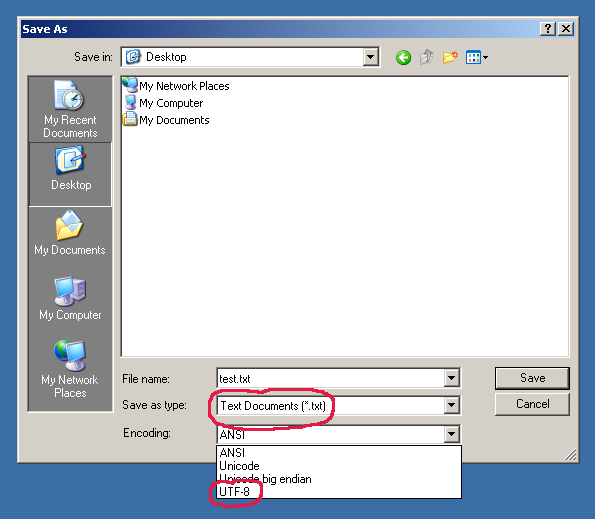
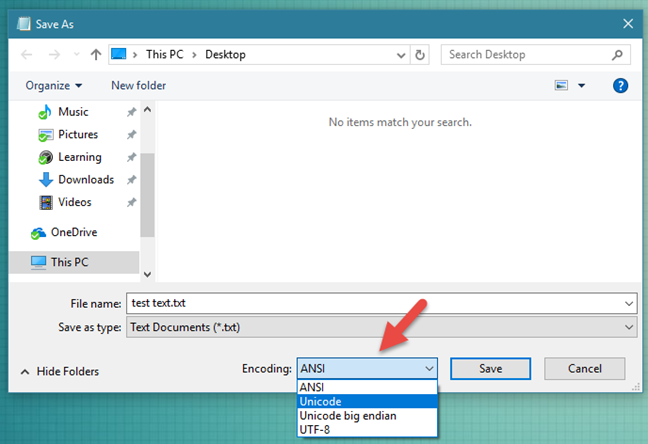
- Как записать текст на русском в файл UTF-8?
- Работа с файлами
- Открываем, а затем читаем или записываем
- Чтение файла с разной кодировкой
- Добавление в конец и запрет открытия файлов
- Временные файлы
- Именованные временные файлы
- Временные папки
- 10.9. File Encoding¶
- 10.9.1. Str vs Bytes¶
- 10.9.2. UTF-8¶
- 10.9.3. Unicode Encode Error¶
- 10.9.4. Unicode Decode Error¶
- 10.9.5. Escape Characters¶
- Python open file encoding windows 1251
- Войти
- Python и кодировки
Как записать текст на русском в файл UTF-8?
1. Почему файлы ‘str_ru_text_1.txt’, ‘str_ru_text_2.txt’ в кодировке Windows 1251, а файлы ‘str_en_text_1.txt’, ‘str_en_text_2.txt’ — в UTF-8?
2. Есть ли способ записать utf-8 без str.encode(‘utf-8’)?
3. Где описаны правила записи строк в файл? Где и что почитать по этой проблеме?
with open('str_ru_text_1.txt', 'rb') as f: print(f.read().decode('utf-8')) with open('str_en_text_1.txt', 'rb') as f: print(f.read().decode('utf-8'))Оценить 2 комментария
>а файлы ‘str_en_text_1.txt’, ‘str_en_text_2.txt’ — в UTF-8?
Как ты определил по файлу с ascii символами в какой они кодировке?
lololololo: см. ветку комментариев к первому комментарию (началось с прикладного софта, закончилось подбором кодировки через decode): https://toster.ru/answer?answer_id=344879#comments_list
Товарищи, это писец какой-то. Хотели как лучше, а получилось еще более через жопу.
mode is an optional string that specifies the mode in which the file is opened. <. >In text mode, if encoding is not specified the encoding used is platform dependent: locale.getpreferredencoding(False) is called to get the current locale encoding. (For reading and writing raw bytes use binary mode and leave encoding unspecified.)
1. Если не указан режим ‘b’, то по умолчанию файл считается текстовым. В двоичный файл можно писать только байты, в текстовый — только юникод.
(В текстовом режиме файл читается только до EOF (‘\x1a’). Как совместить чтение до конца файла и запись юникода в файл? А никак.)
2. Если кодировка не указана, по умолчанию берется locale.getpreferredencoding(False), т.е. результат выполнения будет зависеть от настроек оси! (для винды — от текущей локали). Нахера. От одних граблей избавились, другие приобрели.
В общем, всегда явно указывай явно кодировку файла.
with open('str_ru_text_1.txt', 'w', encoding='utf-8') as f:Из вопроса:
>> Python 3.4, Windows 8.1
С codecs не встречался, а с двойкой не работаю. Чем codecs.open от open отличается (в Python 3)?
Если только для двойки, то не стоит тратить время на объяснение, спасибо. А с параметром encoding еще тогда разобрались, но без источников. Спасибо за ссылку.
Работа с файлами

На практике в реальных проектах Data Science часто приходится сталкиваться с чтением датасетов, а также записывать добытую в ходе вычислений информацию в файлы. Сегодня мы расскажем о работе с файлами в Python: чтение и запись, проблема с кодировками, добавление значений в конец файла, временные папки и файлы.
Открываем, а затем читаем или записываем
Предположим, у нас имеется файл, который нужно прочитать в Python. Для этого можно воспользоваться функцией open внутри контекстного менеджера:
with open('file.txt') as f: data = f.read() # содержимое файла Таким же образом можно записать информацию в файл, указав w в качестве аргумента:
text = 'Hello' with open('file.txt', 'w') as f: f.write(text) Отметим некоторые особенности данной функции. Во-первых, для чтения файла мы не указывали никаких аргументов кроме имени файла, поскольку по умолчанию уже стоит режим чтения. Мы также не указывали явно, что это именно текстовый файл, а не бинарный, так как это тоже стоит по умолчанию. Для чтения и записи бинарных файлов добавляется b , например, rb или wb .
Во-вторых, мы использовали функцию open в контекстном менеджере. Можно обойтись и без него, но тогда после чтения или записи следует закрыть файл.
f = open('file.txt') f.read() f.close() На открытие файла Python выделяет память, поэтому, чтобы избежать ее утечки, рекомендуется закрывать файлы.
Чтение файла с разной кодировкой
На многих операционных системах Python в качестве стандарта кодирования использует UTF-8, который также поддерживает кириллицу. Тем не менее, часто можно столкнуться с проблемами неправильной кодировки и получить распространенную ошибку вроде этой:
>>> f = open('somefile.txt', encoding='ascii') >>> f.read() Traceback (most recent call last): File "", line 1, in File "/usr/local/lib/Python3.8/encodings/ascii.py", line 26, in decode return codecs.ascii_decode(input, self.errors)[0] UnicodeDecodeError: 'ascii' codec can't decode byte 0xc3 in position 12: ordinal not in range(128)) В примере указана кодировка ASCII, но файл закодирован в другом формате, поэтому и возникает такая ошибка. Решить ее можно тремя способами:
- Указать erorr=replace , который заменит нераспознанные символы знаком ? :
>>> f = open('somefile.txt', encoding='ascii', errors='replace') >>> f.read() 'H?llo py?ho?-school!' >>> f = open('somefile.txt', encoding='ascii', errors='replace') >>> f.read() 'Hllo pyho-school!' f = open('somefile.txt', encoding='utf-8') # или cp1251 f = open('somefile.txt', encoding='cp1251') Добавление в конец и запрет открытия файлов
Как мы уже отметили ранее, для записи текстового файла добавляется аргумент w . Но если вызвать метод write, он перепишет весь файл. Во многих случаях требуется добавить данные в конец файла. Тогда используется a вместо w :
text2 = 'world' with open('file.txt', 'a') as f: f.write(text) # Helloworld Если файла не существует, то при a и при w он будет создан. Но чтобы не трогать существующие файлы, а создать новый, передается параметр x :
# 'x' не даст возможности открыть файл, так как он существует >>> with open('file.txt', 'x') as f: . f.write(text2) FileExistsError Traceback (most recent call last) FileExistsError: [Errno 17] File exists: 'file.txt' # Поскольку file2.txt не существует, все OK >>> with open('file2.txt', 'x') as f: . f.write(text2) Временные файлы
Иногда бывает, что требуется создать файл или папку внутри Python-программы, а после ее закрытия их нужно удалить. Тогда пригодится стандартный модуль tempfile. Например, класс TemporaryFile создаст временный файл, который удалится после закрытия. Ниже пример в Python.
>>> from tempfile import TemporaryFile >>> f = TemporaryFile("w+t") >>> f.write("hello") >>> f.seek(0) >>> f.read() 'hello' >>> f.close() # файл уничтожается # либо в контекстном менеджере f.write(text2) Обратите внимание на 3 вещи. Первое, мы явно передаем «w+t» , чтобы записать как текстовый файл, поскольку по умолчанию стоит «w+b» для бинарных файлов. Второе, метод seek(0) используется для перехода на самый первый символ, поскольку чтение происходит с текущего указателя, а он стоит в конце (после буквы ‘o’ в слове ‘hello’). Поэтому не стоит переживать, что мы можем стереть предыдущую запись:
>>> f.seek(5) # переходим в конец >>> f.read() '' >>> f.write("world") 5 >>> f.seek(0) # переходим в начало >>> f.read() 'helloworld' Третье, файл TemporaryFile невидим для файловой системы, он используется только внутри Python, поэтому извне будет трудно его найти.
Именованные временные файлы
А вот объекты класса NamedTemporaryFile будут видны файловой системе, и найти месторасположение можно с помощью атрибута name :
>>> from tempfile import NamedTemporaryFile >>> f = NamedTemporaryFile("w+t") >>> f.name '/tmp/tmp60djsgli' >>> f.close() Как можно заметить, файл называется tmp60djsgli . Для удобства можно явно указать его название и формат:
>>> f = NamedTemporaryFile("w+t", prefix="myfile", suffix=".txt") >>> f.name '/tmp/myfile7mxae0fi.txt' Временные папки
Кроме временных файлов можно создавать временные папки. Для этого используется класс TemporaryDirectory :
>>> from tempfile import TemporaryDirectory >>> d = TemporaryDirectory() >>> d.name '/tmp/tmp5eadqzz5'
Он также принимает в качестве аргументов prefix и suffix , а также может использоваться внутри контекстного менеджера Python.
В следующей статье поговорим о взаимодействии файловой системы и Python. А получить практические навыки работы с файлами на реальных проектах Data Science вы сможете на наших курсах по Python в лицензированном учебном центре обучения и повышения квалификации IT-специалистов в Москве.
10.9. File Encoding¶
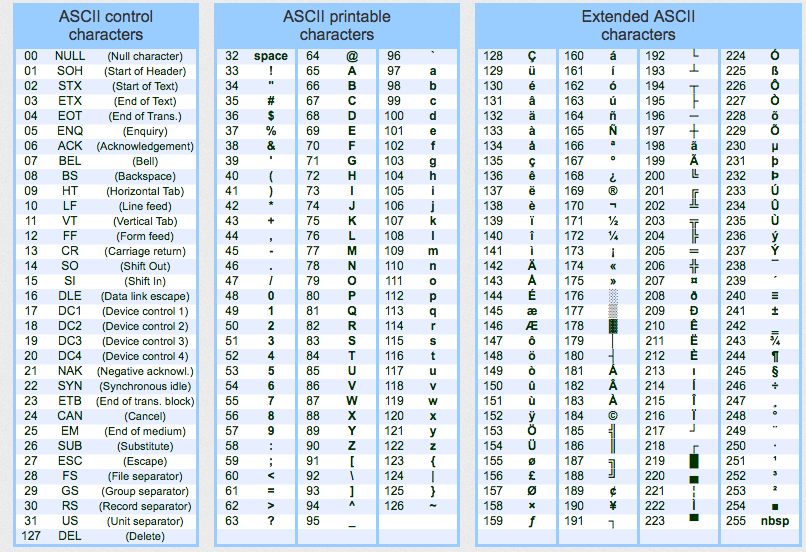
- utf-8 — a.k.a. Unicode — international standard (should be always used!)
- iso-8859-1 — ISO standard for Western Europe and USA
- iso-8859-2 — ISO standard for Central Europe (including Poland)
- cp1250 or windows-1250 — Central European encoding on Windows
- cp1251 or windows-1251 — Eastern European encoding on Windows
- cp1252 or windows-1252 — Western European encoding on Windows
- ASCII — ASCII characters only
- Since Windows 10 version 1903, UTF-8 is default encoding for Notepad!

10.9.1. Str vs Bytes¶
- That was a big change in Python 3
- In Python 2, str was bytes
- In Python 3, str is unicode (UTF-8)
>>> text = 'Księżyc' >>> text 'Księżyc'
>>> text = b'Księżyc' Traceback (most recent call last): SyntaxError: bytes can only contain ASCII literal characters
Default encoding is UTF-8 . Encoding names are case insensitive. cp1250 and windows-1250 are aliases the same codec:
>>> text = 'Księżyc' >>> >>> text.encode() b'Ksi\xc4\x99\xc5\xbcyc' >>> text.encode('utf-8') b'Ksi\xc4\x99\xc5\xbcyc' >>> text.encode('iso-8859-2') b'Ksi\xea\xbfyc' >>> text.encode('cp1250') b'Ksi\xea\xbfyc' >>> text.encode('windows-1250') b'Ksi\xea\xbfyc'
Note the length change while encoding:
>>> text = 'Księżyc' >>> text 'Księżyc' >>> len(text) 7
>>> text = 'Księżyc'.encode() >>> text b'Ksi\xc4\x99\xc5\xbcyc' >>> len(text) 9
Note also, that those characters produce longer output:
But despite being several «characters» long, the length is different:
Here’s the output of all Polish diacritics (accented characters) with their encoding:
>>> 'ą'.encode() b'\xc4\x85' >>> 'ć'.encode() b'\xc4\x87' >>> 'ę'.encode() b'\xc4\x99' >>> 'ł'.encode() b'\xc5\x82' >>> 'ń'.encode() b'\xc5\x84' >>> 'ó'.encode() b'\xc3\xb3' >>> 'ś'.encode() b'\xc5\x9b' >>> 'ż'.encode() b'\xc5\xbc' >>> 'ź'.encode() b'\xc5\xba'
Note also a different way of iterating over bytes :
>>> text = 'Księżyc' >>> >>> for character in text: . print(character) K s i ę ż y c >>> >>> for character in text.encode(): . print(character) 75 115 105 196 153 197 188 121 99
10.9.2. UTF-8¶
>>> FILE = r'/tmp/myfile.txt' >>> >>> with open(FILE, mode='w', encoding='utf-8') as file: . file.write('José Jiménez') 12 >>> >>> with open(FILE, encoding='utf-8') as file: . print(file.read()) José Jiménez
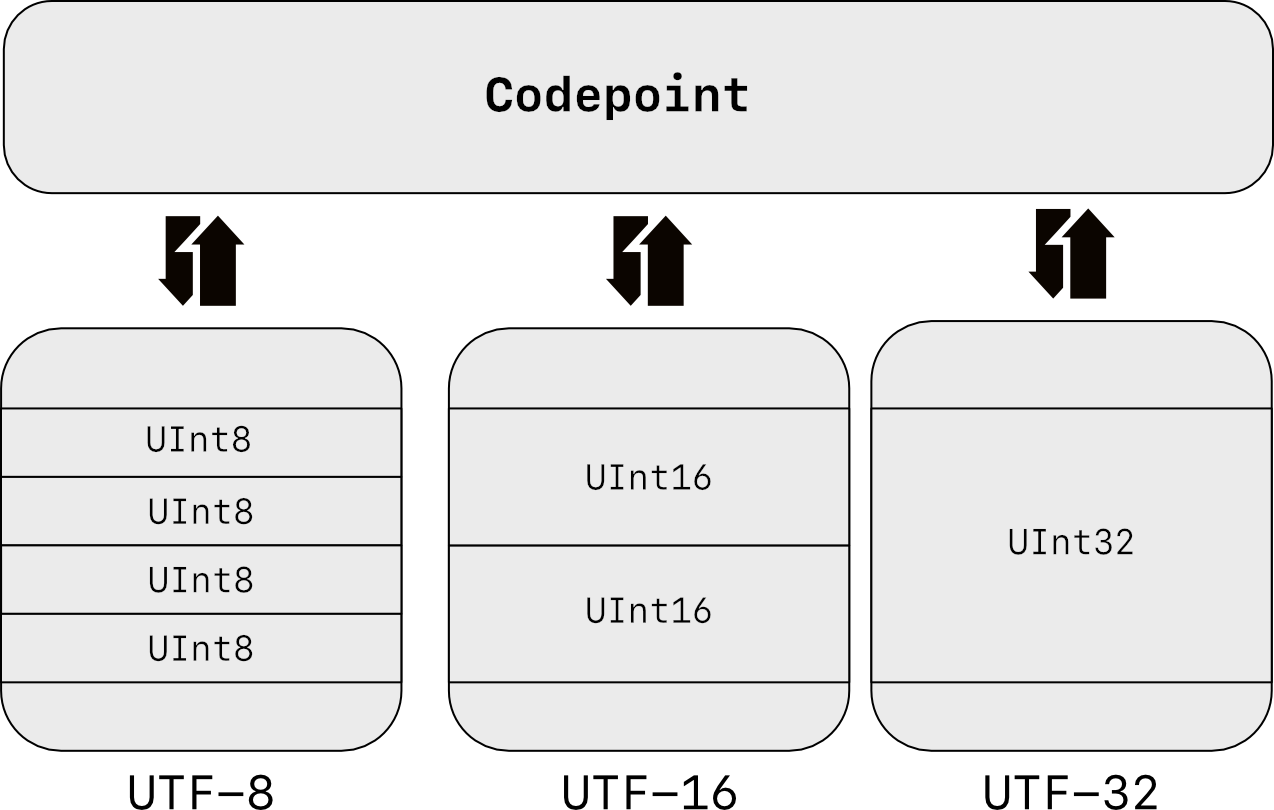
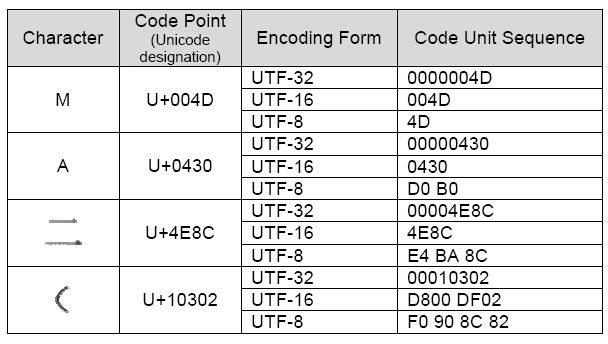
10.9.3. Unicode Encode Error¶
>>> FILE = r'/tmp/myfile.txt' >>> >>> with open(FILE, mode='w', encoding='cp1250') as file: . file.write('José Jiménez') 12
10.9.4. Unicode Decode Error¶
>>> FILE = r'/tmp/myfile.txt' >>> >>> with open(FILE, mode='w', encoding='utf-8') as file: . file.write('José Jiménez') 12 >>> >>> with open(FILE, encoding='cp1250') as file: . print(file.read()) JosĂ© JimĂ©nez
10.9.5. Escape Characters¶
- \r\n — is used on windows
- \n — is used everywhere else
- More information in Builtin Printing
- Learn more at https://en.wikipedia.org/wiki/List_of_Unicode_characters

Frequently used escape characters:
- \n — New line (ENTER)
- \t — Horizontal Tab (TAB)
- \’ — Single quote ‘ (escape in single quoted strings)
- \» — Double quote » (escape in double quoted strings)
- \\ — Backslash \ (to indicate, that this is not escape char)
Less frequently used escape characters:
- \a — Bell (BEL)
- \b — Backspace (BS)
- \f — New page (FF — Form Feed)
- \v — Vertical Tab (VT)
- \uF680 — Character with 16-bit (2 bytes) hex value F680
- \U0001F680 — Character with 32-bit (4 bytes) hex value 0001F680
- \o755 — ASCII character with octal value 755
- \x1F680 — ASCII character with hex value 1F680
>>> a = '\U0001F9D1' # 🧑 >>> b = '\U0000200D' # '' >>> c = '\U0001F680' # 🚀 >>> >>> astronaut = a + b + c >>> print(astronaut) 🧑🚀
Python open file encoding windows 1251
![]()
Войти
Если у вас не работает один из способов авторизации, сконвертируйте свой аккаунт по ссылке
Авторизуясь в LiveJournal с помощью стороннего сервиса вы принимаете условия Пользовательского соглашения LiveJournal
Python и кодировки
Вечно путаюсь в этих кодировках, поэтому решил сделать себе памятку. Покажу на примере.
Итак, кодировка исходного кода задается в первой-второй строке:
Мы получили данные, и сейчас они находятся в кодировке 1251, а исходник в utf-8, и нам нужно воспользоватся регулярками с кириллицей чтобы что-нибудь найти, выражение:
выдаст нам пустой массив, потомому что данные в 1251 а регулярка в utf-8. В питоне есть несколько функций для перекодирования:
decode(‘WINDOWS-1251’) — декодирует строку из кодировки 1251 в ЮНИКОД(ЮНИКОД != UTF-8)
encode(‘UTF-8’) — кодирует строку из юникода в UTF-8.
Что касается Юникод vs UTF-8, то:
UNICODE: u’\u041c\u0430\u043c\u0430 \u043c\u044b\u043b\u0430 \u0440\u0430\u043c\u0443′
UTF-8: ‘\xd0\x9c\xd0\xb0\xd0\xbc\xd0\xb0 \xd0\xbc\xd1\x8b\xd0\xbb\xd0\xb0 \xd1\x80\xd0\xb0\xd0\xbc\xd1\x83’
нормальный вид: ‘Мама мыла раму’
Итак, чтобы у нас не было проблем с кодировками, нам достаточно сделать вот так:
И теперь наша запарсеная страница в той же кодировке что и исходник программы, и можно смело использовать кириллицу в регулярках, или в других ваших решениях. Конечно это не единственное решение, но в моем случае самое простое и удобное.