- matplotlib.pyplot.scatter#
- Matplotlib Scatter Plot — Tutorial and Examples
- Import Data
- Plot a Scatter Plot in Matplotlib
- Plotting Multiple Scatter Plots in Matplotlib
- Plotting a 3D Scatter Plot in Matplotlib
- Free eBook: Git Essentials
- Customizing Scatter Plot in Matplotlib
- Conclusion
- Data Visualization in Python
matplotlib.pyplot.scatter#
matplotlib.pyplot. scatter ( x , y , s = None , c = None , marker = None , cmap = None , norm = None , vmin = None , vmax = None , alpha = None , linewidths = None , * , edgecolors = None , plotnonfinite = False , data = None , ** kwargs ) [source] #
A scatter plot of y vs. x with varying marker size and/or color.
Parameters : x, y float or array-like, shape (n, )
s float or array-like, shape (n, ), optional
The marker size in points**2 (typographic points are 1/72 in.). Default is rcParams[‘lines.markersize’] ** 2 .
c array-like or list of colors or color, optional
The marker colors. Possible values:
- A scalar or sequence of n numbers to be mapped to colors using cmap and norm.
- A 2D array in which the rows are RGB or RGBA.
- A sequence of colors of length n.
- A single color format string.
Note that c should not be a single numeric RGB or RGBA sequence because that is indistinguishable from an array of values to be colormapped. If you want to specify the same RGB or RGBA value for all points, use a 2D array with a single row. Otherwise, value-matching will have precedence in case of a size matching with x and y.
If you wish to specify a single color for all points prefer the color keyword argument.
Defaults to None . In that case the marker color is determined by the value of color, facecolor or facecolors. In case those are not specified or None , the marker color is determined by the next color of the Axes ‘ current «shape and fill» color cycle. This cycle defaults to rcParams[«axes.prop_cycle»] (default: cycler(‘color’, [‘#1f77b4’, ‘#ff7f0e’, ‘#2ca02c’, ‘#d62728’, ‘#9467bd’, ‘#8c564b’, ‘#e377c2’, ‘#7f7f7f’, ‘#bcbd22’, ‘#17becf’]) ).
The marker style. marker can be either an instance of the class or the text shorthand for a particular marker. See matplotlib.markers for more information about marker styles.
cmap str or Colormap , default: rcParams[«image.cmap»] (default: ‘viridis’ )
The Colormap instance or registered colormap name used to map scalar data to colors.
This parameter is ignored if c is RGB(A).
norm str or Normalize , optional
The normalization method used to scale scalar data to the [0, 1] range before mapping to colors using cmap. By default, a linear scaling is used, mapping the lowest value to 0 and the highest to 1.
If given, this can be one of the following:
- An instance of Normalize or one of its subclasses (see Colormap Normalization ).
- A scale name, i.e. one of «linear», «log», «symlog», «logit», etc. For a list of available scales, call matplotlib.scale.get_scale_names() . In that case, a suitable Normalize subclass is dynamically generated and instantiated.
This parameter is ignored if c is RGB(A).
vmin, vmax float, optional
When using scalar data and no explicit norm, vmin and vmax define the data range that the colormap covers. By default, the colormap covers the complete value range of the supplied data. It is an error to use vmin/vmax when a norm instance is given (but using a str norm name together with vmin/vmax is acceptable).
This parameter is ignored if c is RGB(A).
alpha float, default: None
The alpha blending value, between 0 (transparent) and 1 (opaque).
linewidths float or array-like, default: rcParams[«lines.linewidth»] (default: 1.5 )
The linewidth of the marker edges. Note: The default edgecolors is ‘face’. You may want to change this as well.
edgecolors None> or color or sequence of color, default: rcParams[«scatter.edgecolors»] (default: ‘face’ )
The edge color of the marker. Possible values:
- ‘face’: The edge color will always be the same as the face color.
- ‘none’: No patch boundary will be drawn.
- A color or sequence of colors.
For non-filled markers, edgecolors is ignored. Instead, the color is determined like with ‘face’, i.e. from c, colors, or facecolors.
plotnonfinite bool, default: False
Whether to plot points with nonfinite c (i.e. inf , -inf or nan ). If True the points are drawn with the bad colormap color (see Colormap.set_bad ).
Returns : PathCollection Other Parameters : data indexable object, optional
If given, the following parameters also accept a string s , which is interpreted as data[s] (unless this raises an exception):
**kwargs Collection properties
To plot scatter plots when markers are identical in size and color.
- The plot function will be faster for scatterplots where markers don’t vary in size or color.
- Any or all of x, y, s, and c may be masked arrays, in which case all masks will be combined and only unmasked points will be plotted.
- Fundamentally, scatter works with 1D arrays; x, y, s, and c may be input as N-D arrays, but within scatter they will be flattened. The exception is c, which will be flattened only if its size matches the size of x and y.
Matplotlib Scatter Plot — Tutorial and Examples

Matplotlib is one of the most widely used data visualization libraries in Python. From simple to complex visualizations, it’s the go-to library for most.
In this guide, we’ll take a look at how to plot a Scatter Plot with Matplotlib.
Scatter Plots explore the relationship between two numerical variables (features) of a dataset.
Import Data
We’ll be using the Ames Housing dataset and visualizing correlations between features from it.
Let’s import Pandas and load in the dataset:
import pandas as pd df = pd.read_csv('AmesHousing.csv') Plot a Scatter Plot in Matplotlib
Now, with the dataset loaded, let’s import Matplotlib, decide on the features we want to visualize, and construct a scatter plot:
import matplotlib.pyplot as plt import pandas as pd df = pd.read_csv('AmesHousing.csv') fig, ax = plt.subplots(figsize=(10, 6)) ax.scatter(x = df['Gr Liv Area'], y = df['SalePrice']) plt.xlabel("Living Area Above Ground") plt.ylabel("House Price") plt.show() Here, we’ve created a plot, using the PyPlot instance, and set the figure size. Using the returned Axes object, which is returned from the subplots() function, we’ve called the scatter() function.
We need to supply the x and y arguments as the features we’d like to use to populate the plot. Running this code results in:
We’ve also set the x and y labels to indicate what the variables represent. There’s a clear positive correlation between these two variables. The more area there is above ground-level, the higher the price of the house was.
There are a few outliers, but the vast majority follows this hypothesis.
Plotting Multiple Scatter Plots in Matplotlib
If you’d like to compare more than one variable against another, such as — check the correlation between the overall quality of the house against the sale price, as well as the area above ground level — there’s no need to make a 3D plot for this.
While 2D plots that visualize correlations between more than two variables exist, some of them aren’t fully beginner friendly.
An easy way to do this is to plot two plots — in one, we’ll plot the area above ground level against the sale price, in the other, we’ll plot the overall quality against the sale price.
Let’s take a look at how to do that:
import matplotlib.pyplot as plt import pandas as pd df = pd.read_csv('AmesHousing.csv') fig, ax = plt.subplots(2, figsize=(10, 6)) ax[0].scatter(x = df['Gr Liv Area'], y = df['SalePrice']) ax[0].set_xlabel("Living Area Above Ground") ax[0].set_ylabel("House Price") ax[1].scatter(x = df['Overall Qual'], y = df['SalePrice']) ax[1].set_xlabel("Overall Quality") ax[1].set_ylabel("House Price") plt.show() Here, we’ve called plt.subplots() , passing 2 to indicate that we’d like to instantiate two subplots in the figure.
We can access these via the Axes instance — ax . ax[0] refers to the first subplot’s axes, while ax[1] refers to the second subplot’s axes.
Here, we’ve called the scatter() function on each of them, providing them with labels. Running this code results in:
Plotting a 3D Scatter Plot in Matplotlib
If you don’t want to visualize this in two separate subplots, you can plot the correlation between these variables in 3D. Matplotlib has built-in 3D plotting functionality, so doing this is a breeze.
First, we’ll need to import the Axes3D class from mpl_toolkits.mplot3d . This special type of Axes is needed for 3D visualizations. With it, we can pass in another argument — z , which is the third feature we’d like to visualize.
Let’s go ahead and import the Axes3D object and plot a scatter plot against the previous three features:
import matplotlib.pyplot as plt import pandas as pd from mpl_toolkits.mplot3d import Axes3D df = pd.read_csv('AmesHousing.csv') fig = plt.figure() ax = fig.add_subplot(111, projection = '3d') x = df['SalePrice'] y = df['Gr Liv Area'] z = df['Overall Qual'] ax.scatter(x, y, z) ax.set_xlabel("Sale price") ax.set_ylabel("Living area above ground level") ax.set_zlabel("Overall quality") plt.show() Free eBook: Git Essentials
Check out our hands-on, practical guide to learning Git, with best-practices, industry-accepted standards, and included cheat sheet. Stop Googling Git commands and actually learn it!
Running this code results in an interactive 3D visualization that we can pan and inspect in three-dimensional space:
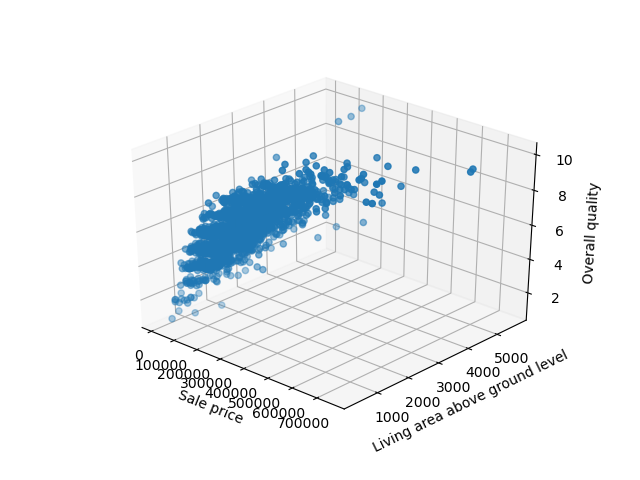
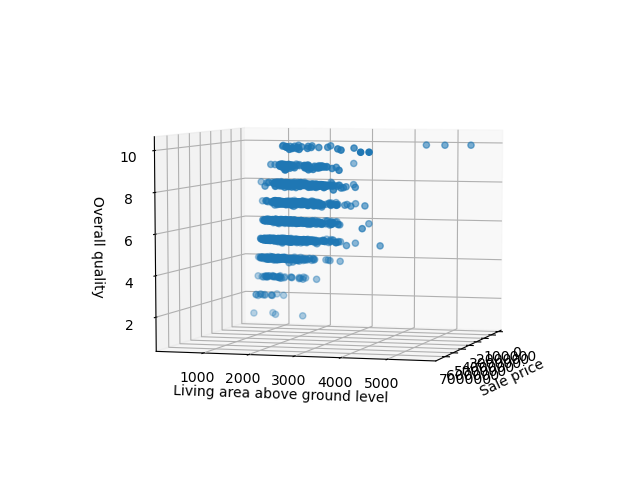
Customizing Scatter Plot in Matplotlib
You can change how the plot looks like by supplying the scatter() function with additional arguments, such as color , alpha , etc:
ax.scatter(x = df['Gr Liv Area'], y = df['SalePrice'], color = "blue", edgecolors = "white", linewidths = 0.1, alpha = 0.7) Running this code would result in:
Conclusion
In this tutorial, we’ve gone over several ways to plot a scatter plot using Matplotlib and Python.
If you’re interested in Data Visualization and don’t know where to start, make sure to check out our bundle of books on Data Visualization in Python:
Data Visualization in Python
Become dangerous with Data Visualization
✅ 30-day no-question money-back guarantee
✅ Updated regularly for free (latest update in April 2021)
✅ Updated with bonus resources and guides
Data Visualization in Python with Matplotlib and Pandas is a book designed to take absolute beginners to Pandas and Matplotlib, with basic Python knowledge, and allow them to build a strong foundation for advanced work with theses libraries — from simple plots to animated 3D plots with interactive buttons.
It serves as an in-depth, guide that’ll teach you everything you need to know about Pandas and Matplotlib, including how to construct plot types that aren’t built into the library itself.
Data Visualization in Python, a book for beginner to intermediate Python developers, guides you through simple data manipulation with Pandas, cover core plotting libraries like Matplotlib and Seaborn, and show you how to take advantage of declarative and experimental libraries like Altair. More specifically, over the span of 11 chapters this book covers 9 Python libraries: Pandas, Matplotlib, Seaborn, Bokeh, Altair, Plotly, GGPlot, GeoPandas, and VisPy.
It serves as a unique, practical guide to Data Visualization, in a plethora of tools you might use in your career.