- Extract a substring from a string in Python (position, regex)
- Extract a substring by specifying the position and number of characters
- Extract a character by index
- Extract a substring by slicing
- Extract based on the number of characters
- Extract a substring with regular expressions: re.search() , re.findall()
- Regex pattern examples
- Wildcard-like patterns
- Greedy and non-greedy
- Extract part of the pattern with parentheses
- Match any single character
- Match the start/end of the string
- Extract by multiple patterns
- Case-insensitive
- Python Substring After Character
- How to Get Substring After Character in Python?
- Method 1: Get Substring After Character in Python Using “split()” Method
- Example
- Method 2: Get Substring After Character in Python Using “partition()” Method
- Example
- Method 3: Get Substring After Character in Python Using “index()” Method
- Example
- Method 4: Substring After Character in Python Utilizing “find()” Method
- Example
- Conclusion
- About the author
- Maria Naz
Extract a substring from a string in Python (position, regex)
This article explains how to extract a substring from a string in Python. You can extract a substring by specifying its position and length, or by using regular expression patterns.
- Extract a substring by specifying the position and number of characters
- Extract a character by index
- Extract a substring by slicing
- Extract based on the number of characters
- Wildcard-like patterns
- Greedy and non-greedy
- Extract part of the pattern with parentheses
- Match any single character
- Match the start/end of the string
- Extract by multiple patterns
- Case-insensitive
To search a string to get the position of a given substring or replace a substring in a string with another string, see the following articles.
If you want to extract from a text file, read the file as a string.
Extract a substring by specifying the position and number of characters
Extract a character by index
You can get a character at the desired position by specifying an index in [] . Indexes start at 0 (zero-based indexing).
s = 'abcde' print(s[0]) # a print(s[4]) # eYou can specify a backward position with negative values. -1 represents the last character.
An error is raised if the non-existent index is specified.
# print(s[5]) # IndexError: string index out of range # print(s[-6]) # IndexError: string index out of rangeExtract a substring by slicing
s = 'abcde' print(s[1:3]) # bc print(s[:3]) # abc print(s[1:]) # bcdeYou can also use negative values.
print(s[-4:-2]) # bc print(s[:-2]) # abc print(s[-4:]) # bcdeIf start > end , no error is raised, and an empty string » is extracted.
print(s[3:1]) # print(s[3:1] == '') # TrueOut-of-range values are ignored.
In addition to the start position start and end position stop , you can also specify an increment step using the syntax [start:stop:step] . If step is negative, the substring will be extracted in reverse order.
print(s[1:4:2]) # bd print(s[::2]) # ace print(s[::3]) # ad print(s[::-1]) # edcba print(s[::-2]) # ecaFor more information on slicing, see the following article.
Extract based on the number of characters
The built-in function len() returns the number of characters in a string. You can use this to get the central character or extract the first or second half of the string using slicing.
Note that you can specify only integer int values for index [] and slice [:] . Division by / raises an error because the result is a floating-point number float .
The following example uses integer division // which truncates the decimal part of the result.
s = 'abcdefghi' print(len(s)) # 9 # print(s[len(s) / 2]) # TypeError: string indices must be integers print(s[len(s) // 2]) # e print(s[:len(s) // 2]) # abcd print(s[len(s) // 2:]) # efghiExtract a substring with regular expressions: re.search() , re.findall()
You can use regular expressions with the re module of the standard library.
Use re.search() to extract a substring matching a regular expression pattern. Specify the regular expression pattern as the first parameter and the target string as the second parameter.
import re s = '012-3456-7890' print(re.search(r'\d+', s)) #In regular expressions, \d matches a digit character, while + matches one or more repetitions of the preceding pattern. Therefore, \d+ matches one or more consecutive digits.
Since backslash \ is used in regular expression special sequences such as \d , it is convenient to use a raw string by adding r before » or «» .
When a string matches the pattern, re.search() returns a match object. You can get the matched part as a string str by the group() method of the match object.
m = re.search(r'\d+', s) print(m.group()) # 012 print(type(m.group())) #For more information on regular expression match objects, see the following article.
As shown in the example above, re.search() returns the match object for the first occurrence only, even if there are multiple matching parts in the string.
re.findall() returns a list of all matching substrings.
print(re.findall(r'\d+', s)) # ['012', '3456', '7890']Regex pattern examples
This section provides examples of regular expression patterns using metacharacters and special sequences.
Wildcard-like patterns
. matches any single character except a newline, and * matches zero or more repetitions of the preceding pattern.
For example, a.*b matches the string starting with a and ending with b . Since * matches zero repetitions, it also matches ab .
print(re.findall('a.*b', 'axyzb')) # ['axyzb'] print(re.findall('a.*b', 'a---b')) # ['a---b'] print(re.findall('a.*b', 'aあいうえおb')) # ['aあいうえおb'] print(re.findall('a.*b', 'ab')) # ['ab']+ matches one or more repetitions of the preceding pattern. a.+b does not match ab .
print(re.findall('a.+b', 'ab')) # [] print(re.findall('a.+b', 'axb')) # ['axb'] print(re.findall('a.+b', 'axxxxxxb')) # ['axxxxxxb']? matches zero or one preceding pattern. In the case of a.?b , it matches ab and the string with only one character between a and b .
print(re.findall('a.?b', 'ab')) # ['ab'] print(re.findall('a.?b', 'axb')) # ['axb'] print(re.findall('a.?b', 'axxb')) # []Greedy and non-greedy
* , + , and ? are greedy matches, matching as much text as possible. In contrast, *? , +? , and ?? are non-greedy, minimal matches, matching as few characters as possible.
s = 'axb-axxxxxxb' print(re.findall('a.*b', s)) # ['axb-axxxxxxb'] print(re.findall('a.*?b', s)) # ['axb', 'axxxxxxb']Extract part of the pattern with parentheses
If you enclose part of a regular expression pattern in parentheses () , you can extract a substring in that part.
print(re.findall('a(.*)b', 'axyzb')) # ['xyz']If you want to match parentheses () as characters, escape them with backslash \ .
print(re.findall(r'\(.+\)', 'abc(def)ghi')) # ['(def)'] print(re.findall(r'\((.+)\)', 'abc(def)ghi')) # ['def']Match any single character
Using square brackets [] in a pattern matches any single character from the enclosed string.
Using a hyphen — between consecutive Unicode code points, like [a-z] , creates a character range. For example, [a-z] matches any single lowercase alphabetical character.
print(re.findall('[abc]x', 'ax-bx-cx')) # ['ax', 'bx', 'cx'] print(re.findall('[abc]+', 'abc-aaa-cba')) # ['abc', 'aaa', 'cba'] print(re.findall('[a-z]+', 'abc-xyz')) # ['abc', 'xyz']Match the start/end of the string
^ matches the start of the string, and $ matches the end of the string.
s = 'abc-def-ghi' print(re.findall('[a-z]+', s)) # ['abc', 'def', 'ghi'] print(re.findall('^[a-z]+', s)) # ['abc'] print(re.findall('[a-z]+$', s)) # ['ghi']Extract by multiple patterns
Use | to match a substring that conforms to any of the specified patterns. For example, to match substrings that follow either pattern A or pattern B , use A|B .
s = 'axxxb-012' print(re.findall('a.*b', s)) # ['axxxb'] print(re.findall(r'\d+', s)) # ['012'] print(re.findall(r'a.*b|\d+', s)) # ['axxxb', '012']Case-insensitive
The re module is case-sensitive by default. Set the flags argument to re.IGNORECASE to perform case-insensitive.
s = 'abc-Abc-ABC' print(re.findall('[a-z]+', s)) # ['abc', 'bc'] print(re.findall('[A-Z]+', s)) # ['A', 'ABC'] print(re.findall('[a-z]+', s, flags=re.IGNORECASE)) # ['abc', 'Abc', 'ABC']Python Substring After Character

In Python, a sequence of several characters is known as a string that contains quotes either single or double. If a user wants to get a specific part from the string object, it’s known as slicing. In simple words, it is the operation of getting a substring of a desired string. Sometimes, we just need to get the string that occurs after the substring. In such a situation, different built-in methods of Python can be utilized.
This post will explain different methods for getting a substring after the character in Python.
How to Get Substring After Character in Python?
To get a substring after a character in Python, multiple methods are available that are used for this particular purpose:
Method 1: Get Substring After Character in Python Using “split()” Method
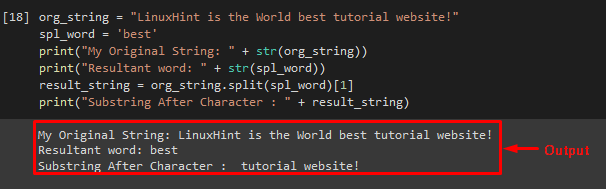
To split a string onto a substring, the “split()” method can be used. This method returns an object list containing elements.
Example
Initially, declare a string variable and pass a string as shown below:
Then, create another string variable that holds the word from onward we want to make a substring:
Now, use the print statement and display the value of the above-declared variables one by one:
print ( «My Original String: » + str ( org_string ) )
print ( «Resultant word: » + str ( spl_word ) )
Call the “split()” method and specify the list element index to which we want to access and make a substring. Then, store it in the “result_string” variable:
Call the “print()” function and pass a “result_string” variable as parameter:
Method 2: Get Substring After Character in Python Using “partition()” Method
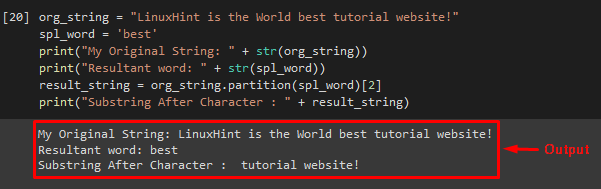
Use the “partition()” method to create a substring after the character. It first looks for a particular string and divides it into three components in a tuple. The element before the supplied string is included in the first element. On the other hand, the specified string is contained in the second element.
Example
Call the “partition()” method with a string value as an argument and specify the desired element index. Then, store it in the declared “result_string” variable:
Use the “print()” method to get the desired result:
As you can see, the provided string is divided into substring after the specified word:
Method 3: Get Substring After Character in Python Using “index()” Method
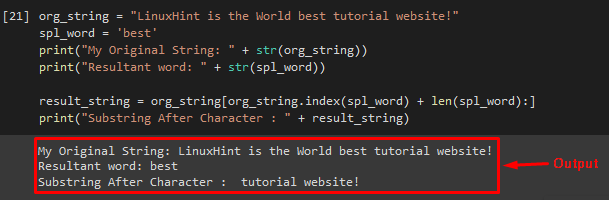
Another efficient way of substring after the character in Python, the “index()” method can be used. It returns the index of the first occurrence of the specified substring in the desired string.
Example
Use the “index()” method and take the string as a parameter with the specified string length:
To display the output of the “result_string” variable on screen, use the print statement:
Method 4: Substring After Character in Python Utilizing “find()” Method
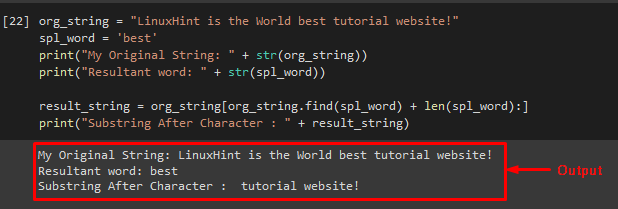
The “find()” method can also be used for creating a substring from the desired string. It can find the desired character from the string with its length and then pass them to the declared variable.
Example
Call the “find()” with the required split character and its length:
Then, view the result of the “find()” method by using the print statement:
That’s all! We have explained the different methods for substring after the character in Python.
Conclusion
To substring after a character in Python, multiple methods are used in Python, such as the “split()” method, the “partition()” method, the “index()” and the “find()” method. All methods first search the provided word from the given string then divide the string into parts and make a substring. This post elaborated on substring after the character in Python.
About the author
Maria Naz
I hold a master’s degree in computer science. I am passionate about my work, exploring new technologies, learning programming languages, and I love to share my knowledge with the world.