- Handling encoding and decoding errors in Python
- Codecs
- What happens when a codec operation fails?
- How can I deal with codec operation failures?
- In conclusion.
- Функции encode() и decode() в Python
- encode заданной строки
- Обработка ошибок
- Декодирование потока байтов
- Важность кодировки
- Python ignore encoding errors
- # UnicodeDecodeError: ‘ascii’ codec can’t decode byte
- # Try setting the encoding to utf-8
- # Set the errors keyword argument to ignore
- # Make sure you aren’t mixing up encode() and decode()
- # Discussion
Handling encoding and decoding errors in Python
This week’s blog post is about handling errors when encoding and decoding data. You will learn 6 different ways to handle these errors, ranging from strictly requiring all data to be valid, to skipping over malformed data.
Codecs
- Encode str objects into bytes objects.
"小島 秀夫 (Hideo Kojima)".encode("shift_jis") b'\x8f\xac\x93\x87 \x8fG\x95v (Hideo Kojima)' b"\x8f\xac\x93\x87 \x8fG\x95v (Hideo Kojima)".decode("shift_jis") (Shift JIS is a codec for the Japanese language.)
What happens when a codec operation fails?
When a codec operation encounters malformed data, that’s an error:
"小島 秀夫 (Hideo Kojima)".encode("ascii") UnicodeEncodeError: 'ascii' codec can't encode characters in position 0-1: ordinal not in range(128) b"\x8f\xac\x93\x87 \x8fG\x95v (Hideo Kojima)".decode("ascii") UnicodeDecodeError: 'ascii' codec can't decode byte 0x8f in position 0: ordinal not in range(128) How can I deal with codec operation failures?
Besides raising a UnicodeError exception, there are 5 other ways to deal with codec operation errors:
- When encoding and decoding, ignore malformed data:
"小島 秀夫 (Hideo Kojima)".encode("ascii", errors="ignore") b"\x8f\xac\x93\x87 \x8fG\x95v (Hideo Kojima)".decode("ascii", errors="ignore") "小島 秀夫 (Hideo Kojima)".encode("ascii", errors="replace") b"\x8f\xac\x93\x87 \x8fG\x95v (Hideo Kojima)".decode("ascii", errors="replace") "小島 秀夫 (Hideo Kojima)".encode("ascii", errors="backslashreplace") b'\\u5c0f\\u5cf6 \\u79c0\\u592b (Hideo Kojima)' b"\x8f\xac\x93\x87 \x8fG\x95v (Hideo Kojima)".decode("ascii", errors="backslashreplace") '\\x8f\\xac\\x93\\x87 \\x8fG\\x95v (Hideo Kojima)' "小島 秀夫 (Hideo Kojima)".encode("ascii", errors="xmlcharrefreplace") "小島 秀夫 (Hideo Kojima)".encode("ascii", errors="namereplace") (There is another error handler, «surrogateescape» , that is out of the scope of this blog post.)
Different error handling strategies are useful in different contexts. Here’s a table of the 6 different errors handlers:
«strict» is the default error handler.
Besides str.encode and bytes.decode, error handling is available .
- With the built-in function open.
- With the pathlib module functions Path.open and Path.read_text.
- With the codecs module functions and classes decode, encode, open, EncodedFile, iterencode, iterdecode, Codec.encode, Codec.decode, IncrementalEncoder, IncrementalDecoder, StreamWriter, Stream.Reader, StreamReaderWriter, and StreamRecoder.
- With the io module functions and classes open, and TextIOWrapper.
In conclusion.
In this post you learned 6 different ways to handle codec operation errors. The default strategy ( errors=»strict» ) raises an exception when an error occurs. But, sometimes you want your program to continue processing data, either by omitting bad data ( errors=»ignore» ) or by replacing bad data with replacement characters ( errors=»replace» ). If you are generating a HTML or an XML document, you can replace malformed data with XML character references ( errors=»xmlcharrefreplace» ).
This post discussed 6 different ways to handle codec operation errors. There is another way, «surrogateescape» . Learn how to use «surrogateescape» and create an example of decoding-then-encoding a file using it.
If you enjoyed this week’s post, share it with you friends and stay tuned for next week’s post. See you then!
Copyright © 2021 John Lekberg
Функции encode() и decode() в Python
Методы encode и decode Python используются для кодирования и декодирования входной строки с использованием заданной кодировки. Давайте подробно рассмотрим эти две функции.
encode заданной строки
Мы используем метод encode() для входной строки, который есть у каждого строкового объекта.
input_string.encode(encoding, errors)
Это кодирует input_string с использованием encoding , где errors определяют поведение, которому надо следовать, если по какой-либо случайности кодирование строки не выполняется.
encode() приведет к последовательности bytes .
inp_string = 'Hello' bytes_encoded = inp_string.encode() print(type(bytes_encoded))
Как и ожидалось, в результате получается объект :
Тип кодирования, которому надо следовать, отображается параметром encoding . Существуют различные типы схем кодирования символов, из которых в Python по умолчанию используется схема UTF-8.
Рассмотрим параметр encoding на примере.
a = 'This is a simple sentence.' print('Original string:', a) # Decodes to utf-8 by default a_utf = a.encode() print('Encoded string:', a_utf) Original string: This is a simple sentence. Encoded string: b'This is a simple sentence.'
Как вы можете заметить, мы закодировали входную строку в формате UTF-8. Хотя особой разницы нет, вы можете заметить, что строка имеет префикс b . Это означает, что строка преобразуется в поток байтов.
На самом деле это представляется только как исходная строка для удобства чтения с префиксом b , чтобы обозначить, что это не строка, а последовательность байтов.
Обработка ошибок
Существуют различные типы errors , некоторые из которых указаны ниже:
| Тип ошибки | Поведение |
| strict | Поведение по умолчанию, которое вызывает UnicodeDecodeError при сбое. |
| ignore | Игнорирует некодируемый Unicode из результата. |
| replace | Заменяет все некодируемые символы Юникода вопросительным знаком (?) |
| backslashreplace | Вставляет escape-последовательность обратной косой черты (\ uNNNN) вместо некодируемых символов Юникода. |
Давайте посмотрим на приведенные выше концепции на простом примере. Мы рассмотрим входную строку, в которой не все символы кодируются (например, ö ),
a = 'This is a bit möre cömplex sentence.' print('Original string:', a) print('Encoding with errors=ignore:', a.encode(encoding='ascii', errors='ignore')) print('Encoding with errors=replace:', a.encode(encoding='ascii', errors='replace')) Original string: This is a möre cömplex sentence. Encoding with errors=ignore: b'This is a bit mre cmplex sentence.' Encoding with errors=replace: b'This is a bit m?re c?mplex sentence.'
Декодирование потока байтов
Подобно кодированию строки, мы можем декодировать поток байтов в строковый объект, используя функцию decode() .
encoded = input_string.encode() # Using decode() decoded = encoded.decode(decoding, errors)
Поскольку encode() преобразует строку в байты, decode() просто делает обратное.
byte_seq = b'Hello' decoded_string = byte_seq.decode() print(type(decoded_string)) print(decoded_string)
Это показывает, что decode() преобразует байты в строку Python.
Подобно параметрам encode() , параметр decoding определяет тип кодирования, из которого декодируется последовательность байтов. Параметр errors обозначает поведение в случае сбоя декодирования, который имеет те же значения, что и у encode() .
Важность кодировки
Поскольку кодирование и декодирование входной строки зависит от формата, мы должны быть осторожны при этих операциях. Если мы используем неправильный формат, это приведет к неправильному выводу и может вызвать ошибки.
Первое декодирование неверно, так как оно пытается декодировать входную строку, которая закодирована в формате UTF-8. Второй правильный, поскольку форматы кодирования и декодирования совпадают.
a = 'This is a bit möre cömplex sentence.' print('Original string:', a) # Encoding in UTF-8 encoded_bytes = a.encode('utf-8', 'replace') # Trying to decode via ASCII, which is incorrect decoded_incorrect = encoded_bytes.decode('ascii', 'replace') decoded_correct = encoded_bytes.decode('utf-8', 'replace') print('Incorrectly Decoded string:', decoded_incorrect) print('Correctly Decoded string:', decoded_correct) Original string: This is a bit möre cömplex sentence. Incorrectly Decoded string: This is a bit m��re c��mplex sentence. Correctly Decoded string: This is a bit möre cömplex sentence.
Python ignore encoding errors
Last updated: Feb 18, 2023
Reading time · 3 min

# UnicodeDecodeError: ‘ascii’ codec can’t decode byte
The Python «UnicodeDecodeError: ‘ascii’ codec can’t decode byte in position» occurs when we use the ascii codec to decode bytes that were encoded using a different codec.
To solve the error, specify the correct encoding, e.g. utf-8 .
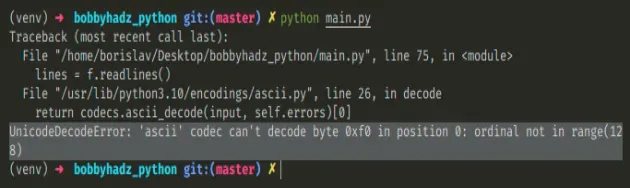
Here is an example of how the error occurs.
I have a file called example.txt with the following contents.
Copied!𝘈Ḇ𝖢𝕯٤ḞԍНǏ hello world
And here is the code that tries to decode the contents of example.txt using the ascii codec.
Copied!# ⛔️ UnicodeDecodeError: 'ascii' codec can't decode byte 0xf0 in position 0: ordinal not in range(128) with open('example.txt', 'r', encoding='ascii') as f: lines = f.readlines() print(lines)
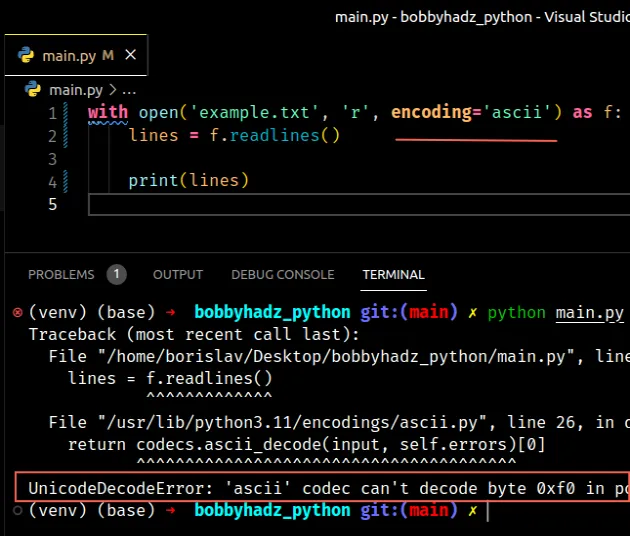
The error is caused because the example.txt file doesn’t use the ascii encoding.
Copied!𝘈Ḇ𝖢𝕯٤ḞԍНǏ hello world
If you know the encoding the file uses, make sure to specify it using the encoding keyword argument.
# Try setting the encoding to utf-8
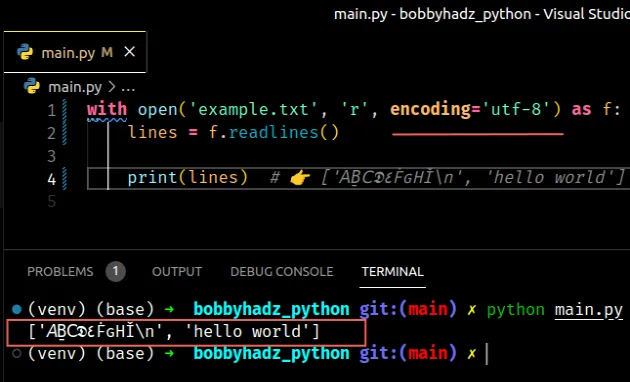
Otherwise, the first thing you can try is setting the encoding to utf-8 .
Copied!# 👇️ set encoding to utf-8 with open('example.txt', 'r', encoding='utf-8') as f: lines = f.readlines() print(lines) # 👉️ ['𝘈Ḇ𝖢𝕯٤ḞԍНǏ\n', 'hello world']
You can view all of the standard encodings in this table of the official docs.
Encoding is the process of converting a string to a bytes object and decoding is the process of converting a bytes object to a string .
When decoding a bytes object, we have to use the same encoding that was used to encode the string to a bytes object.
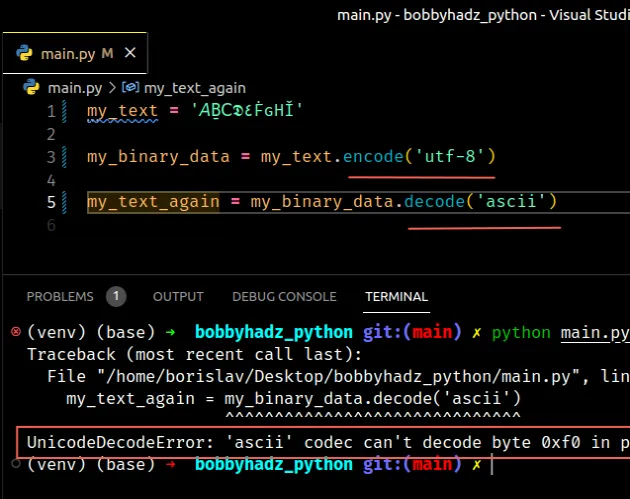
Here is an example that shows how using a different encoding to encode a string to bytes than the one used to decode the bytes object causes the error.
Copied!my_text = '𝘈Ḇ𝖢𝕯٤ḞԍНǏ' my_binary_data = my_text.encode('utf-8') # ⛔️ UnicodeDecodeError: 'ascii' codec can't decode byte 0xf0 in position 0: ordinal not in range(128) my_text_again = my_binary_data.decode('ascii')
We can solve the error by using the utf-8 encoding to decode the bytes object.
Copied!my_text = '𝘈Ḇ𝖢𝕯٤ḞԍНǏ' my_binary_data = my_text.encode('utf-8') # 👉️ b'\xf0\x9d\x98\x88\xe1\xb8\x86\xf0\x9d\x96\xa2\xf0\x9d\x95\xaf\xd9\xa4\xe1\xb8\x9e\xd4\x8d\xd0\x9d\xc7\x8f' print(my_binary_data) # ✅ specify correct encoding my_text_again = my_binary_data.decode('utf-8') print(my_text_again) # 👉️ '𝘈Ḇ𝖢𝕯٤ḞԍНǏ'
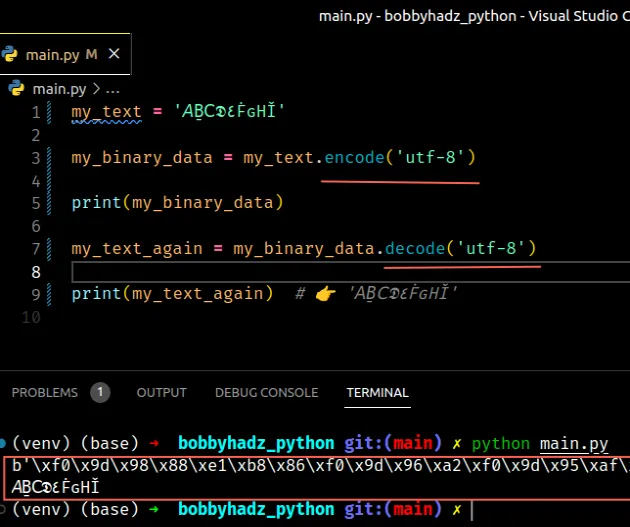
The code sample doesn’t cause an issue because the same encoding was used to encode the string into bytes and decode the bytes object into a string.
# Set the errors keyword argument to ignore
If you get an error when decoding the bytes using the utf-8 encoding, you can try setting the errors keyword argument to ignore to ignore the characters that cannot be decoded.
Copied!my_text = '𝘈Ḇ𝖢𝕯٤ḞԍНǏ' my_binary_data = my_text.encode('utf-8') # 👇️ set errors to ignore my_text_again = my_binary_data.decode('utf-8', errors='ignore') print(my_text_again)
Note that ignoring characters that cannot be decoded can lead to data loss.
Here is an example where errors is set to ignore when opening a file.
Copied!# 👇️ set errors to ignore with open('example.txt', 'r', encoding='utf-8', errors='ignore') as f: lines = f.readlines() # ✅ ['𝘈Ḇ𝖢𝕯٤ḞԍНǏ\n', 'hello world'] print(lines)
Opening the file with an incorrect encoding with errors set to ignore won’t raise an error.
Copied!with open('example.txt', 'r', encoding='ascii', errors='ignore') as f: lines = f.readlines() # ✅ ['\n', 'hello world'] print(lines)
The example.txt file doesn’t use the ascii encoding, however, opening the file with errors set to ignore doesn’t raise an error.
Copied!𝘈Ḇ𝖢𝕯٤ḞԍНǏ hello world
Instead, it ignores the data it cannot parse and returns the data it can parse.
# Make sure you aren’t mixing up encode() and decode()
Make sure you aren’t mixing up calls to the str.encode() and bytes.decode() method.
Encoding is the process of converting a string to a bytes object and decoding is the process of converting a bytes object to a string .
If you have a str that you want to convert to bytes, use the encode() method.
Copied!my_text = '𝘈Ḇ𝖢𝕯٤ḞԍНǏ' my_binary_data = my_text.encode('utf-8') # 👉️ b'\xf0\x9d\x98\x88\xe1\xb8\x86\xf0\x9d\x96\xa2\xf0\x9d\x95\xaf\xd9\xa4\xe1\xb8\x9e\xd4\x8d\xd0\x9d\xc7\x8f' print(my_binary_data) # ✅ specify correct encoding my_text_again = my_binary_data.decode('utf-8') print(my_text_again) # 👉️ '𝘈Ḇ𝖢𝕯٤ḞԍНǏ'
If you have a bytes object that you need to convert to a string, use the decode() method.
Make sure to specify the same encoding in the call to the str.encode() and bytes.decode() methods.
# Discussion
The default encoding in Python 3 is utf-8 .
Python 3 no longer has the concept of Unicode like Python 2 did.
Instead, Python 3 supports strings and bytes objects.
Using the ascii encoding to decode a bytes object that was encoded in a different encoding causes the error.
I wrote a book in which I share everything I know about how to become a better, more efficient programmer.