- Saved searches
- Use saved searches to filter your results more quickly
- License
- pyexcel/pyexcel-ods
- Name already in use
- Sign In Required
- Launching GitHub Desktop
- Launching GitHub Desktop
- Launching Xcode
- Launching Visual Studio Code
- Latest commit
- Git stats
- Files
- README.rst
- About
- Read Excel(OpenDocument ODS) with Python Pandas
- Step 1: Install Pandas and odfpy
- Step 2: Read the first sheet of Excel(ODS) files
- Step 3: Pandas read excel sheet by name
- Step 4: Pandas read excel range of data
- Step 5: Pandas read excel - XLRDError: Openoffice.org ODS file; not supported
- Resources
Saved searches
Use saved searches to filter your results more quickly
You signed in with another tab or window. Reload to refresh your session. You signed out in another tab or window. Reload to refresh your session. You switched accounts on another tab or window. Reload to refresh your session.
It is a plugin to pyexcel and provides the capbility to read, manipulate and write data in ods formats using odfpy.
License
pyexcel/pyexcel-ods
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
Name already in use
A tag already exists with the provided branch name. Many Git commands accept both tag and branch names, so creating this branch may cause unexpected behavior. Are you sure you want to create this branch?
Sign In Required
Please sign in to use Codespaces.
Launching GitHub Desktop
If nothing happens, download GitHub Desktop and try again.
Launching GitHub Desktop
If nothing happens, download GitHub Desktop and try again.
Launching Xcode
If nothing happens, download Xcode and try again.
Launching Visual Studio Code
Your codespace will open once ready.
There was a problem preparing your codespace, please try again.
Latest commit
Git stats
Files
Failed to load latest commit information.
README.rst
pyexcel-ods — Let you focus on data, instead of ods format
pyexcel-ods is a tiny wrapper library to read, manipulate and write data in ods format using python 2.6 and python 2.7. You are likely to use it with pyexcel. pyexcel-ods3 is a sister library that depends on ezodf and lxml. pyexcel-odsr is the other sister library that has no external dependency but do ods reading only
If your company has embedded pyexcel and its components into a revenue generating product, please support me on github, patreon or bounty source to maintain the project and develop it further.
If you are an individual, you are welcome to support me too and for however long you feel like. As my backer, you will receive early access to pyexcel related contents.
And your issues will get prioritized if you would like to become my patreon as pyexcel pro user.
With your financial support, I will be able to invest a little bit more time in coding, documentation and writing interesting posts.
Fonts, colors and charts are not supported.
Nor to read password protected xls, xlsx and ods files.
You can install pyexcel-ods via pip:
or clone it and install it:
$ git clone https://github.com/pyexcel/pyexcel-ods.git $ cd pyexcel-ods $ python setup.py install .. testcode:: :hide: >>> import os >>> import sys >>> if sys.version_info[0] < 3: . from StringIO import StringIO . else: . from io import BytesIO as StringIO >>> PY2 = sys.version_info[0] == 2 >>> if PY2 and sys.version_info[1] < 7: . from ordereddict import OrderedDict . else: . from collections import OrderedDict
Here's the sample code to write a dictionary to an ods file:
>>> from pyexcel_ods import save_data >>> data = OrderedDict() # from collections import OrderedDict >>> data.update("Sheet 1": [[1, 2, 3], [4, 5, 6]]>) >>> data.update("Sheet 2": [["row 1", "row 2", "row 3"]]>) >>> save_data("your_file.ods", data)
>>> from pyexcel_ods import get_data >>> data = get_data("your_file.ods") >>> import json >>> print(json.dumps(data)) "Sheet 1": [[1, 2, 3], [4, 5, 6]], "Sheet 2": [["row 1", "row 2", "row 3"]]>
Here's the sample code to write a dictionary to an ods file:
>>> from pyexcel_ods import save_data >>> data = OrderedDict() >>> data.update("Sheet 1": [[1, 2, 3], [4, 5, 6]]>) >>> data.update("Sheet 2": [[7, 8, 9], [10, 11, 12]]>) >>> io = StringIO() >>> save_data(io, data) >>> # do something with the io >>> # In reality, you might give it to your http response >>> # object for downloading
Read from an ods from memory
Continue from previous example:
>>> # This is just an illustration >>> # In reality, you might deal with ods file upload >>> # where you will read from requests.FILES['YOUR_ODS_FILE'] >>> data = get_data(io) >>> print(json.dumps(data)) "Sheet 1": [[1, 2, 3], [4, 5, 6]], "Sheet 2": [[7, 8, 9], [10, 11, 12]]>
Special notice 30/01/2017: due to the constraints of the underlying 3rd party library, it will read the whole file before returning the paginated data. So at the end of day, the only benefit is less data returned from the reading function. No major performance improvement will be seen.
With that said, please install pyexcel-odsr and it gives better performance in pagination.
Let's assume the following file is a huge ods file:
>>> huge_data = [ . [1, 21, 31], . [2, 22, 32], . [3, 23, 33], . [4, 24, 34], . [5, 25, 35], . [6, 26, 36] . ] >>> sheetx = < . "huge": huge_data . > >>> save_data("huge_file.ods", sheetx)
And let's pretend to read partial data:
>>> partial_data = get_data("huge_file.ods", start_row=2, row_limit=3) >>> print(json.dumps(partial_data)) "huge": [[3, 23, 33], [4, 24, 34], [5, 25, 35]]>
And you could as well do the same for columns:
>>> partial_data = get_data("huge_file.ods", start_column=1, column_limit=2) >>> print(json.dumps(partial_data)) "huge": [[21, 31], [22, 32], [23, 33], [24, 34], [25, 35], [26, 36]]>
Obvious, you could do both at the same time:
>>> partial_data = get_data("huge_file.ods", . start_row=2, row_limit=3, . start_column=1, column_limit=2) >>> print(json.dumps(partial_data)) "huge": [[23, 33], [24, 34], [25, 35]]>
.. testcode:: :hide: >>> os.unlink("huge_file.ods") No longer, explicit import is needed since pyexcel version 0.2.2. Instead, this library is auto-loaded. So if you want to read data in ods format, installing it is enough.
>>> import pyexcel as pe >>> sheet = pe.get_book(file_name="your_file.ods") >>> sheet Sheet 1: +---+---+---+ | 1 | 2 | 3 | +---+---+---+ | 4 | 5 | 6 | +---+---+---+ Sheet 2: +-------+-------+-------+ | row 1 | row 2 | row 3 | +-------+-------+-------+
>>> sheet.save_as("another_file.ods")
Reading from a IO instance
You got to wrap the binary content with stream to get ods working:
>>> # This is just an illustration >>> # In reality, you might deal with ods file upload >>> # where you will read from requests.FILES['YOUR_ODS_FILE'] >>> odsfile = "another_file.ods" >>> with open(odsfile, "rb") as f: . content = f.read() . r = pe.get_book(file_type="ods", file_content=content) . print(r) . Sheet 1: +---+---+---+ | 1 | 2 | 3 | +---+---+---+ | 4 | 5 | 6 | +---+---+---+ Sheet 2: +-------+-------+-------+ | row 1 | row 2 | row 3 | +-------+-------+-------+
Writing to a StringIO instance
You need to pass a StringIO instance to Writer:
>>> data = [ . [1, 2, 3], . [4, 5, 6] . ] >>> io = StringIO() >>> sheet = pe.Sheet(data) >>> io = sheet.save_to_memory("ods", io) >>> # then do something with io >>> # In reality, you might give it to your http response >>> # object for downloading
Development steps for code changes
Upgrade your setup tools and pip. They are needed for development and testing only:
Then install relevant development requirements:
- pip install -r rnd_requirements.txt # if such a file exists
- pip install -r requirements.txt
- pip install -r tests/requirements.txt
Once you have finished your changes, please provide test case(s), relevant documentation and update CHANGELOG.rst.
As to rnd_requirements.txt, usually, it is created when a dependent library is not released. Once the dependecy is installed (will be released), the future version of the dependency in the requirements.txt will be valid.
How to test your contribution
Although nose and doctest are both used in code testing, it is adviable that unit tests are put in tests. doctest is incorporated only to make sure the code examples in documentation remain valid across different development releases.
On Linux/Unix systems, please launch your tests like this:
On Windows systems, please issue this command:
so as to beautify your code otherwise travis-ci may fail your unit test.
ODSReader is originally written by Marco Conti
.. testcode:: :hide: >>> import os >>> os.unlink("your_file.ods") >>> os.unlink("another_file.ods") About
It is a plugin to pyexcel and provides the capbility to read, manipulate and write data in ods formats using odfpy.
Read Excel(OpenDocument ODS) with Python Pandas
In this post we will see how to read Excel files with extensions:ods and . fods with Python and Pandas. Pandas offers a read_excel() method to read Excel files as a DataFrame.
Many options are available - you can read any sheet, all sheets, first one or range of data. Pandas read and convert any data stored in ODS format to the popular DataFrame format.
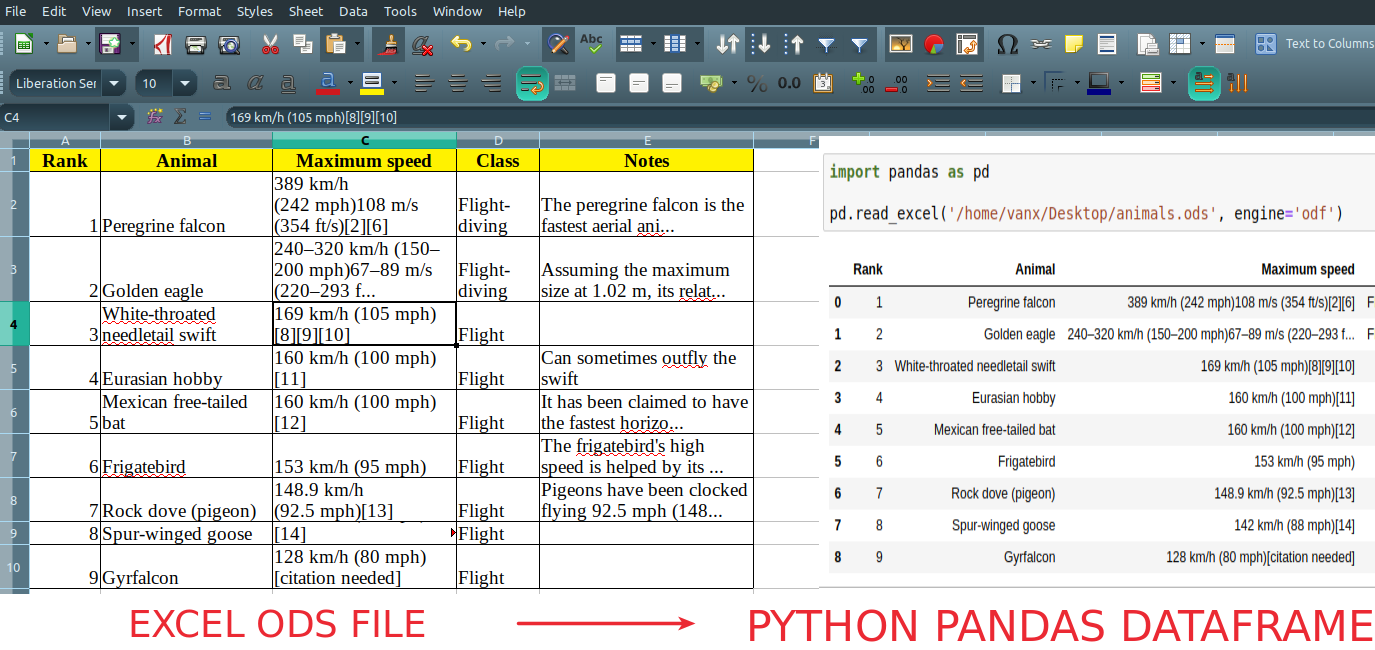
Let's assume the next ODS file stored on our local machine which needs to be read as a DataFrame or any othder Python format:
Step 1: Install Pandas and odfpy
Before reading the ODS files with Python we need to install additional packages like: odfpy + Pandas (if not installed or upgrade to latest).
To install odfpy + Pandas use next commands:
pip install pandas pip install odfpy Step 2: Read the first sheet of Excel(ODS) files
Now we can read the first sheet of the worksheet by calling Pandas method read_excel() :
import pandas as pd pd.read_excel('~/Desktop/animals.ods', engine='odf') | Rank | Animal | Maximum speed | Class | Notes | |
|---|---|---|---|---|---|
| 0 | 1 | Peregrine falcon | 389 km/h (242 mph)108 m/s (354 ft/s)[2][6] | Flight-diving | The peregrine falcon is the fastest aerial ani. |
| 1 | 2 | Golden eagle | 240–320 km/h (150–200 mph)67–89 m/s (220–293 f. | Flight-diving | Assuming the maximum size at 1.02 m, its relat. |
| 2 | 3 | White-throated needletail swift | 169 km/h (105 mph)[8][9][10] | Flight | NaN |
| 3 | 4 | Eurasian hobby | 160 km/h (100 mph)[11] | Flight | Can sometimes outfly the swift |
| 4 | 5 | Mexican free-tailed bat | 160 km/h (100 mph)[12] | Flight | It has been claimed to have the fastest horizo. |
| 5 | 6 | Frigatebird | 153 km/h (95 mph) | Flight | The frigatebird's high speed is helped by its . |
| 6 | 7 | Rock dove (pigeon) | 148.9 km/h (92.5 mph)[13] | Flight | Pigeons have been clocked flying 92.5 mph (148. |
| 7 | 8 | Spur-winged goose | 142 km/h (88 mph)[14] | Flight | NaN |
| 8 | 9 | Gyrfalcon | 128 km/h (80 mph)[citation needed] | Flight | NaN |
Step 3: Pandas read excel sheet by name
To work with multiple sheets read_excel method request the path the the file and the sheet name:
pd.read_excel("animals.ods", sheet_name="Sheet1") If the sheet name is missed then the first sheet will be read.
Step 4: Pandas read excel range of data
If you like to read only a specific range of data read_excel has several useful parameters for this purpose like:
- skiprows - line numbers to skip. If you like to start from row 6 than use - skiprows=6
- nrows - how many rows to read. If you like to start with fewer rows for a test
- index_col - which column to be used as a index
- usecols - which columns to be read only a specific range of columns:
pd.read_excel('/home/vanx/Desktop/animals.ods', usecols="A:C") To find more examples on how to read and import Excel files to Pandas DataFrame and Python check: Notebook -
Read Excel ODS with Python Pandas
Step 5: Pandas read excel - XLRDError: Openoffice.org ODS file; not supported
If you face error during reading the ODS or any other excel file with Python and Pandas:
XLRDError: Openoffice.org ODS file; not supported
Then you can update Pandas to the latest possible version and this will resolve the problem.
Pandas can be upgraded by:
pip install --upgrade pandas In some cases you can specify the reading engine for pd.read_excel as shown in the example:
pd.read_excel('animals.ods', engine='odf') Resources
By using DataScientYst - Data Science Simplified, you agree to our Cookie Policy.