Parsing HTML Tables in Python with pandas
Not long ago, I needed to parse some HTML tables from our confluence website at work. I first thought: I’m gonna need requests and BeautifulSoup. As HTML tables are well defined, I did some quick googling to see if there was some recipe or lib to parse them and I found a link to pandas. What? Can pandas do that too?
I have been using pandas for quite some time and have used read_csv, read_excel, even read_sql, but I had missed read_html!
Reading excel file with pandas¶
Before to look at HTML tables, I want to show a quick example on how to read an excel file with pandas. The API is really nice. If I have to look at some excel data, I go directly to pandas.
So let’s download a sample file file:
import io import requests import pandas as pd from zipfile import ZipFile
r = requests.get('http://www.contextures.com/SampleData.zip') ZipFile(io.BytesIO(r.content)).extractall()
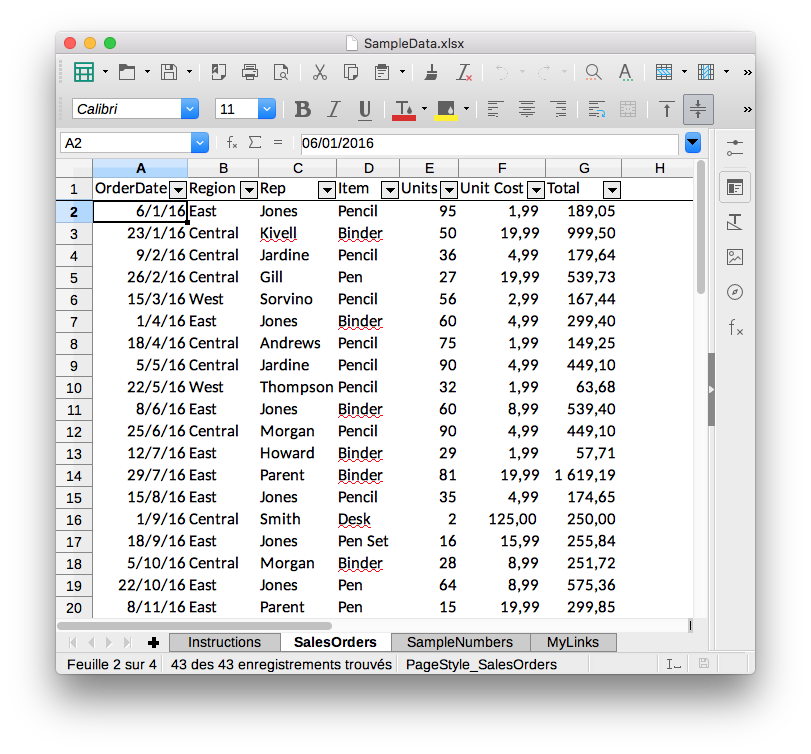
This created the SampleData.xlsx file that includes four sheets: Instructions, SalesOrders, SampleNumbers and MyLinks. Only the SalesOrders sheet includes tabular data: So let’s read it.
df = pd.read_excel('SampleData.xlsx', sheet_name='SalesOrders')
| OrderDate | Region | Rep | Item | Units | Unit Cost | Total | |
|---|---|---|---|---|---|---|---|
| 0 | 2016-01-06 | East | Jones | Pencil | 95 | 1.99 | 189.05 |
| 1 | 2016-01-23 | Central | Kivell | Binder | 50 | 19.99 | 999.50 |
| 2 | 2016-02-09 | Central | Jardine | Pencil | 36 | 4.99 | 179.64 |
| 3 | 2016-02-26 | Central | Gill | Pen | 27 | 19.99 | 539.73 |
| 4 | 2016-03-15 | West | Sorvino | Pencil | 56 | 2.99 | 167.44 |
That’s it. One line and you have your data in a DataFrame that you can easily manipulate, filter, convert and display in a jupyter notebook. Can it be easier than that?
Parsing HTML Tables¶
So let’s go back to HTML tables and look at pandas.read_html.
A URL, a file-like object, or a raw string containing HTML.
Let’s start with a basic HTML table in a raw string.
Parsing raw string¶
html_string = """Programming Language Creator Year C Dennis Ritchie 1972 Python Guido Van Rossum 1989 Ruby Yukihiro Matsumoto 1995 """
We can render the table using IPython display_html function:
from IPython.display import display_html display_html(html_string, raw=True)
| Programming Language | Creator | Year |
|---|---|---|
| C | Dennis Ritchie | 1972 |
| Python | Guido Van Rossum | 1989 |
| Ruby | Yukihiro Matsumoto | 1995 |
Let’s import this HTML table in a DataFrame. Note that the function read_html always returns a list of DataFrame objects:
dfs = pd.read_html(html_string) dfs
[ Programming Language Creator Year 0 C Dennis Ritchie 1972 1 Python Guido Van Rossum 1989 2 Ruby Yukihiro Matsumoto 1995]
| Programming Language | Creator | Year | |
|---|---|---|---|
| 0 | C | Dennis Ritchie | 1972 |
| 1 | Python | Guido Van Rossum | 1989 |
| 2 | Ruby | Yukihiro Matsumoto | 1995 |
This looks quite similar to the raw string we rendered above, but we are printing a pandas DataFrame object here! We can apply any operation we want.
Pandas automatically found the header to use thanks to the tag. It is not mandatory to define a table and is actually often missing on the web. So what happens if it’s not present?
html_string = """Programming Language Creator Year C Dennis Ritchie 1972 Python Guido Van Rossum 1989 Ruby Yukihiro Matsumoto 1995 """
| 0 | 1 | 2 | |
|---|---|---|---|
| 0 | Programming Language | Creator | Year |
| 1 | C | Dennis Ritchie | 1972 |
| 2 | Python | Guido Van Rossum | 1989 |
| 3 | Ruby | Yukihiro Matsumoto | 1995 |
In this case, we need to pass the row number to use as header.
pd.read_html(html_string, header=0)[0]
| Programming Language | Creator | Year | |
|---|---|---|---|
| 0 | C | Dennis Ritchie | 1972 |
| 1 | Python | Guido Van Rossum | 1989 |
| 2 | Ruby | Yukihiro Matsumoto | 1995 |
Parsing a http URL¶
The same data we read in our excel file is available in a table at the following address: http://www.contextures.com/xlSampleData01.html
Let’s pass this url to read_html :
dfs = pd.read_html('http://www.contextures.com/xlSampleData01.html')
[ 0 1 2 3 4 5 6 0 OrderDate Region Rep Item Units UnitCost Total 1 1/6/2016 East Jones Pencil 95 1.99 189.05 2 1/23/2016 Central Kivell Binder 50 19.99 999.50 3 2/9/2016 Central Jardine Pencil 36 4.99 179.64 4 2/26/2016 Central Gill Pen 27 19.99 539.73 5 3/15/2016 West Sorvino Pencil 56 2.99 167.44 6 4/1/2016 East Jones Binder 60 4.99 299.40 7 4/18/2016 Central Andrews Pencil 75 1.99 149.25 8 5/5/2016 Central Jardine Pencil 90 4.99 449.10 9 5/22/2016 West Thompson Pencil 32 1.99 63.68 10 6/8/2016 East Jones Binder 60 8.99 539.40 11 6/25/2016 Central Morgan Pencil 90 4.99 449.10 12 7/12/2016 East Howard Binder 29 1.99 57.71 13 7/29/2016 East Parent Binder 81 19.99 1619.19 14 8/15/2016 East Jones Pencil 35 4.99 174.65 15 9/1/2016 Central Smith Desk 2 125.00 250.00 16 9/18/2016 East Jones Pen Set 16 15.99 255.84 17 10/5/2016 Central Morgan Binder 28 8.99 251.72 18 10/22/2016 East Jones Pen 64 8.99 575.36 19 11/8/2016 East Parent Pen 15 19.99 299.85 20 11/25/2016 Central Kivell Pen Set 96 4.99 479.04 21 12/12/2016 Central Smith Pencil 67 1.29 86.43 22 12/29/2016 East Parent Pen Set 74 15.99 1183.26 23 1/15/2017 Central Gill Binder 46 8.99 413.54 24 2/1/2017 Central Smith Binder 87 15.00 1305.00 25 2/18/2017 East Jones Binder 4 4.99 19.96 26 3/7/2017 West Sorvino Binder 7 19.99 139.93 27 3/24/2017 Central Jardine Pen Set 50 4.99 249.50 28 4/10/2017 Central Andrews Pencil 66 1.99 131.34 29 4/27/2017 East Howard Pen 96 4.99 479.04 30 5/14/2017 Central Gill Pencil 53 1.29 68.37 31 5/31/2017 Central Gill Binder 80 8.99 719.20 32 6/17/2017 Central Kivell Desk 5 125.00 625.00 33 7/4/2017 East Jones Pen Set 62 4.99 309.38 34 7/21/2017 Central Morgan Pen Set 55 12.49 686.95 35 8/7/2017 Central Kivell Pen Set 42 23.95 1005.90 36 8/24/2017 West Sorvino Desk 3 275.00 825.00 37 9/10/2017 Central Gill Pencil 7 1.29 9.03 38 9/27/2017 West Sorvino Pen 76 1.99 151.24 39 10/14/2017 West Thompson Binder 57 19.99 1139.43 40 10/31/2017 Central Andrews Pencil 14 1.29 18.06 41 11/17/2017 Central Jardine Binder 11 4.99 54.89 42 12/4/2017 Central Jardine Binder 94 19.99 1879.06 43 12/21/2017 Central Andrews Binder 28 4.99 139.72]
We have one table and can see that we need to pass the row number to use as header (because is not present).
dfs = pd.read_html('http://www.contextures.com/xlSampleData01.html', header=0) dfs[0].head()
| OrderDate | Region | Rep | Item | Units | UnitCost | Total | |
|---|---|---|---|---|---|---|---|
| 0 | 1/6/2016 | East | Jones | Pencil | 95 | 1.99 | 189.05 |
| 1 | 1/23/2016 | Central | Kivell | Binder | 50 | 19.99 | 999.50 |
| 2 | 2/9/2016 | Central | Jardine | Pencil | 36 | 4.99 | 179.64 |
| 3 | 2/26/2016 | Central | Gill | Pen | 27 | 19.99 | 539.73 |
| 4 | 3/15/2016 | West | Sorvino | Pencil | 56 | 2.99 | 167.44 |
Урок 3. Парсинг таблиц на Python
В этом уроке, мы продолжим цикл статей по парсингу на Python, и рассмотрим парсинг таблиц на Python. В предыдущем уроке, мы с вами разобрались с тем, как парсить обычные сайты. В этом уроке рассмотрим парсинг на Python на примере сайта премьер лиги россии по футболу. На странице по ссылке, мы увидим турнирную таблицу чемпионата.

Мы не будем парсить всю таблицу, в этом уроке, мы разберемся как работать с табличными данными. Для этих целей нам достаточно спарсить следующие колонки:
- Место команды(1 колонка)
- Название команда (2 колонка)
- Количество забитых и пропущенных голов
- Количество очков
Анализ структуры html страницы
Табличные данные в html отличаются своими тегами от того, что мы парсили в предыдущем уроке. В любом случае, эта стья подразумевает, что вы уже знакомы с html тегами, и css селекторами, хотя последнее в этой статье использоваться не будет.
Рассмотрим структуру html:
- Вся наша таблица лежит в блоке div с классом «stats-tournament-table»
- Внутри Этого div лежит тег table
- Затем тег tbody
- Затем тег tr
- Тег td
Наша задача заключается в том, что бы найти все теги tr внутри блока div с классом «stats-tournament-table» . А затем в цикле перебрать полученный список. В целом, данный скрипт по своей структуре не сильно отличается от предыдущего.
Создание парсера
В этом уроке, я уже не буду подробно объяснять функции, которые тут описаны. Подробнее о том, что делает та или иная функция, можно почитать:
И так, ниже я выложу весь листинг кода, и мы по порядку разберемся, как устроен внутренний механизм данного парсера.
import requests from bs4 import BeautifulSoup import re LINK = "https://premierliga.ru/tournaments/championship/tournament-table/" def main(): link = LINK print(get_data(get_html(link))) def get_html(link): response = requests.get(link) return response.text def get_data(html): soup = BeautifulSoup(html,'lxml') trs = soup.find('div', class_=('stats-tournament-table')).find('table').find_all('tr') for tr in trs: position = tr.find_all('td', class_='place') for i in position: positions = i.text.replace('\n','') #print(positions) club = tr.find_all('td', class_='club') for i in club: clubs = i.text.replace('\n','') #print(clubs) goal = tr.find_all('td', class_='dark-blue goals') for i in goal: goals_plus = i.find('span', class_='green').get_text() goals_minus = i.find('span', class_='red').get_text() #print(goals_plus,'-',goals_minus) point = tr.find_all("p", ) for i in point: points = i.text.replace('\n', '') #print(points) print(positions,clubs,goals_plus,'Голов Забито','-',goals_minus,'Голов Пропущено',points,'Очков' ) #return trs if __name__=='__main__': main()Как вы помните из предыдущих уроков, основная работа у нас происходит в функции get_data() .
- В самом начале, создаем ( soup ) экземпляр BS
- Затем ищем все теги tr внутри div с классом « stats-tournament-table »
- В результате поиска, мы получаем список всех найденных тегов tr
- Ищем позиции команд (1 колонка). Для этого находим все теги td с классом place , так как мы используем атрибут find_all , то в результате мы получаем список всех тегов td , которые находятся внутри ранее полученного тега tr
- Снова запускаем цикл for, внутри предыдущего цикла, и перебирая список, очищаем от всех лишних пробелов, заменяя все пустотой. В результате, мы получаем позиции команда, очищенный от всего лишнего
- Запускам цикл, и так же перебираем полученный список. Забитые голы, находятся в теге span с классом « green «, пропущенные с классом « red «, затем используем атрибут get_text() , который позволяет получить нам текст без тегов.
На этом этапе, мы уже получили все данные, которые планировали.
В случае, если у вас где то возникает ошибка, пишите в комментариях. Разберем вашу проблему.
Запись в csv
В целом запись в csv , ничем не отличается от того, что мы делали ранее, в предыдущем уроке. Создаем функцию записи в csv. В функции get_data() создаем словарь data .
def write_csv(data): with open('premier', 'a') as f: recorder = csv.writer(f) recorder.writerow((data['positions'], data['clubs'], data['goals_plus'], data['goals_minus'], data['points']))Отлично, мы написали полноценный парсер, который собирает данные и сохраняет в csv.
Заключение
В заключении к этому уроку хочу сказать следующее. Данный код не претендует на самый правильный, возможно где то можно было бы сделать лучше, но что есть, то есть.
Сегодня мы разобрали метод парсинга табличных данных на Python. Для хорошего парсинга, как понимаете, необходимы хорошие знания html , поэтому если у вас с этим трудности, настоятельно рекомендую вам почитать про основы html . Используя данную конструкцию, сейчас вы уже можете спарсить многие сайты, но все же, парсинг данных не ограничивается только этим. В следующих уроках, мы разберем с вами:
- Парсинг сайтов, где данные подгружаются средствами js
- Разберемся с тем, как ловить и отправлять POST запросы
- Парсинг данных с использованием Selenium
- И многое другое
По всем вопросам, рекомендую писать в комментариях. Постараюсь максимально быстро, и развернуто ответить вам.
Вам также может понравиться

Парсинг на Python
Парсинг на Python — это инструмент позволяющий собирать всю открытую информацию с различных сайтов. В этом небольшом курсе, мы с вами пройдем […]
Урок 2. Парсер на Python
Продолжаем наш небольшой курс по парсингу на Python. В предыдущем уроке, мы с вами ознакомились с тем как устроен парсер на python, […]
- Затем тег tr
- Затем тег tbody
- Внутри Этого div лежит тег table

