- Обработка ошибок в Python
- Назначение исключений
- Примеры исключений
- Python try except timeout
- # (Python) ConnectionError: Max retries exceeded with url
- # Using a Retry object to retry with a back off
- # Using a try/except statement to not retry when an error occurs
- # Disable SSL certificate validation
- # Using the time.sleep() method to implement a delay between requests
- # Try setting headers to simulate a browser
- # Repeating the requests until a successful response
- # Conclusion
Обработка ошибок в Python
Исключения являются событиями, способными изменить ход выполнения программы, они позволяют перепрыгнуть через фрагмент программы произвольной длины. Исключения в языке Python возбуждаются автоматически, когда программный код допускает ошибку, а также могут возбуждаться и перехватываться самим программным кодом. Обрабатываются исключения четырьмя инструкциями.
try/except — перехватывает исключения, возбужденные интерпретатором или вашим программным кодом, и выполняет восстановительные операции.
try/finally выполняет заключительные операции независимо от того, возникло исключение или нет.
raise — дает возможность возбудить исключение программно.
assert — дает возможность возбудить исключение программно, при выполнении определенного условия.
Благодаря исключениям программа может перейти к обработчику исключения за один шаг, отменив все вызовы функций. Обработчик исключений (инструкция try ) ставит метку и выполняет некоторый программный код. Если затем где-нибудь в программе возникает исключение, интерпретатор немедленно возвращается к метке, отменяя все активные вызовы функций, которые были произведены после установки метки.
Назначение исключений
- Обработка ошибок. Интерпретатор возбуждает исключение всякий раз, когда обнаруживает ошибку во время выполнения программы. Программа может перехватывать такие ошибки и обрабатывать их или просто игнорировать. Если ошибка игнорируется, интерпретатор выполняет действия, предусмотренные по умолчанию, – он останавливает выполнение программы и выводит сообщение об ошибке. Если такое поведение по умолчанию является нежелательным, можно добавить инструкцию try, которая позволит перехватывать обнаруженные ошибки и продолжить выполнение программы после инструкции try.
- Уведомления о событиях Исключения могут также использоваться для уведомления о наступлении некоторых условий, что устраняет необходимость передавать куда-либо флаги результата или явно проверять их. Например, функция поиска может возбуждать исключение в случае неудачи, вместо того чтобы возвращать целочисленный признак в виде результата (и надеяться, что этот признак всегда будет интерпретироваться правильно).
- Обработка особых ситуаций. Некоторые условия могут наступать так редко, что было бы слишком расточительно предусматривать проверку наступления таких условий с целью их обработки. Нередко такие проверки необычных ситуаций можно заменить обработчиками исключений.
- Заключительные операции. Как будет показано далее, инструкция try/finally позволяет гарантировать выполнение завершающих операций независимо от наличия исключений.
- Необычное управление потоком выполнения. И, наконец, так как исключения – это своего рода оператор «goto», их можно использовать как основу для экзотического управления потоком выполнения программы.
Примеры исключений
Предположим, что у нас имеется следующая функция:
Python try except timeout
Last updated: Feb 17, 2023
Reading time · 5 min

# (Python) ConnectionError: Max retries exceeded with url
The error «ConnectionError: Max retries exceeded with url» occurs for multiple reasons:
- An incorrect or incomplete URL has been passed to the request.get() method.
- You are being rate-limited by the API.
- requests is unable to verify the SSL certificate of the site to which you’re making a request.
Make sure that you’ve specified the correct and complete URL and path.
Copied!# ⛔️ doesn't specify the protocol (https://) example.com/posts # ✅ an example of a complete URL https://example.com/posts
Double-check that you haven’t made any typos in the URL and path.
# Using a Retry object to retry with a back off
One way to solve the error is to use a Retry object and specify how many connection-related errors to retry on and set a back-off factor to apply between attempts.
Copied!import requests from requests.adapters import HTTPAdapter, Retry def make_request(): session = requests.Session() retry = Retry(connect=3, backoff_factor=0.5) adapter = HTTPAdapter(max_retries=retry) session.mount('http://', adapter) session.mount('https://', adapter) url = 'https://reqres.in/api/users' response = session.get(url) parsed = response.json() print(parsed) make_request()
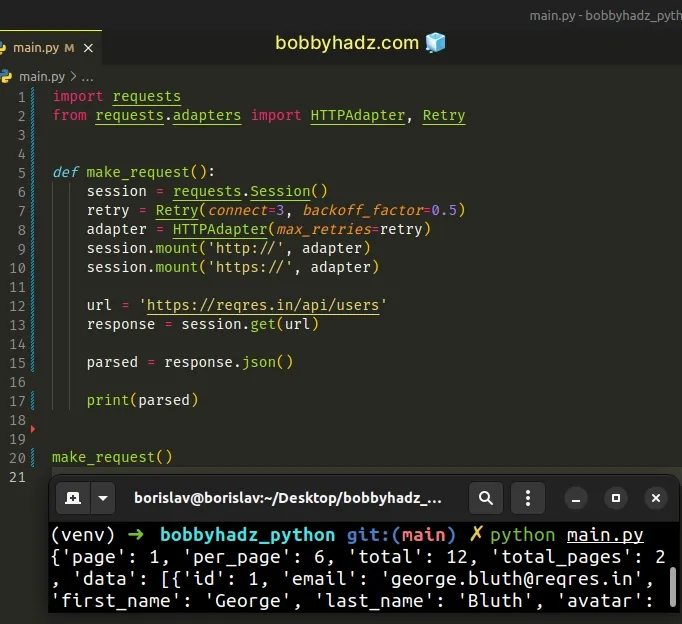
The Session object allows us to persist certain parameters across requests.
We passed the following keyword arguments to the Retry object:
- connect — the number of connection-related errors to retry on
- backoff_factor — a back-off factor to apply between attempts after the second try.
The example above retries the request 3 times with a back-off factor of 0.5 seconds after the second try.
# Using a try/except statement to not retry when an error occurs
You can also use a try/except block if you don’t want to retry when an error occurs.
Copied!import requests def make_request(): try: url = 'https://reqres.in/api/users' response = requests.get(url, timeout=30) parsed = response.json() print(parsed) except requests.exceptions.ConnectionError: # 👇️ handle error here or use a `pass` statement print('connection error occurred') make_request()
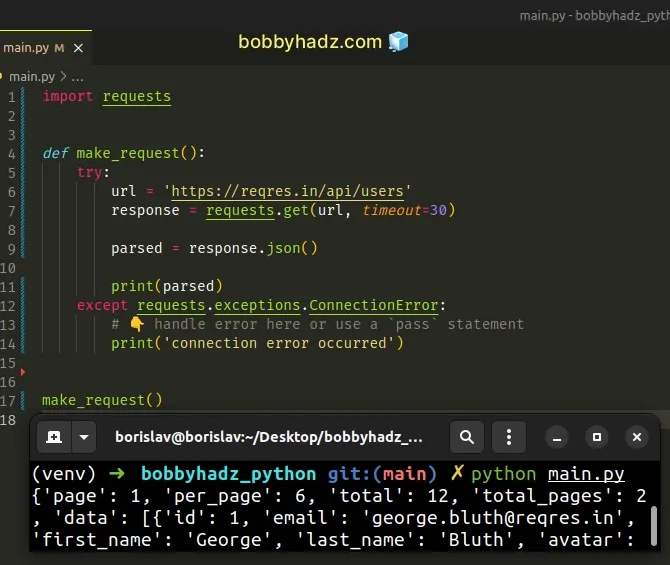
The except block will run if a connection error is raised in the try block.
# Disable SSL certificate validation
If you got the error because requests was unable to verify the SSL certificate of the site, set the verify keyword argument to False to disable the SSL certificate validation for the request.
Note that you should only disable SSL certificate validation during local development or testing as it could make your application vulnerable to man-in-the-middle attacks.
Copied!import requests def make_request(): try: url = 'https://reqres.in/api/users' # 👇️ set verify to False response = requests.get(url, verify=False, timeout=30) parsed = response.json() print(parsed) except Exception as e: print(e) make_request()
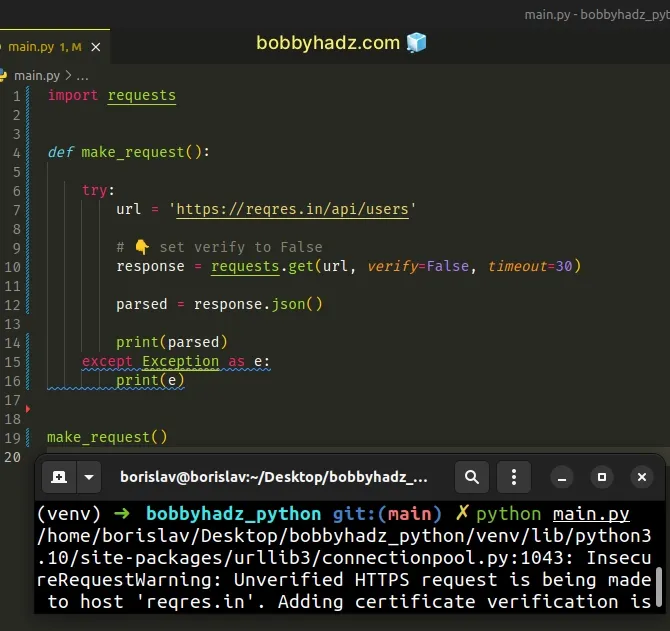
The code sample sets the verify keyword arguments to False which disables SSL certificate validation.
Copied!response = requests.get(url, verify=False, timeout=30)
# Using the time.sleep() method to implement a delay between requests
An alternative solution would be to use the time.sleep() method to set a certain delay between the requests.
The API might be throttling your requests which may not happen with a delay.
Copied!from time import sleep import requests def make_request(): try: url = 'https://reqres.in/api/users' response = requests.get(url, timeout=30) parsed = response.json() print(parsed['data'][0]) except requests.exceptions.ConnectionError: # 👇️ handle error here or use a `pass` statement print('connection error occurred') for i in range(3): make_request() sleep(1.5)
The time.sleep method suspends execution for the given number of seconds.
The code sample makes 3 requests to the API with a delay of 1.5 seconds.
# Try setting headers to simulate a browser
If the error persists, try setting headers to simulate a browser.
Copied!import requests def make_request(): try: url = 'https://reqres.in/api/users' headers = 'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.111 Safari/537.36' > response = requests.get(url, headers=headers, timeout=10) print(response.content) parsed = response.json() print(parsed) except requests.exceptions.ConnectionError: print('Connection error occurred') make_request()
We set the User-Agent header to simulate a browser.
There is also a third-party module called fake-useragent that you can use to fake a browser.
You can run the following command to install the module.
Copied!pip install fake-useragent # 👇️ or with pip3 pip3 install fake-useragent
Now you can import and use the fake-useragent module.
Copied!from fake_useragent import UserAgent import requests def make_request(): ua = UserAgent() print(ua.chrome) header = 'User-Agent': str(ua.chrome)> try: url = 'https://reqres.in/api/users' response = requests.get(url, headers=header, timeout=10) print(response.content) parsed = response.json() print(parsed) except requests.exceptions.ConnectionError: print('Connection error occurred') make_request()
Here are some of the commonly used user agents.
Copied!from fake_useragent import UserAgent ua = UserAgent() # Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.13 (KHTML, like Gecko) Chrome/24.0.1290.1 Safari/537.13 print(ua.chrome) # Mozilla/2.0 (compatible; MSIE 3.0; Windows 3.1) print(ua.ie) # Mozilla/5.0 (Windows NT 5.0; rv:21.0) Gecko/20100101 Firefox/21.0 print(ua.firefox) # Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_3) AppleWebKit/537.75.14 (KHTML, like Gecko) Version/7.0.3 Safari/7046A194A print(ua.safari)
# Repeating the requests until a successful response
You can also use a while loop to repeat the request until the server responds.
Copied!from time import sleep import requests response = None while response is None: try: url = 'https://reqres.in/api/users' response = requests.get(url, timeout=30) break except: print('Connection error occurred') sleep(1.5) continue print(response) parsed = response.json() print(parsed)
We used a while loop to make a request every 1.5 seconds until the server responds without a connection error.
The try statement tries to make an HTTP request to the API and if the request fails, the except block runs where we suspend execution for 1.5 seconds.
The continue statement is used to continue to the next iteration of the while loop.
The process is repeated until the HTTP request is successful and the break statement is used.
You can also be more specific in the error-handling portion of the code.
Copied!from time import sleep import requests response = None while response is None: try: url = 'https://reqres.in/api/users' response = requests.get(url, timeout=30) break except requests.ConnectionError as e: print('Connection error occurred', e) sleep(1.5) continue except requests.Timeout as e: print('Timeout error - request took too long', e) sleep(1.5) continue except requests.RequestException as e: print('General error', e) sleep(1.5) continue except KeyboardInterrupt: print('The program has been canceled') print(response) parsed = response.json() print(parsed)
The requests.ConnectionError error means that there are connectivity issues, either on our site or on the server.
Check your internet connection and make sure the server has access to the internet.
The requests.Timeout error is raised when the request takes too long (more than 30 seconds in the example).
The requests.RequestException error is a general, catch-all error.
The KeyboardInterrupt exception is raised when the user cancels the program, e.g. by pressing CTRL + C .
# Conclusion
To solve the error «ConnectionError: Max retries exceeded with url», make sure:
- To specify the correct and complete URL in the call to request.get() .
- You aren’t being rate-limited by the API.
- The requests module is able to verify the SSL certificate of the site.
- You have access to the internet.
I wrote a book in which I share everything I know about how to become a better, more efficient programmer.