name already in use
A tag already exists with the provided branch name. Many Git commands accept both tag and branch names, so creating this branch may cause unexpected behavior. Are you sure you want to create this branch?
Sign In Required
Please sign in to use Codespaces.
Launching GitHub Desktop
If nothing happens, download GitHub Desktop and try again.
Launching GitHub Desktop
If nothing happens, download GitHub Desktop and try again.
Launching Xcode
If nothing happens, download Xcode and try again.
Launching Visual Studio Code
Your codespace will open once ready.
There was a problem preparing your codespace, please try again.
Latest commit
Git stats
Files
Failed to load latest commit information.
README.md
Number Recognition on License Plate using Python, OpenCV, Keras Data training: MNIST Handwritten digit
python find.py foto/[nama file] 
Menggunakan 2 metode Template Matching dan CNN LeNet
- keras 2.0.8 - opencv-python 3.3.0.10 - numpy 1.13.3 - scipy 1.0.0 - tensorflow 1.2.1 - ubah ke grayscale - apply bilateralfilter - Top-hat transform - thresholding - erotion - crop vertikal lokasi plat nomor dengan Horiozntal Histogram - crop horizontal lokasi plat nomor dengan Vertical Histogram - number segmentation menggunakan contour - crop setiap nomer - masukan ke program template matching atau CNN(Keras) About
Number Recognition using Python, OpenCV, Keras
Распознавание рукописных чисел на Python с использованием OpenCV

Область компьютерного зрения очень увлекательна, и с помощью операций над изображением можно добиться довольно впечатляющих результатов.
Найти ответ на вычисление типа 3847*7943 относительно просто, при условии, что вас зовут “Человек дождя”.
Поскольку часто это не так, мы склонны обращаться к машине (калькулятору, компьютеру, смартфону и т.д.), которая способна сделать это почти мгновенно.
С другой стороны, нам очень легко определить по фотографии, что там находится. В этой плане компьютеру приходится гораздо труднее, чем при вычислениях.
В этой статье мы покажем вам довольно “базовый” подход (со своими ограничениями, без нейронных сетей и только на центральном процессоре), позволяющий компьютеру “видеть”.
Представление и конфигурация
OpenCV (для Open Computer Vision) – это бесплатная графическая библиотека, специализирующаяся на обработке изображений в реальном времени. Она содержит более 2500 алгоритмов, оптимизированных для этого.
Установка OpenCV
Я компилировал из исходников версии 4.2.0, но вам не обязательно делать то же самое. Поэтому я предлагаю простой метод – сделать это с помощью pip.
Этот метод довольно быстрый, но предварительно убедитесь, что pip у вас установлен.
python3 -m pip install --user -U opencv-python opencv-contrib-python
Подготовка к обработке
Прежде чем мы начнем писать алгоритм, который позволит компьютеру распознать число, мы должны подготовить что-то, что он сможет распознать, когда ему его дадут. Для этого давайте начнем с набора изображений цифр 0-9.
Выполним эту операцию с помощью функции getTextSize(), которая позволит нам узнать размер изображения, необходимого для каждой цифры.
Эта функция принимает 4 параметра:
- text: в нашем случае это будут цифры от 0 до 9;
- fontFace: начертание текста, список возможных значений здесь ;
- fontScale: коэффициент масштабирования шрифта, который умножается на базовый размер шрифта.;
- thickness : толщина линии рисунка.
Давайте создадим файл digit.py и с помощью функции putText() начнем генерировать наши изображения:
Code language: JavaScript (javascript)#!/usr/bin/env python3 import cv2 import numpy as np SCALE = 3 THICK = 5 WHITE = (255, 255, 255) digits = [] for digit in map(str, range(10)): (width, height), bline = cv2.getTextSize(digit, cv2.FONT_HERSHEY_SIMPLEX, SCALE, THICK) digits.append(np.zeros((height + bline, width), np.uint8)) cv2.putText(digits[-1], digit, (0, height), cv2.FONT_HERSHEY_SIMPLEX, SCALE, WHITE, THICK) x0, y0, w, h = cv2.boundingRect(digits[-1]) digits[-1] = digits[-1][y0:y0+h, x0:x0+w] cv2.imshow(digit, digits[-1])
Теперь наш список цифр содержит 10 изображений чисел от 0 до 9:

Позже мы сможем использовать эти образцы для сравнения со своим почерком.
Обработка изображений
Теперь мы перейдем к обработке изображений. Цель состоит в том, чтобы взять изображение, извлечь присутствующие на нем фигуры и сравнить их с теми, которые были созданы в первой части.
Для теста используется следующее изображение:
Чтение изображения
Первый шаг – загрузить изображение и преобразовать его в черно-белое, поскольку в нашем случае цвет не имеет значения и даже может быть помехой. Это наша первая обработка.
Необходимо придерживаться файла digit.py:
Code language: JavaScript (javascript)color_test_image = cv2.imread('/test/image.png', cv2.IMREAD_COLOR) gray_test_image = cv2.cvtColor(color_test_image, cv2.COLOR_BGR2GRAY) cv2.imshow('test_image', gray_test_image)
У вас должно получиться следующее:

Очистка изображения
Поскольку мы хотим извлечь только числа из нашей начальной картинки, мы выполним некоторую обработку с помощью бинарного порога, чтобы выделить числа. Цифры написаны черными чернилами на белой бумаге, но те, которые мы сгенерировали, написаны белым цветом на черном фоне.
Поэтому мы будем использовать то же поведение, что и в первой части, благодаря функции threshold(), которая также принимает 4 параметра:
- src : исходное изображение (test_image) ;
- thresh : пороговое значение;
- maxval : максимальное значение для использования с THRESH_BINARY и THRESH_BINARY_INV ;
- type : тип порога, который будет использоваться (список типов здесь).
Поэтому мы можем написать:
Code language: PHP (php)# выполняем обратное бинарное пороговое выделение, чтобы цифры выделялись белым на черном ret, thresh = cv2.threshold(gray_test_image, 170, 255, cv2.THRESH_BINARY_INV)
Теперь изображение должно выглядеть следующим образом:

Использование черно-белых изображений интересно еще и тем, что ими можно управлять как булевыми массивами (0 черный, 1 белый); поэтому мы можем использовать логические операции (AND, OR, XOR, NAND…) для поиска наибольшего соответствия.
Функция распознавания
Целью будет сравнить изображение и сопоставить его с нашими ранее сгенерированными известными фигурами.
Сопоставление:
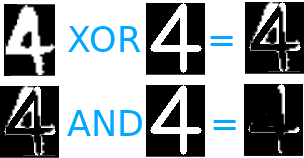
Чем больше контрольная цифра стерта, тем выше будет совпадение. Вот почему мы начинаем с XOR (или исключения) наших двух изображений.
XOR будет иметь эффект сохранения того, что не является общим между двумя данными.
После этого мы можем выполнить И (и логическое), которое даст нам изображение, содержащее только ту часть, которая не покрыта нашей записанной цифрой.
Чем слабее эта часть, тем более “надежным” является распознавание.
Например.
Если 4 элемент управления содержит 400 белых пикселей, а после XOR и AND он содержит только 74, мы можем сделать следующий расчет 100 – (74 / 400 * 100), что дает 81% соответствия.
Code language: PHP (php)def detect(img): # сравниваем полученную цифру с нашей базой percent_white_pix = 0 digit = -1 for i, d in enumerate(digits): scaled_img = cv2.resize(img, d.shape[:2][::-1]) # d AND (scaled_img XOR d) bitwise = cv2.bitwise_and(d, cv2.bitwise_xor(scaled_img, d)) # результат определяется наибольшей потерей белых пикселей before = np.sum(d == 255) matching = 100 - (np.sum(bitwise == 255) / before * 100) #cv2.imshow('digit_%d' % (9-i), bitwise) if percent_white_pix < matching: percent_white_pix = matching digit = i return digit
Извлечение всех цифр
Найдем все контуры, сделанные ручкой, затем сравним каждое изображение с контрольными и напишем обнаружение на цветном.
Code language: PHP (php)# находим контуры порогового изображения contours, hierarchy = cv2.findContours(thresh, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
Теперь у нас есть все контуры нашей записи, мы можем выделить каждое число, чтобы сравнить их:
Code language: PHP (php)for cnt in contours: # проверяется размер контура, чтобы избежать обработки "дефекта". if cv2.contourArea(cnt) > 30: # получаем прямоугольник, окружающий число brect = cv2.boundingRect(cnt) x,y,w,h = brect roi = thresh[y:y+h, x:x+w] # определение digit = detect(roi) cv2.rectangle(color_test_image, brect, (0,255,0), 2) cv2.putText(color_test_image, str(digit), (x, y), cv2.FONT_HERSHEY_SIMPLEX, 1, (190, 123, 68), 2) cv2.imshow('resultat', color_test_image) cv2.waitKey(0) cv2.destroyAllWindows()
Берем каждую извлеченную цифру, сравниваем ее с нашими тестовыми изображениями и возвращаем только самое лучшее совпадение.

Мы получаем 80% успеха, что не так уж плохо. В зависимости от того, как вы пишете, вы можем получить очень разный процент успеха.
Алгоритм в цикле
При копировании и вставке приведенного выше кода не всегда очевидно, что происходит.
Наглядное изображение стоит тысячи слов:

Каждое число в извлеченной картинке сравнивается со всеми остальными следующим образом:
- XOR изображения обнаруженной цифры с контрольной цифрой;
- Результат XOR с контрольным числом;
- Сравнивается количество белых пикселей на контрольной цифре до и после;
- Если процент стирания/восстановления контрольного разряда выше, чем предыдущего, то он преобразуется.
Разброс в успешности результатов может быть обусловлен несколькими факторами, такими как качество фотографии, качество письма, ориентация изображения и т.д. Однако если вы хотите применить тот же процесс к фотографии, содержащей напечатанные цифры, вы должны получить более устойчивые результаты (если шрифт не слишком отличается от того, который был создан в первой части).
Пример использования
Распознавание одного числа может показаться незначительным результатом, но не стесняйтесь адаптировать и улучшать этот пример алгоритма.
Используя точно такую же логику, можно извлечь игральные карты из изображения и определить их достоинство и символ (♥, ♠, ♦ и ♣). Очевидно, с теми же недостатками, что описаны выше, но вы можете получить результат, схожий с этим:

Единственной ошибкой обнаружения на этом изображении является знак 🂪 в правом верхнем углу. При таком подходе очень трудно получить 100%, но всегда интересно увидеть методы, которые человек может легко понять, что далеко не так при использовании нейронных сетей, которые делают для нас метод “непрозрачным”.
Если вы хотите начать, я советую вам начать с простых примеров (обнаружение чисел), чтобы затем усложнять их и прийти, как в примере выше, к обнаружению более сложных элементов, таких как игральные карты.
Этот метод, очевидно, имеет свои ограничения, которые становятся очевидными довольно быстро.
Действительно, для фигур, где вопрос неоднозначности не возникает, решение довольно хорошее. Но для других чисел, в зависимости от того, как мы привыкли формировать наши числа, иногда может показаться, что это просто не работает.