- Основы Pandas №1 // Чтение файлов, DataFrame, отбор данных
- Чтобы разобраться со всем, необходимо…
- Как открывать файлы с данными в pandas
- Структуры данных Python
- Загрузка файла .csv в pandas DataFrame
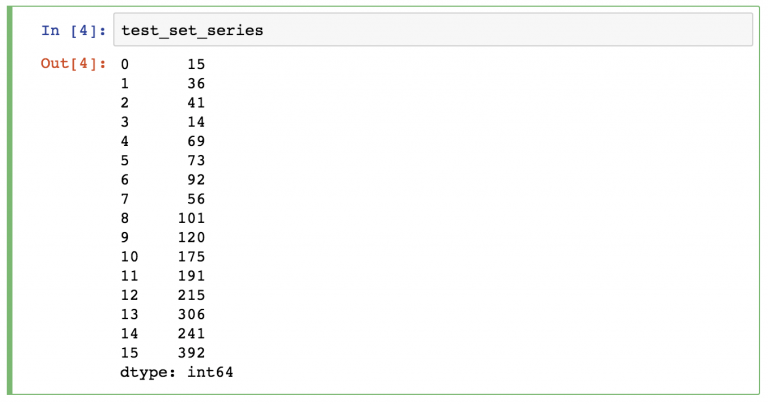
- Отбор данных из dataframe в pandas
- Вывод всего dataframe
- Вывод части dataframe
- Вывод определенных колонок из dataframe
- Фильтрация определенных значений в dataframe
- Функции могут использоваться одна за другой
- Проверьте себя!
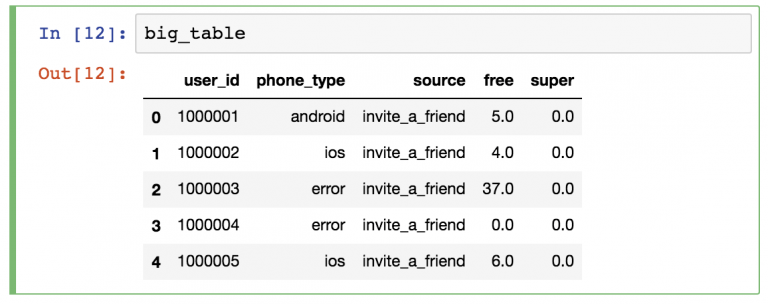
- Итого
- Import CSV file as a Pandas DataFrame
Основы Pandas №1 // Чтение файлов, DataFrame, отбор данных
Pandas — одна из самых популярных библиотек Python для аналитики и работы с Data Science. Это как SQL для Python. Все потому, что pandas позволяет работать с двухмерными таблицами данных в Python. У нее есть и масса других особенностей. В этой серии руководств по pandas вы узнаете самое важное (и часто используемое), что необходимо знать аналитику или специалисту по Data Science. Это первая часть, в которой речь пойдет об основах.
Примечание: это практическое руководство, поэтому рекомендуется самостоятельно писать код, повторяя инструкции!
Чтобы разобраться со всем, необходимо…
- Установить Python3.7+, numpy и Pandas.
- Следующий шаг: подключиться к серверу (или локально) и запустить Jupyter. Затем открыть Jupyter Notebook в любимом браузере. Создайте новый ноутбук с именем «pandas_tutorial_1».
- Импортировать numpy и pandas в Jupyter Notebook с помощью двух строк кода:
import numpy as np import pandas as pd 
Примечание: к «pandas» можно обращаться с помощью аббревиатуры «pd». Если в конце инструкции с import есть as pd , Jupyter Notebook понимает, что в будущем, при вводе pd подразумевается именно библиотека pandas.
Теперь все настроено! Переходим к руководству по pandas! Первый вопрос:
Как открывать файлы с данными в pandas
Информация может храниться в файлах .csv или таблицах SQL. Возможно, в файлах Excel. Или даже файлах .tsv. Или еще в каком-то другом формате. Но цель всегда одна и та же. Если необходимо анализировать данные с помощью pandas, нужна структура данных, совместимая с pandas.
Структуры данных Python
В pandas есть два вида структур данных: Series и DataFrame.
Series в pandas — это одномерная структура данных («одномерная ndarray»), которая хранит данные. Для каждого значения в ней есть уникальный индекс.
DataFrame — двухмерная структура, состоящая из колонок и строк. У колонок есть имена, а у строк — индексы.
В руководстве по pandas основной акцент будет сделан на DataFrames. Причина проста: с большей частью аналитических методов логичнее работать в двухмерной структуре.
Загрузка файла .csv в pandas DataFrame
Для загрузки .csv файла с данными в pandas используется функция read_csv() .
Начнем с простого образца под названием zoo. В этот раз для практики вам предстоит создать файл .csv самостоятельно. Вот сырые данные:
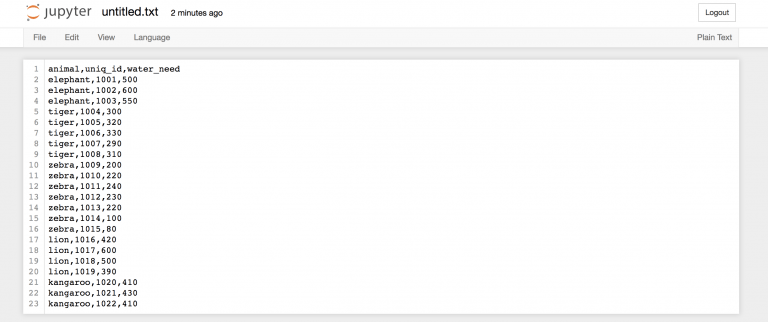
animal,uniq_id,water_need elephant,1001,500 elephant,1002,600 elephant,1003,550 tiger,1004,300 tiger,1005,320 tiger,1006,330 tiger,1007,290 tiger,1008,310 zebra,1009,200 zebra,1010,220 zebra,1011,240 zebra,1012,230 zebra,1013,220 zebra,1014,100 zebra,1015,80 lion,1016,420 lion,1017,600 lion,1018,500 lion,1019,390 kangaroo,1020,410 kangaroo,1021,430 kangaroo,1022,410 Вернемся во вкладку “Home” https://you_ip:you_port/tree Jupyter для создания нового текстового файла…
затем скопируем данные выше, чтобы вставить информацию в этот текстовый файл…
Вернемся в Jupyter Notebook (который называется «pandas_tutorial_1») и откроем в нем этот .csv файл!
Для этого нужна функция read_csv()
Введем следующее в новую строку:
pd.read_csv('zoo.csv', delimiter=',') 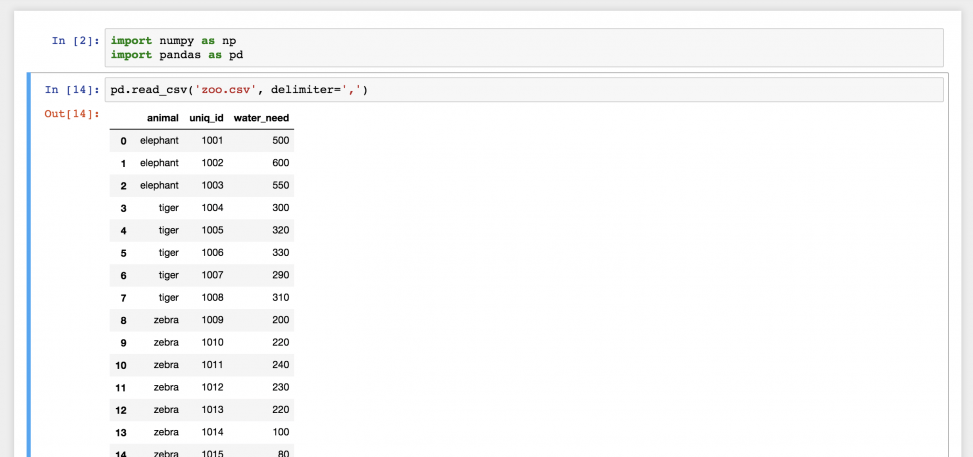
Готово! Это файл zoo.csv , перенесенный в pandas. Это двухмерная таблица — DataFrame. Числа слева — это индексы. А названия колонок вверху взяты из первой строки файла zoo.csv.
На самом деле, вам вряд ли придется когда-нибудь создавать .csv файл для себя, как это было сделано в примере. Вы будете использовать готовые файлы с данными. Поэтому нужно знать, как загружать их на сервер!
Вот небольшой набор данных: ДАННЫЕ
Если кликнуть на ссылку, файл с данными загрузится на компьютер. Но он ведь не нужен вам на ПК. Его нужно загрузить на сервер и потом в Jupyter Notebook. Для этого нужно всего два шага.
Шаг 1) Вернуться в Jupyter Notebook и ввести эту команду:
!wget https://pythonru.com/downloads/pandas_tutorial_read.csv Это загрузит файл pandas_tutorial_read.csv на сервер. Проверьте:
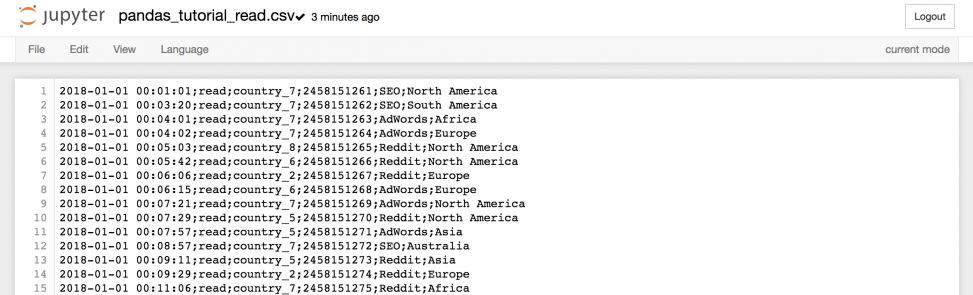
…можно получить всю информацию из файла.
Шаг 2) Вернуться в Jupyter Notebook и использовать ту же функцию read_csv (не забыв поменять имя файла и значение разделителя):
pd.read_csv('pandas_tutorial_read.csv', delimete=';') Данные загружены в pandas!
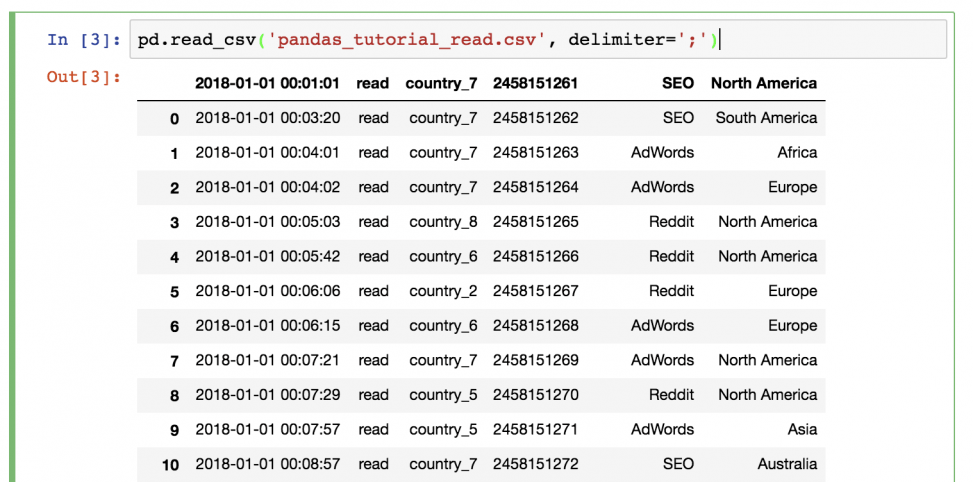
Что-то не так? В этот раз не было заголовка, поэтому его нужно настроить самостоятельно. Для этого необходимо добавить параметры имен в функцию!
pd.read_csv('pandas_tutorial_read.csv', delimiter=';', names=['my_datetime', 'event', 'country', 'user_id', 'source', 'topic']) 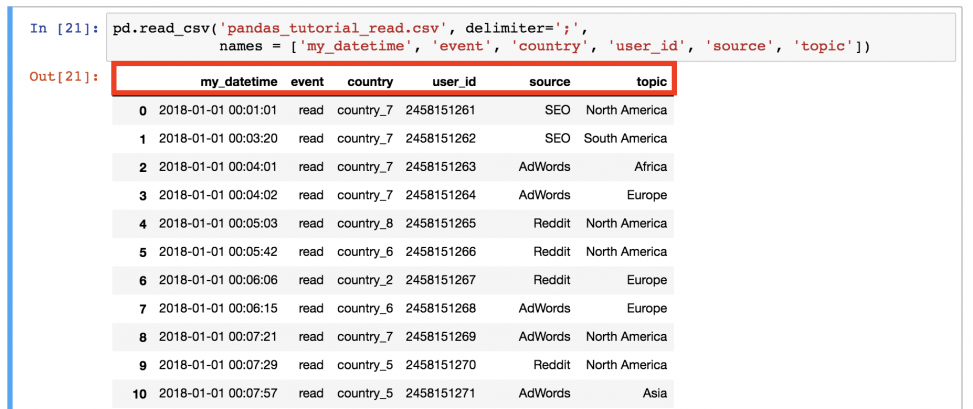
Так лучше!
Теперь файл .csv окончательно загружен в pandas DataFrame .
Примечание: есть альтернативный способ. Вы можете загрузить файл .csv через URL напрямую. В этом случае данные не загрузятся на сервер данных.
pd.read_csv( 'https://pythonru.com/downloads/pandas_tutorial_read.csv', delimiter=';', names=['my_datetime', 'event', 'country', 'user_id', 'source', 'topic'] ) Примечание: если вам интересно, что в этом наборе, то это лог данных из блога о путешествиях. Ну а названия колонок говорят сами за себя.
Отбор данных из dataframe в pandas
Это первая часть руководства, поэтому начнем с самых простых методов отбора данных, а уже в следующих углубимся и разберем более сложные.
Вывод всего dataframe
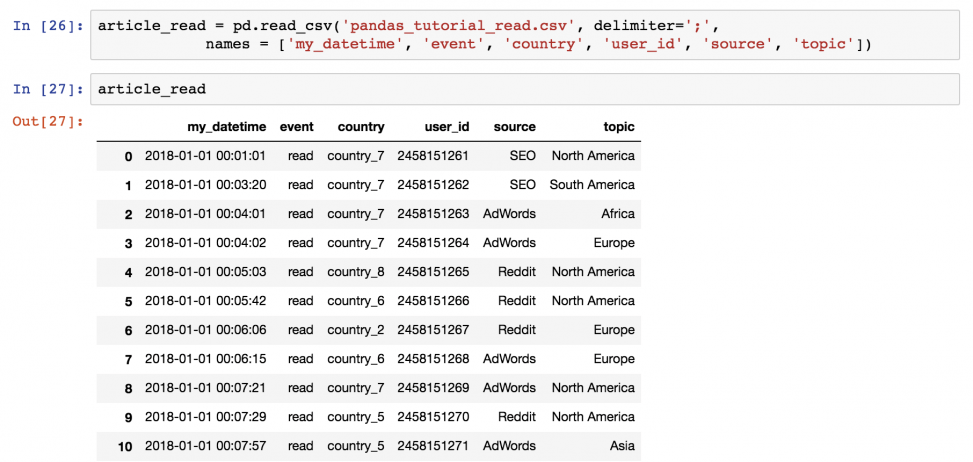
Базовый метод — вывести все данные из dataframe на экран. Для этого не придется запускать функцию pd.read_csv() снова и снова. Просто сохраните денные в переменную при чтении!
article_read = pd.read_csv( 'pandas_tutorial_read.csv', delimiter=';', names = ['my_datetime', 'event', 'country', 'user_id', 'source', 'topic'] ) После этого можно будет вызывать значение article_read каждый раз для вывода DataFrame!
Вывод части dataframe
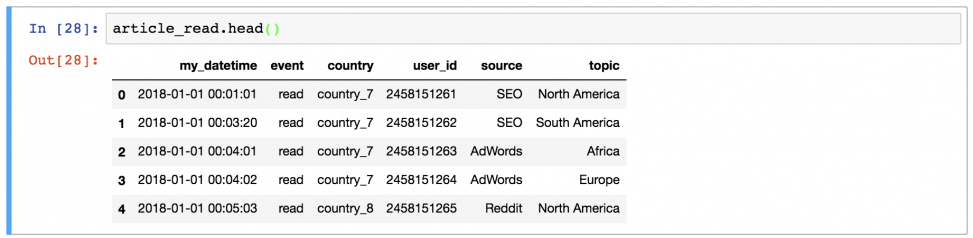
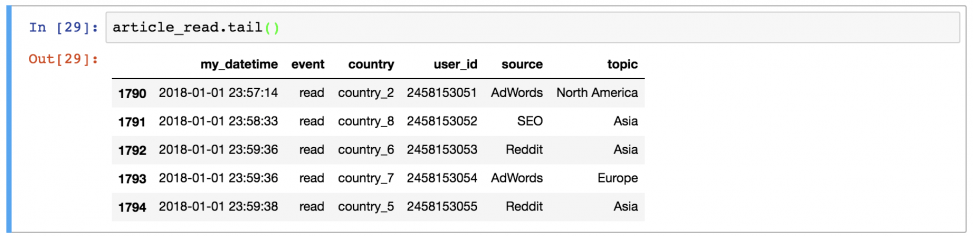
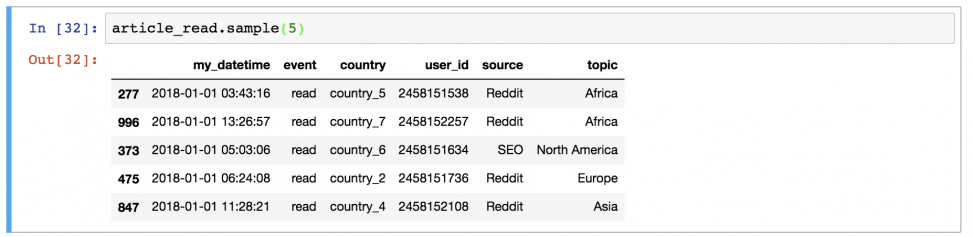
Иногда удобно вывести не целый dataframe, заполнив экран данными, а выбрать несколько строк. Например, первые 5 строк можно вывести, набрав:
Вывод определенных колонок из dataframe
А это уже посложнее! Предположим, что вы хотите вывести только колонки «country» и «user_id».
Для этого нужно использовать команду в следующем формате:
article_read[['country', 'user_id']] 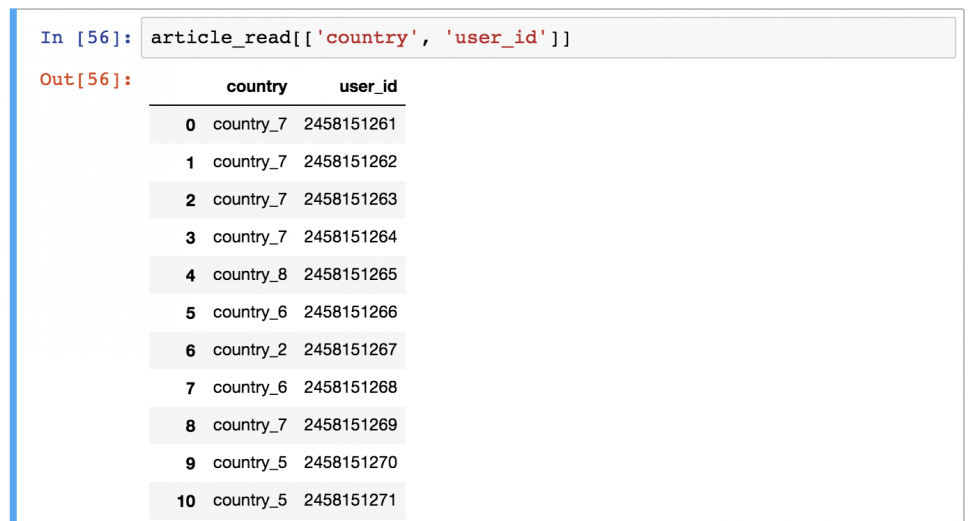
Есть предположения, почему здесь понадобились двойные квадратные скобки? Это может показаться сложным, но, возможно, так удастся запомнить: внешние скобки сообщают pandas, что вы хотите выбрать колонки, а внутренние — список (помните? Списки в Python указываются в квадратных скобках) имен колонок.
Поменяв порядок имен колонов, изменится и результат вывода.
Это DataFrame выбранных колонок.
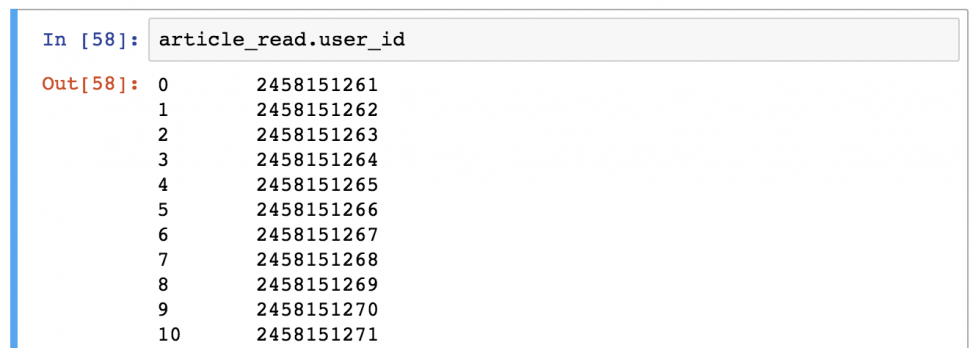
Примечание: иногда (особенно в проектах аналитического прогнозирования) нужно получить объекты Series вместе DataFrames. Это можно сделать с помощью одного из способов:
Фильтрация определенных значений в dataframe
Если прошлый шаг показался сложным, то этот будет еще сложнее!
Предположим, что вы хотите сохранить только тех пользователей, которые представлены в источнике «SEO». Для этого нужно отфильтровать по значению «SEO» в колонке «source»:
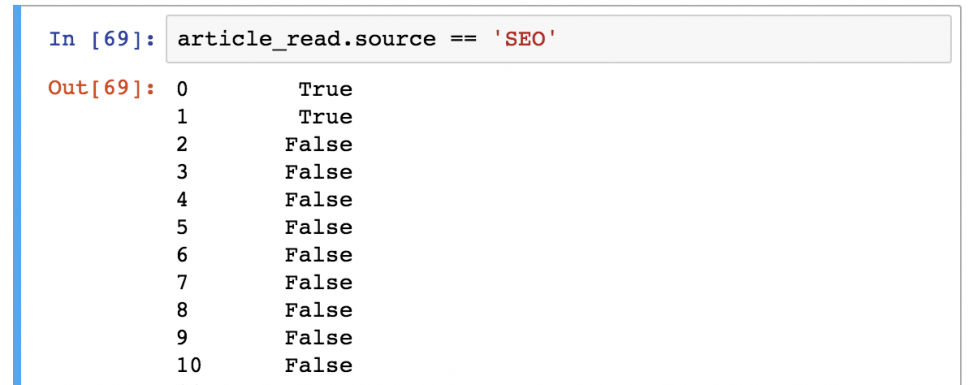
article_read[article_read.source == 'SEO'] Важно понимать, как pandas работает с фильтрацией данных:
Шаг 1) В первую очередь он оценивает каждую строчку в квадратных скобках: является ли ‘SEO’ значением колонки article_read.source ? Результат всегда будет булевым значением ( True или False ).
Шаг 2) Затем он выводит каждую строку со значением True из таблицы article_read .
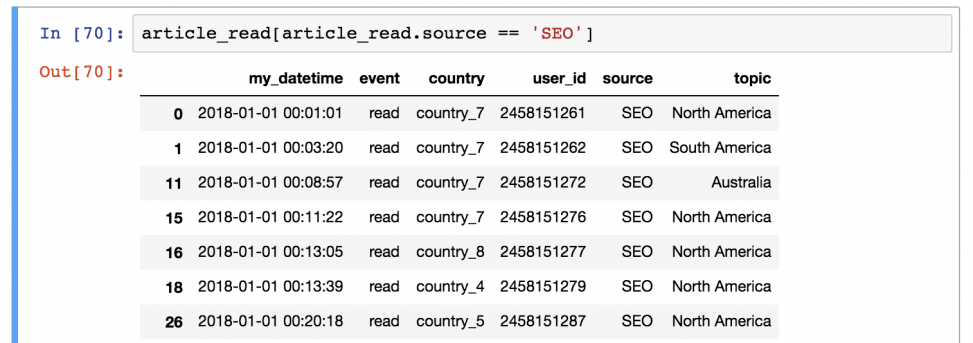
Выглядит сложно? Возможно. Но именно так это и работает, поэтому просто выучите, потому что пользоваться этим придется часто!
Функции могут использоваться одна за другой
Важно понимать, что логика pandas очень линейна (как в SQL, например). Поэтому если вы применяете функцию, то можете применить другую к ней же. В таком случае входящие данные последней функции будут выводом предыдущей.
Например, объединим эти два метода перебора:
article_read.head()[['country', 'user_id']] Первая строчка выбирает первые 5 строк из набора данных. Потом она выбирает колонки «country» и «user_id».
Можно ли получить тот же результат с иной цепочкой функций? Конечно:
article_read[['country', 'user_id']].head() В этом случае сначала выбираются колонки, а потом берутся первые 5 строк. Результат такой же — порядок функций (и их исполнение) отличается.
А что будет, если заменить значение «article_read» на оригинальную функцию read_csv():
pd.read_csv( 'pandas_tutorial_read.csv', delimiter=';', names = ['my_datetime', 'event', 'country', 'user_id', 'source', 'topic'] )[['country', 'user_id']].head() Так тоже можно, но это некрасиво и неэффективно. Важно понять, что работа с pandas — это применение функций и методов один за одним, и ничего больше.
Проверьте себя!
Как обычно, небольшой тест для проверки! Выполните его, чтобы лучше запомнить материал!
Выберите used_id , country и topic для пользователей из country_2 . Выведите первые 5 строк!
Его можно преподнести одной строкой:
article_read[article_read.country == 'country_2'][['user_id','topic', 'country']].head() Или, чтобы было понятнее, можно разбить на несколько строк:
ar_filtered = article_read[article_read.country == 'country_2'] ar_filtered_cols = ar_filtered[['user_id','topic', 'country']] ar_filtered_cols.head() В любом случае, логика не отличается. Сначала берется оригинальный dataframe ( article_read ), затем отфильтровываются строки со значением для колонки country — country_2 ( [article_read.country == ‘country_2’] ). Потому берутся три нужные колонки ( [[‘user_id’, ‘topic’, ‘country’]] ) и в конечном итоге выбираются только первые пять строк ( .head() ).
Итого
Вот и все. В следующей статье вы узнаете больше о разных методах агрегации (например, sum, mean, max, min) и группировки.
Import CSV file as a Pandas DataFrame
To read a CSV file as a pandas DataFrame, you’ll need to use pd.read_csv , which has sep=’,’ as the default.
But this isn’t where the story ends; data exists in many different formats and is stored in different ways so you will often need to pass additional parameters to read_csv to ensure your data is read in properly.
Here’s a table listing common scenarios encountered with CSV files along with the appropriate argument you will need to use. You will usually need all or some combination of the arguments below to read in your data.
┌───────────────────────────────────────────────────────┬───────────────────────┬────────────────────────────────────────────────────┐ │ pandas Implementation │ Argument │ Description │ ├───────────────────────────────────────────────────────┼───────────────────────┼────────────────────────────────────────────────────┤ │ pd.read_csv(. sep=';') │ sep/delimiter │ Read CSV with different separator¹ │ │ pd.read_csv(. delim_whitespace=True) │ delim_whitespace │ Read CSV with tab/whitespace separator │ │ pd.read_csv(. encoding='latin-1') │ encoding │ Fix UnicodeDecodeError while reading² │ │ pd.read_csv(. header=False, names=['x', 'y', 'z']) │ header and names │ Read CSV without headers³ │ │ pd.read_csv(. index_col=[0]) │ index_col │ Specify which column to set as the index⁴ │ │ pd.read_csv(. usecols=['x', 'y']) │ usecols │ Read subset of columns │ │ pd.read_csv(. thousands='.', decimal=',') │ thousands and decimal │ Numeric data is in European format (eg., 1.234,56) │ └───────────────────────────────────────────────────────┴───────────────────────┴────────────────────────────────────────────────────┘ - By default, read_csv uses a C parser engine for performance. The C parser can only handle single character separators. If your CSV has a multi-character separator, you will need to modify your code to use the ‘python’ engine. You can also pass regular expressions:
df = pd.read_csv(. sep=r'\s*\|\s*', engine='python') There are other arguments I’ve not mentioned here, but these are the ones you’ll encounter most frequently.