- Write csv with a comma as decimal separator in python
- Write csv with a comma as decimal separator in python
- Pandas reading a csv with decimal separator comma is not changing all values
- Pandas read_csv: decimal and delimiter is the same character
- How to Convert Decimal Comma to Decimal Point in Pandas DataFrame
- Setup
- 1: read_csv — decimal point vs comma
- 2: Convert comma to point
- 3: Mixed decimal data — point and comma
- 4: Detect decimal comma in mixed column
- 5: to_csv — decimal point vs comma
- ValueError: could not convert string to float: ‘0,89’
- ValueError: Unable to parse string «0,89» at position 0
- Conclusion
- Python – How to write a csv with a comma as the decimal separator
- Best Solution
- Related Solutions
Write csv with a comma as decimal separator in python
The problem is, that in the csv file a comma is used both as decimal point and as separator for columns. I must somehow tell pandas, that the first comma in line is the decimal point, and the second one is the separator.
Write csv with a comma as decimal separator in python
How can I write a csv file in Python with comma as a decimal separator? This problem looks simple, but I’ve been spending many hours today and can’t solve it (googleing, search here in stackoverflow. ).
file.to_csv(‘file.csv’, index = False, sep = «;», float_format = «,»)
Thank you for your answer.
You can save with commma directly using decimal= «,» . This is especified in pandas. dataf rame.to_csv() documentation.
The following code should work:
file.to_csv('file.csv', index = False, sep = ";", decimal= ",") You can take advantage of the pandas to_csv method and use the decimal parameter to designate the comman «,» as decimal separator .
Given the following code you posted the following should work:
import pandas as pd data = pd.read_csv(r'file.csv', sep = ',', decimal = '.') data.to_csv('foo.csv', decimal = ',', sep = ';', index = False) import pandas as pd import numpy as np data = pd.read_csv(r'data.csv', decimal = ',') dims = data.columns[0:3] metrics = data.columns[3:] dims = data[dims].copy() metrics = data[dims].copy() dtypes=np.dtype([ ('col1',str), ('col2',str), ('col3',str), ('col4',int), ('col5',int)]) dataf = np.empty(0,dtype=dtypes) df = pd.DataFrame(dataf) data = pd.DataFrame(< "col1": dims["col1"], "col2": dims["col2"], "col3": dims["col3"], "col4": dims["col4"], "col4": dims["col4"]>) df = df.append(data) df[['col1', 'col2', 'col3']] = df[['col1', 'col2', 'col3']].replace('\;', ',', regex = True) df[['col4', 'col5']] = df[['col4', 'col5']].replace('\.', ',', regex = True) df = df.applymap(str) df.to_csv('new_file.csv', index = False) My code (I need only read csv with decimas as «.» and save with «,»):
import pandas as pd file = pd.read_csv(r'file.csv', decimal = ',') file = file.copy().replace(".", ",") file.to_csv('file_updated.csv', index = False, sep = ";", decimal = ",") Writing pandas dataframe to CSV with decimal places, Function — this function takes a dataframe ( df ) strips out any rows that don’t meet a criteria and write the df to a .csv . Importantly, I
Pandas reading a csv with decimal separator comma is not changing all values
I have a CSV file with a column KG and it is specified with a decimal separator as «,»(comma).
KG 267,890 458,987 125,888 1,55 2,66 When I use pd.read_csv(file_name,sep=’;’, decimal=»,») , only the values 1,55 and 2,66 are converted to 1.55 and 2.66 respectively. the vales with 3 digits before the comma stay the same.
This is the output
KG 267,890 458,987 125,888 1.55 2.66 Please can someone guide me through how to change all values to have a dot, as well to use dtype as float64 for the column
It Worked fine for me. I wrote the same code and worked.
>>> df = pd.read_csv("/Users/SO/Desktop/test.csv",sep=';', decimal=",") >>> df KG, 0 267.890 1 458.987 2 125.888 3 1.550 4 2.660 >>> This solution helped me, though I don’t understand why I did not get the other way working
f = lambda ****.replace(",",".")) input_df = pd.read_csv(file_name, sep=";",converters = ) Pandas DataFrame to csv: Specifying decimal separator for mixed type, Use applymap and cast the float typed cells to str by checking explicitly for their type. Then, replace the decimal dot (.) with the comma (
Pandas read_csv: decimal and delimiter is the same character
Recently I’m struggling to read an csv file with pandas pd.read_csv. The problem is, that in the csv file a comma is used both as decimal point and as separator for columns. The csv looks as follows:
wavelength,intensity 390,0,382 390,1,390 390,2,400 390,3,408 390,4,418 390,5,427 390,6,437 390,7,447 390,8,457 390,9,468 Pandas accordingly always splits the data into three separate columns . However the first comma is only the decimal point. I want to plot it with the wavelength (x-axis) with 390.0 , 390.1 , 390.2 nm and so on.
I must somehow tell pandas, that the first comma in line is the decimal point, and the second one is the separator. How do I do this?
I’m not sure that this is possible. It almost is, as you can see by the following example:
>>> pd.read_csv('test.csv', engine='python', sep=r',(?!\d+$)') wavelength intensity 0 390 0,382 1 390 1,390 2 390 2,400 3 390 3,408 4 390 4,418 5 390 5,427 6 390 6,437 7 390 7,447 8 390 8,457 9 390 9,468 . but the wrong comma is being split. I’ll keep trying to see if it’s possible 😉
Meanwhile, a simple solution would be to take advantage of the fact that that pandas puts part of the first column in the index:
df = (pd.read_csv('test.csv') .reset_index() .assign(wavelength=lambda ****['index'].astype(str) + '.' + x['wavelength'].astype(str)) .drop('index', axis=1) .astype()) >>> df wavelength intensity 0 390.0 382 1 390.1 390 2 390.2 400 3 390.3 408 4 390.4 418 5 390.5 427 6 390.6 437 7 390.7 447 8 390.8 457 9 390.9 468 EDIT: It is possible!
The following regular expression with a little dropna column-wise gets it done:
df = pd.read_csv('test.csv', engine='python', sep=r',(!?\w+)$').dropna(axis=1, how='all') >>> df wavelength intensity 0 390,0 382 1 390,1 390 2 390,2 400 3 390,3 408 4 390,4 418 5 390,5 427 6 390,6 437 7 390,7 447 8 390,8 457 9 390,9 468 Convert comma to dot in pd series [duplicate], Also, why this code below does not work? s.replace(<',':'.'>) python pandas.
How to Convert Decimal Comma to Decimal Point in Pandas DataFrame
In this quick tutorial, we’re going to convert decimal comma to decimal point in Pandas DataFrame and vice versa. It will also show how to remove decimals from strings in Pandas columns.
Different people in the world are using different decimal separator like:
Setup
Let’s work with the following DataFrame:
import pandas as pd df = pd.DataFrame(data=) We have two columns with float data:
1: read_csv — decimal point vs comma
Let’s start with the optimal solution — convert decimal comma to decimal point while reading CSV file in Pandas.
Method read_csv() has parameter three parameters that can help:
- decimal — the decimal sign used in the CSV file
- delimiter — separator for the CSV file (tab, semi-colon etc)
- thousands — what is the symbol for thousands — if any
df = pd.read_csv('file.csv', delimiter=";", decimal=",", thousands="`") This will ensure that the correct decimal symbol is used for the DataFrame.
2: Convert comma to point
If the DataFrame contains values with comma then we can convert them by .str.replace() :
df['humidity_eu'].str.replace(',', '.').astype(float) 0 0.89 1 0.86 2 0.54 3 0.73 4 0.45 5 0.63 6 0.95 7 0.67 Name: humidity_eu, dtype: float64 3: Mixed decimal data — point and comma
What can we do in case of mixed data in a given column? For this example we can use: list comprehensions and pd.to_numeric() .
This can help us to identify the problematic values and keep the rest the same.
s = pd.Series(['0,89', '0,86', 0.54, 0.73, 0.45, '0,63', '0,95', '0,67']) mix = [x.replace(',', '.') if type(x) == str else x for x in s] to replace the comma in all string records:
['0.89', '0.86', 0.54, 0.73, 0.45, '0.63', '0.95', '0.67'] Then we can convert the Series by:
array([0.89, 0.86, 0.54, 0.73, 0.45, 0.63, 0.95, 0.67]) 4: Detect decimal comma in mixed column
To detect which are the problematic values we can use:
s[pd.to_numeric(s, errors='coerce').isna() ] the result of to_numeric is:
array([ nan, nan, 0.54, 0.73, 0.45, nan, nan, nan]) while the final result is showing all values with decimal comma:
0 0,89 1 0,86 5 0,63 6 0,95 7 0,67 dtype: object 5: to_csv — decimal point vs comma
Finally if we like to write CSV file by method to_csv we can use parameters:
to control the decimal symbol.
To convert CSV values from decimal comma to decimal point with Python and Pandas we can do :
df = pd.read_csv("file.csv", decimal=",") df.to_csv("test2.csv", sep=',', decimal='.') 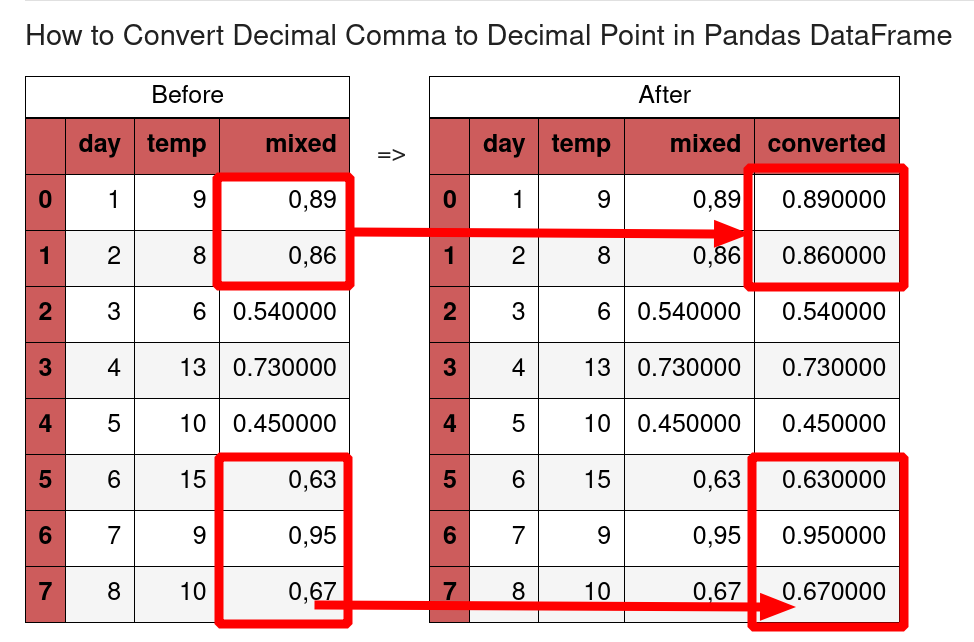
ValueError: could not convert string to float: ‘0,89’
The error: «ValueError: could not convert string to float: ‘0,89’» is raised when we try to parse decimal comma to float.
The error is given by method s.astype(float) :
s = pd.Series(['0,89', '0,86', 0.54, 0.73, 0.45, '0,63', '0,95', '0,67']) s.astype(float) ValueError: Unable to parse string «0,89» at position 0
The error is the result of the pd.to_numeric(s) method — when a decimal comma is present in the input values.
s = pd.Series(['0,89', '0,86', 0.54, 0.73, 0.45, '0,63', '0,95', '0,67']) pd.to_numeric(s) ValueError: Unable to parse string "0,89" at position 0 Conclusion
In this article we saw how to replace, change and convert decimal symbols in Pandas. We saw how to detect problematic values in mixed columns — which have decimal commas and points simultaneously.
Typical errors were explained.
For further reference you can check also:
By using DataScientYst — Data Science Simplified, you agree to our Cookie Policy.
Python – How to write a csv with a comma as the decimal separator
However, this still uses dot . as the decimal separator. What’s the correct way to make it use a comma, as is correct for my locale?
I can’t seem to find any way to set it in the docs. (I am using, and would prefer to stick to, the built-in csv module)
Best Solution
A little bit hacky way, but it’s the best I can think of: convert floats to strings and replace . with , :
def localize_floats(row): return [ str(el).replace('.', ',') if isinstance(el, float) else el for el in row ] for row in rows: writer.writerow(localize_floats(row)) If you want better localization handling, I suggest you convert all numbers using babel.numbers package.
Related Solutions
Python – How to sort a list of dictionaries by a value of the dictionary
The sorted() function takes a key= parameter
newlist = sorted(list_to_be_sorted, key=lambda d: d['name']) Alternatively, you can use operator.itemgetter instead of defining the function yourself
from operator import itemgetter newlist = sorted(list_to_be_sorted, key=itemgetter('name')) For completeness, add reverse=True to sort in descending order
newlist = sorted(list_to_be_sorted, key=itemgetter('name'), reverse=True) Python – How to print colored text to the terminal
This somewhat depends on what platform you are on. The most common way to do this is by printing ANSI escape sequences. For a simple example, here’s some Python code from the Blender build scripts:
class bcolors: HEADER = '\033[95m' OKBLUE = '\033[94m' OKCYAN = '\033[96m' OKGREEN = '\033[92m' WARNING = '\033[93m' FAIL = '\033[91m' ENDC = '\033[0m' BOLD = '\033[1m' UNDERLINE = '\033[4m' To use code like this, you can do something like:
print(bcolors.WARNING + "Warning: No active frommets remain. Continue?" + bcolors.ENDC) print(f"Warning: No active frommets remain. Continue?") This will work on unixes including OS X, Linux and Windows (provided you use ANSICON, or in Windows 10 provided you enable VT100 emulation). There are ANSI codes for setting the color, moving the cursor, and more.
If you are going to get complicated with this (and it sounds like you are if you are writing a game), you should look into the «curses» module, which handles a lot of the complicated parts of this for you. The Python Curses HowTO is a good introduction.
If you are not using extended ASCII (i.e., not on a PC), you are stuck with the ASCII characters below 127, and ‘#’ or ‘@’ is probably your best bet for a block. If you can ensure your terminal is using a IBM extended ASCII character set, you have many more options. Characters 176, 177, 178 and 219 are the «block characters».
Some modern text-based programs, such as «Dwarf Fortress», emulate text mode in a graphical mode, and use images of the classic PC font. You can find some of these bitmaps that you can use on the Dwarf Fortress Wiki see (user-made tilesets).
The Text Mode Demo Contest has more resources for doing graphics in text mode.