- How to Normalize Column or DataFrame in Pandas
- Setup
- 1: Min Max normalization in Pandas
- Single column
- All columns
- 2: Mean normalization in Pandas
- Single column
- All columns
- 3: Biased normalization in Pandas
- 4: Normalize rows in Pandas
- Normalize rows by their sum
- Transpose
- Conclusion
- 2 простых способа нормализовать данные в Python
- Почему нам нужно нормализовать данные в Python?
- Использование MinMaxScaler() для нормализации данных в Python
- Как нормализовать столбцы в Pandas DataFrame
- Пример 1: Мин-макс нормализация
- Пример 2: Нормализация среднего
How to Normalize Column or DataFrame in Pandas
In this tutorial, we’ll learn how to normalize columns or the whole DataFrame in Pandas. We will show different ways like:
(1) Min Max normalization
(2) Mean normalization
(3) biased normalization
scaler.fit_transform(df.iloc[. ].to_numpy()) Let’s cover all examples in more detail.
Setup
For this post we are creating example DataFrame with 3 numeric columns:
import pandas as pd data = df = pd.DataFrame(data=data) | day | temp | humidity | |
|---|---|---|---|
| 0 | 1 | 9 | 0.89 |
| 1 | 2 | 8 | 0.86 |
| 2 | 3 | 6 | 0.54 |
| 3 | 4 | 13 | 0.73 |
| 4 | 5 | 10 | 0.45 |
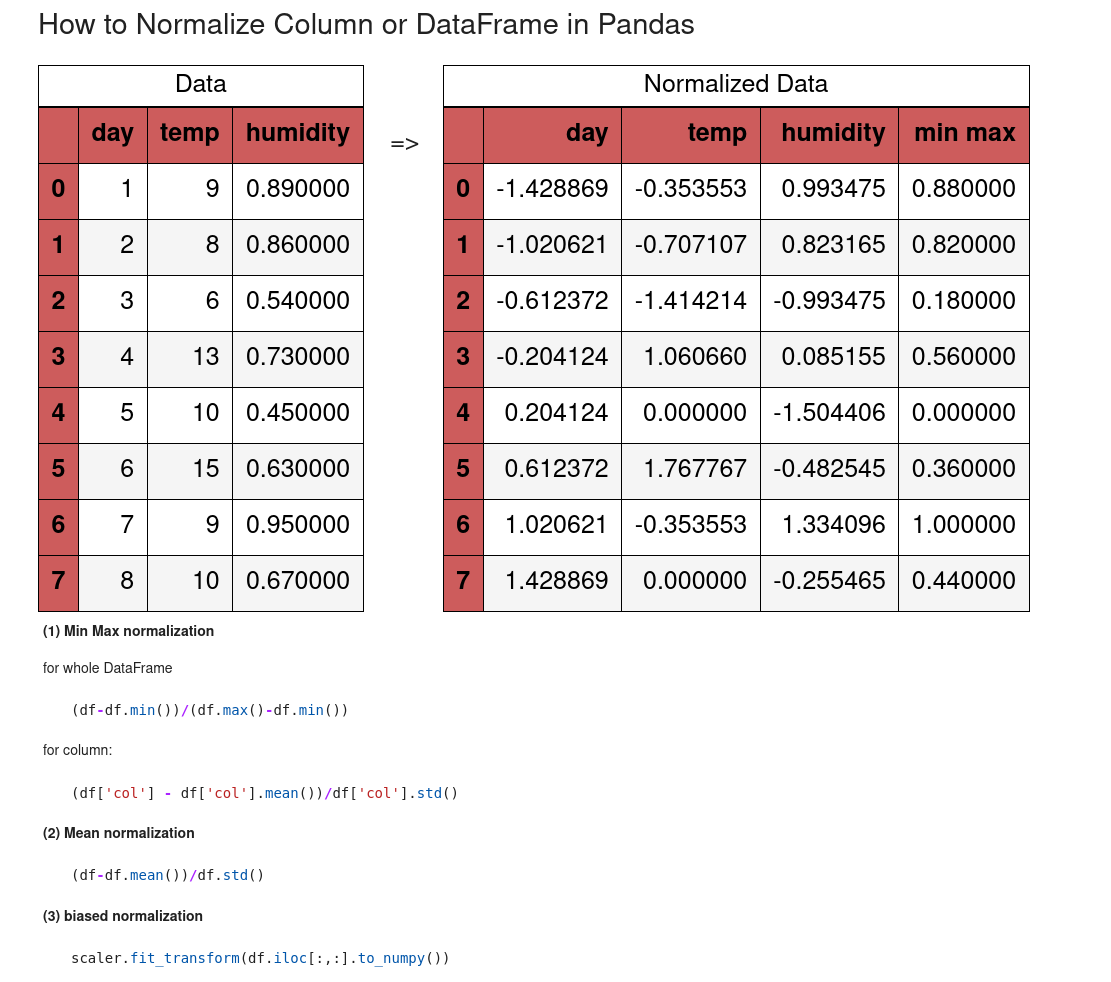
1: Min Max normalization in Pandas
So let’s start by min max normalization (called also min max scaling) in Pandas and Python.
Single column
To do min max scaling for a single column we can do:
(df['humidity']-df['humidity'].min())/(df['humidity'].max()-df['humidity'].min()) The result is normalized Series:
0 0.88 1 0.82 2 0.18 3 0.56 4 0.00 5 0.36 6 1.00 7 0.44 Name: humidity, dtype: float64 Checking data next to the original column:
| humidity_norm | humidity | |
|---|---|---|
| 0 | 0.88 | 0.89 |
| 1 | 0.82 | 0.86 |
| 2 | 0.18 | 0.54 |
| 3 | 0.56 | 0.73 |
| 4 | 0.00 | 0.45 |
All columns
To normalize all columns of a DataFrame we can use:
| day | temp | humidity | |
|---|---|---|---|
| 0 | 0.000000 | 0.333333 | 0.88 |
| 1 | 0.142857 | 0.222222 | 0.82 |
| 2 | 0.285714 | 0.000000 | 0.18 |
| 3 | 0.428571 | 0.777778 | 0.56 |
| 4 | 0.571429 | 0.444444 | 0.00 |
2: Mean normalization in Pandas
Next we can see how to do mean normalization in Pandas and Python.
Single column
For a single column we can apply mean normalization by:
(df['humidity'] - df['humidity'].mean())/df['humidity'].std() The result and the original values:
| humidity_norm | humidity | |
|---|---|---|
| 0 | 0.993475 | 0.89 |
| 1 | 0.823165 | 0.86 |
| 2 | -0.993475 | 0.54 |
| 3 | 0.085155 | 0.73 |
| 4 | -1.504406 | 0.45 |
All columns
To normalize the whole DataFrame with mean normalization we can do:
| day | temp | humidity | |
|---|---|---|---|
| 0 | -1.428869 | -0.353553 | 0.993475 |
| 1 | -1.020621 | -0.707107 | 0.823165 |
| 2 | -0.612372 | -1.414214 | -0.993475 |
| 3 | -0.204124 | 1.060660 | 0.085155 |
| 4 | 0.204124 | 0.000000 | -1.504406 |
3: Biased normalization in Pandas
To perform biased normalization in Pandas we can use the library sklearn . The results will differ from the Pandas normalization.
import pandas as pd from sklearn.preprocessing import StandardScaler scaler = StandardScaler() scaler.fit_transform(df.to_numpy()) | 0 | 1 | 2 | |
|---|---|---|---|
| 0 | -1.527525 | -0.377964 | 1.062070 |
| 1 | -1.091089 | -0.755929 | 0.880001 |
| 2 | -0.654654 | -1.511858 | -1.062070 |
| 3 | -0.218218 | 1.133893 | 0.091035 |
| 4 | 0.218218 | 0.000000 | -1.608277 |
4: Normalize rows in Pandas
There are multiple ways to normalize rows:
Normalize rows by their sum
To normalize row based on the sum of the row in Pandas we can do:
| day | temp | humidity | |
|---|---|---|---|
| 0 | 0.091827 | 0.826446 | 0.081726 |
| 1 | 0.184162 | 0.736648 | 0.079190 |
| 2 | 0.314465 | 0.628931 | 0.056604 |
| 3 | 0.225606 | 0.733221 | 0.041173 |
| 4 | 0.323625 | 0.647249 | 0.029126 |
Transpose
To normalize row wise in Pandas we can combine:
import pandas as pd from sklearn import preprocessing data = df.T.values scaler = preprocessing.MinMaxScaler() pd.DataFrame(scaler.fit_transform(data)).T So after using df.values we get:
array([[0.0135635 , 1. , 0. ], [0.15966387, 1. , 0. ], [0.45054945, 1. , 0. ], [0.26650367, 1. , 0. ], [0.47643979, 1. , 0. ], [0.3736952 , 1. , 0. ], [0.7515528 , 1. , 0. ], [0.78563773, 1. , 0. ]]) array([[0. , 0.33333333, 0.88 ], [0.14285714, 0.22222222, 0.82 ], [0.28571429, 0. , 0.18 ], [0.42857143, 0.77777778, 0.56 ], [0.57142857, 0.44444444, 0. ], [0.71428571, 1. , 0.36 ], [0.85714286, 0.33333333, 1. ], [1. , 0.44444444, 0.44 ]]) Conclusion
In this article we learned how to normalize columns and DataFrame in Pandas. Different ways of normalization were covered like — biased, unbiased, normalization per sum.
We also saw how to normalize rows of a DataFrame. Normalizing data is very useful in machine learning and visualizing data.
By using DataScientYst — Data Science Simplified, you agree to our Cookie Policy.
2 простых способа нормализовать данные в Python
В этом руководстве мы узнаем, как нормализовать данные в Python. При нормализации меняем масштаб данных. Чаще всего масштабирование данных изменяется в диапазоне от 0 до 1.
Почему нам нужно нормализовать данные в Python?
Алгоритмы машинного обучения, как правило, работают лучше или сходятся быстрее, когда различные функции (переменные) имеют меньший масштаб. Поэтому перед обучением на них моделей машинного обучения данные обычно нормализуются.
Нормализация также делает процесс обучения менее чувствительным к масштабу функций. Это приводит к улучшению коэффициентов после тренировки.
Этот процесс повышения пригодности функций для обучения путем изменения масштаба называется масштабированием функций.
Формула нормализации приведена ниже:
![Нормализация</p></noscript><p>»/></p><p>Мы вычитаем минимальное значение из каждой записи, а затем делим результат на диапазон. Где диапазон — это разница между максимальным значением и минимальным значением.</p><h2>Шаги по нормализации данных в Python</h2><p>Мы собираемся обсудить два разных способа нормализации данных в Python.</p><p>Первый — с помощью метода normalize() в sklearn.</p><h3>Использование normalize() из sklearn</h3><p>Начнем с импорта processing из sklearn.</p><pre><code >from sklearn import preprocessing</code> </pre><p>Теперь давайте создадим массив с помощью Numpy .</p><pre><code >import numpy as np x_array = np.array([2,3,5,6,7,4,8,7,6])</code> </pre><p>Теперь мы можем использовать метод normalize() для массива. Этот метод нормализует данные по строке. Давайте посмотрим на метод в действии.</p><pre><code >normalized_arr = preprocessing.normalize([x_array]) print(normalized_arr)</code> </pre><h3>Полный код</h3><p>Вот полный код из этого раздела:</p><pre><code >from sklearn import preprocessing import numpy as np x_array = np.array([2,3,5,6,7,4,8,7,6]) normalized_arr = preprocessing.normalize([x_array]) print(normalized_arr)</code> </pre><pre><code >[0.11785113, 0.1767767 , 0.29462783, 0.35355339, 0.41247896, 0.23570226, 0.47140452, 0.41247896, 0.35355339]</code> </pre><p>Мы видим, что все значения теперь находятся в диапазоне от 0 до 1. Так работает метод normalize() в sklearn.</p><p>Вы также можете нормализовать столбцы в наборе данных, используя этот метод.</p><h3>Нормализовать столбцы в наборе данных с помощью normalize()</h3><p>Поскольку normalize() нормализует только значения по строкам, нам нужно преобразовать столбец в массив, прежде чем применять метод.</p><p>Чтобы продемонстрировать, мы собираемся использовать набор данных California Housing.</p><p>Начнем с импорта набора данных.</p><pre><code >import pandas as pd housing = pd.read_csv(](https://dev-gang.ru/static/storage/37403660903642076772234929412457116574.png)



