- [Solved] Python SyntaxError: (unicode error) ‘unicodeescape’ codec can’t decode bytes in position 0-5: truncated \UXXXXXXXX escape
- SyntaxError Example
- Solutions
- Solution 1: Add a “r” character in the beginning of string.
- Solution 2: Change \ to be / .
- Solution 3: Change \ to be \ .
- Reference
- Read More
- Share this:
- Python unicode error unicode escape
- # SyntaxError: (unicode error) ‘unicodeescape’ codec can’t decode bytes in position 2-3: truncated \ UXXXXXXXX escape
- # Prefix the string with r to mark it as a raw string
- # Escape the backslash with a second backslash character
- # Using forward slashes instead of backslashes in paths
- # The 3 possible solutions to the error
- Python SyntaxError: (unicode error) ‘unicodeescape’ codec can’t decode bytes in position 2-3: truncated \UXXXXXXXX escape
- Step #1: How to solve SyntaxError: (unicode error) ‘unicodeescape’ — Double slashes for escape characters
- Step #2: Use raw strings to prevent SyntaxError: (unicode error) ‘unicodeescape’
- Step #3: Slashes for file paths -SyntaxError: (unicode error) ‘unicodeescape’
- Step #4: PyCharm — SyntaxError: (unicode error) ‘unicodeescape’ codec can’t decode bytes in position 2-3: truncated \UXXXXXXXX escape
[Solved] Python SyntaxError: (unicode error) ‘unicodeescape’ codec can’t decode bytes in position 0-5: truncated \UXXXXXXXX escape
The following error message is a common Python error, the “SyntaxError” represents a Python syntax error and the “unicodeescape” means that we made a mistake in using unicode escape character.
SyntaxError: (unicode error) 'unicodeescape' codec can't decode bytes in position 0-5: truncated \UXXXXXXXX escapeSimply to put, the “SyntaxError” can be occurred accidentally in Python and it is often happens because the \ (ESCAPE CHARACTER) is misused in a python string, it caused the unicodeescape error.
(Note: “escape character” can convert your other character to be a normal character.)
SyntaxError Example
Looks like we want to print “It’s a nice day.“, right? But the program will report an error message.
File "", line 1 print('It's a nice day.') ^ SyntaxError: invalid syntaxThe reason is very easy-to-know. In Python, we can use print(‘xxx’) to print out xxx. But in our code, if we had used the ‘ character, the Python interpreter will misinterpret the range of our characters so it will report an error.
To solve this problem, we need to add an escape character “\” to convert our ‘ character to be a normal character, not a superscript of string.
So how did the syntax error happen? Let me talk about my example:
One day, I run my program for experiment, I saved some data in a csv file. In order for this file can be viewed on the Windows OS, I add a new code \uFFEF in the beginning of file.
This is “BOM” (Byte Order Mark), Explain to the system that the file format is “Big-Ending“.
SyntaxError: (unicode error) 'unicodeescape' codec can't decode bytes in position 0-5: truncated \UXXXXXXXX escapeAs mentioned at the beginning of this article, this is an escape character error in Python.
Solutions
There are three solutions you can try:
Solution 1: Add a “r” character in the beginning of string.
After we adding a r character at right side of python string, it means a complete string not anything else.
Solution 2: Change \ to be / .
open("C:\Users\Clay\Desktop\test.txt")open("C:/Users/Clay/Desktop/test.txt")This way is avoid to use escape character.
Solution 3: Change \ to be \\ .
open("C:\Users\Clay\Desktop\test.txt")open("C:\\Users\\Clay\\Desktop\\test.txt")It is similar to the solution 2 that it also avoids the use of escape characters.
The above are three common solutions. We can run normally on Windows.
Reference
Read More
Share this:
Python unicode error unicode escape
SyntaxError: (unicode error) ‘unicodeescape’ codec can’t decode bytes in position 2-3: truncated \UXXXXXXXX escape
Last updated: Feb 17, 2023
Reading time · 3 min

# SyntaxError: (unicode error) ‘unicodeescape’ codec can’t decode bytes in position 2-3: truncated \ UXXXXXXXX escape
The Python «SyntaxError: (unicode error) ‘unicodeescape’ codec can’t decode bytes in position» occurs when we have an unescaped backslash character in a path.
To solve the error, prefix the path with r to mark it as a raw string, e.g. r’C:\Users\Bob\Desktop\example.txt’ .
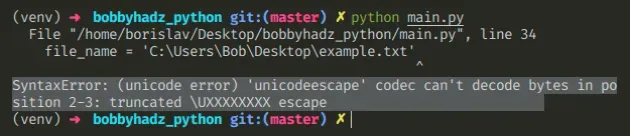
Copied!File "/home/borislav/Desktop/bobbyhadz_python/main.py", line 2 file_name = 'C:\Users\Bob\Desktop\example.txt' ^ SyntaxError: (unicode error) 'unicodeescape' codec can't decode bytes in position 2-3: truncated \UXXXXXXXX escape
Here is an example of how the error occurs.
Copied!# ⛔️ SyntaxError: (unicode error) 'unicodeescape' codec can't decode bytes in position 2-3: truncated \UXXXXXXXX escape file_name = 'C:\Users\Bob\Desktop\example.txt' with open(file_name, 'r', encoding='utf-8') as f: lines = f.readlines() print(lines)
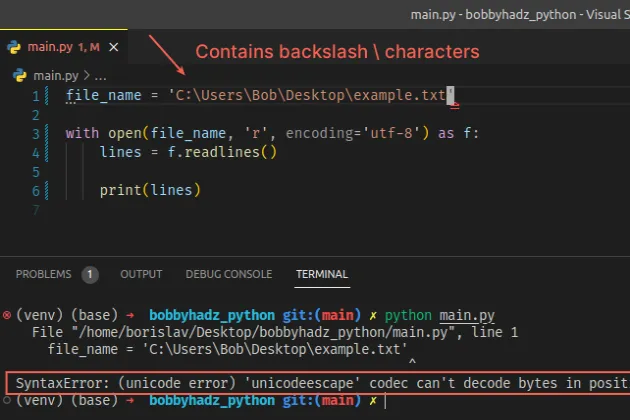
The path contains backslash characters which is the cause of the error.
The backslash \ character has a special meaning in Python. It is used as an escape character (e.g. \n or \t ).
# Prefix the string with r to mark it as a raw string
One way to solve the error is to prefix the string with the letter r to mark it as a raw string.
Copied!# ✅ prefix string with r file_name = r'C:\Users\Bob\Desktop\example.txt' with open(file_name, 'r', encoding='utf-8') as f: lines = f.readlines() print(lines)
If the error persists, try to use a triple-quoted raw string instead.
Copied!# ✅ wrapped raw string in triple quotes file_name = r'''C:\Users\Bob\Desktop\example.txt''' with open(file_name, 'r', encoding='utf-8') as f: lines = f.readlines() print(lines)
You might also use the open() function directly, without the with statement.
Copied!file_name = r'C:\Users\Bob\Desktop\example.txt' my_file = open(file_name, 'r', encoding='utf-8') lines = my_file.readlines() print(lines) my_file.close()
Prefixing the string with r works either way.
# Escape the backslash with a second backslash character
An alternative way to treat a backslash \ as a literal character is to escape it with a second backslash \\ .
Copied!# ✅ escape each backslash with a second backslash file_name = 'C:\\Users\\Bob\\Desktop\\example.txt' with open(file_name, 'r', encoding='utf-8') as f: lines = f.readlines() print(lines)
We escaped each backslash character to treat them as literal backslashes.
Here is a string that shows how 2 backslashes only get translated into 1.
Copied!my_str = 'bobby\\hadz' print(my_str) # 👉️ "bobby\hadz"
Similarly, if you need to have 2 backslashes next to one another, you would have to use 4 backslashes.
Copied!my_str = 'bobby\\\\hadz\\\\com' print(my_str) # 👉️ "bobby\\hadz\\com"
# Using forward slashes instead of backslashes in paths
An alternative solution to the error is to use forward slashes in the path instead of backslashes.
Copied!# ✅ using forward slashes instead of backslashes file_name = 'C:/Users/Bob/Desktop/example.txt' with open(file_name, 'r', encoding='utf-8') as f: lines = f.readlines() print(lines)
A forward slash can be used in place of a backslash when you need to specify a path.
This solves the error because we no longer have any unescaped backslash characters in the path.
The error occurs because the \U character in the path is a Unicode code point.
Copied!file_name = 'C:\Users\Bob\Desktop\example.txt'
If the 8 characters after \U are not numeric an error is raised.
Since backslash characters have a special meaning in Python, we need to treat them as a literal character by:
- prefixing the string with r to mark it as a raw string
- escaping each backslash with a second backslash
- using forward slashes in place of backslashes in the path
# The 3 possible solutions to the error
Here are the 3 possible solutions to the error.
Copied!# ✅ prefix string with r file_name = r'C:\Users\Bob\Desktop\example.txt' # ✅ escaping each backslash with another backslash file_name = 'C:\\Users\\Bob\\Desktop\\example.txt' # ✅ using forward slashes instead of backslashes file_name = 'C:/Users/Bob/Desktop/example.txt'
If none of the suggestions works, try to use a triple-quoted raw string.
Copied!file_name = r'''C:\Users\Bob\Desktop\example.txt'''
The backslash ( \ ) character is used to escape characters that otherwise have a special meaning, such as newline, backslash itself, or the quote character.
Unless the string is prefixed with an r , escape sequences are interpreted as follows:
| Escape Sequence | Meaning |
|---|---|
| Backslash and newline ignored | |
| \ | Backslash ( \ ) |
| \’ | Single quote ( ‘ ) |
| \» | Double quote ( » ) |
| \n | ASCII Linefeed |
| \r | ASCII Carriage Return |
| \t | ASCII Horizontal Tab |
A backslash is also used as a continuation character.
Copied!my_str = 'first \ second \ third' print(my_str) # first second third
When a backslash is added at the end of a line, the newline is ignored.
I wrote a book in which I share everything I know about how to become a better, more efficient programmer.
Python SyntaxError: (unicode error) ‘unicodeescape’ codec can’t decode bytes in position 2-3: truncated \UXXXXXXXX escape
While this error can appear in different situations the reason for the error is one and the same:
- there are special characters( escape sequence — characters starting with backslash — » ).
- From the error above you can recognize that the culprit is ‘\U’ — which is considered as unicode character.
- another possible errors for SyntaxError: (unicode error) ‘unicodeescape’ will be raised for ‘\x’, ‘\u’
- codec can’t decode bytes in position 2-3: truncated \xXX escape
- codec can’t decode bytes in position 2-3: truncated \uXXXX escape
Step #1: How to solve SyntaxError: (unicode error) ‘unicodeescape’ — Double slashes for escape characters
Let’s start with one of the most frequent examples — windows paths. In this case there is a bad character sequence in the string:
import json json_data=open("C:\Users\test.txt").read() json_obj = json.loads(json_data)The problem is that \U is considered as a special escape sequence for Python string. In order to resolved you need to add second escape character like:
import json json_data=open("C:\\Users\\test.txt").read() json_obj = json.loads(json_data)Step #2: Use raw strings to prevent SyntaxError: (unicode error) ‘unicodeescape’
If the first option is not good enough or working then raw strings are the next option. Simply by adding r (for raw string literals) to resolve the error. This is an example of raw strings:
import json json_data=open(r"C:\Users\test.txt").read() json_obj = json.loads(json_data)If you like to find more information about Python strings, literals
In the same link we can find:
When an r’ or R’ prefix is present, backslashes are still used to quote the following character, but all backslashes are left in the string. For example, the string literal r»\n» consists of two characters: a backslash and a lowercase `n’.
Step #3: Slashes for file paths -SyntaxError: (unicode error) ‘unicodeescape’
Another possible solution is to replace the backslash with slash for paths of files and folders. For example:
Since python can recognize both I prefer to use only the second way in order to avoid such nasty traps. Another reason for using slashes is your code to be uniform and homogeneous.
Step #4: PyCharm — SyntaxError: (unicode error) ‘unicodeescape’ codec can’t decode bytes in position 2-3: truncated \UXXXXXXXX escape
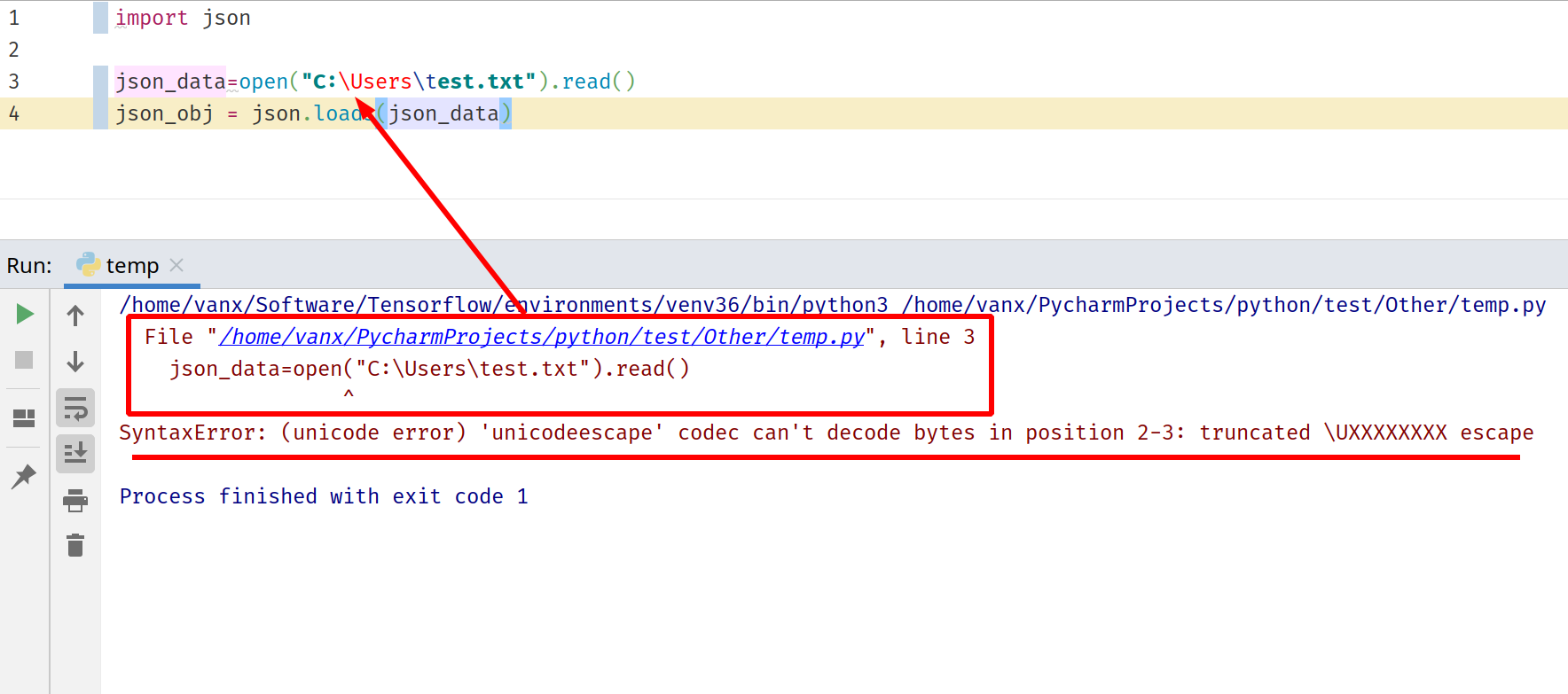
The picture below demonstrates how the error will look like in PyCharm. In order to understand what happens you will need to investigate the error log.

The error log will have information for the program flow as:
/home/vanx/Software/Tensorflow/environments/venv36/bin/python3 /home/vanx/PycharmProjects/python/test/Other/temp.py File "/home/vanx/PycharmProjects/python/test/Other/temp.py", line 3 json_data=open("C:\Users\test.txt").read() ^ SyntaxError: (unicode error) 'unicodeescape' codec can't decode bytes in position 2-3: truncated \UXXXXXXXX escapeYou can see the latest call which produces the error and click on it. Once the reason is identified then you can test what could solve the problem.
By using SoftHints — Python, Linux, Pandas , you agree to our Cookie Policy.
- another possible errors for SyntaxError: (unicode error) ‘unicodeescape’ will be raised for ‘\x’, ‘\u’