- json2table 1.1.5
- Details
- Installation
- Tests
- Python Create Table From JSON
- Sample Data
- Read JSON With Pandas
- Conclusion
- JSON Table
- How to install
- How it works
- Usage
- How it works
- JSON Paths
- Array Expansion
- Joining Columns
- Operators
- New in this version
- Coming up
- References
- Final disclaimer
- How to parse JSON data with Python Pandas?
- One-liner to read and normalize JSON data into a flat table using Pandas.
- ankitgoel1602/data-science
- You can’t perform that action at this time. You signed in with another tab or window. You signed out in another tab or…
- Data Details
json2table 1.1.5
This is a simple Python package that allows a JSON object to be converted to HTML. It provides a convert function that accepts a dict instance and returns a string of converted HTML. For example, the simple JSON object can be converted to HTML via:
The resulting table will resemble
More complex parsing is also possible. If a list of dict ’s provides the same list of keys, the generated HTML with gather items by key and display them in the same column.
It might, however, be more readable if we were able to build the table from top-to-bottom instead of the default left-to-right. Changing the build_direction to «TOP_TO_BOTTOM» yields:
Table attributes are added via the table_attributes parameter. This parameter should be a dict of (key, value) pairs to apply to the table in the form key=»value» . If in our simple example before we additionally wanted to apply a class attribute of «table table-striped» we would use the following:
and convert just as before:
Details
This module provides a single convert function. It takes as input the JSON object (represented as a Python dict ) and, optionally, a build direction and a dictionary of table attributes to customize the generated table:
convert(json_input, build_direction=»LEFT_TO_RIGHT», table_attributes=None)
JSON object to convert into HTML.
String denoting the build direction of the table. If «TOP_TO_BOTTOM» child objects will be appended below parents, i.e. in the subsequent row. If «LEFT_TO_RIGHT» child objects will be appended to the right of parents, i.e. in the subsequent column. Default is «LEFT_TO_RIGHT» .
table_attributes : dict , optional
Dictionary of (key, value) pairs describing attributes to add to the table. Each attribute is added according to the template key=»value» . For example, the table < "border" : 1 >modifies the generated table tags to include border=»1″ as an attribute. The generated opening tag would look like . Default is None .
Installation
The easiest method on installation is to use pip . Simply run:
If instead the repo was cloned, navigate to the root directory of the json2table package from the command line and execute:
Tests
In order to verify the code is working, from the command line navigate to the json2table root directory and run:
>>> python -m unittest tests.test_json2table
Python Create Table From JSON
![]()
JSON or JavaScript Object Notation is one of the most popular data exchange formats. It is commonly used in APIs and NoSQL databases due to its simplicity and readability.
However, it is not as straightforward when it comes to analyzing JSON. Hence, in this tutorial, we will learn how to convert a JSON file into a Pandas table.
Sample Data
The first step is to have the JSON data we wish to parse. We have selected a simple JSON file containing astronomy information for a specific city for this tutorial.
{
«country» : «United Kingdom,»
«state» : «England» ,
«city» : «London» ,
«latitude» : 51.466652350000004 ,
«longitude» : — 0.09686637642617651 ,
«date» : «2022-04-13» ,
«current_time» : «03:12:55.044» ,
«sunrise» : «06:09» ,
«sunset» : «19:53» ,
«sun_status» : «-» ,
«solar_noon» : «13:01» ,
«day_length» : «13:44» ,
«sun_altitude» : — 23.19751117067553 ,
«sun_distance» : 1.4988500851835912E8 ,
«sun_azimuth» : 35.781559107335625 ,
«moonrise» : «15:43» ,
«moonset» : «05:28» ,
«moon_status» : «-» ,
«moon_altitude» : 20.615536932562232 ,
«moon_distance» : 387894.3437906608 ,
«moon_azimuth» : 266.5048405334666 ,
«moon_parallactic_angle» : 34.5669393631715
}
Save the JSON file as astronomy_simple.json
Read JSON With Pandas
We will use Pandas to read the JSON file and convert it into a table.
Start by importing pandas:
Next, we will read the JSON file using the read_json function. This allows us to convert a JSON string to a pandas object as shown:
Once we have the JSON file converted into a pandas object, we can convert it into a pandas DataFrame as shown:
Finally, to print the data in a tabular format, use the display func as shown:
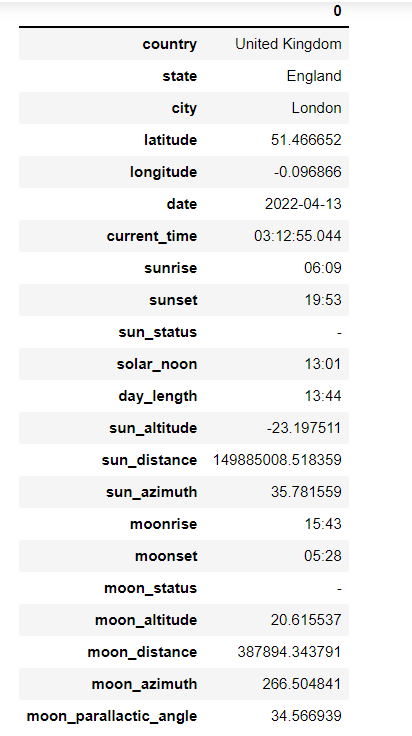
Conclusion
This short article describes a simple method to convert a JSON file into a table using Pandas.
JSON Table
A little package to convert a JSON into a table! This project was born out of a need to transform many JSONs mined from APIs to something that Pandas or a relational database could understand. The difference between this package and json path packages is that its designed to create tables, not just extract single values.
How to install
The package is available through pypi. So simply go to your command line and:
You’re also welcome to download the code from github and modify to suit your needs. And if you have time let me know what cool functionality you added and we can improve the project!
How it works
It works in a similar manner to JSON parsers
- Create a converter object
- Give the converter a list of paths you want to explore and how you want to name each column
- Give the converter a decoded JSON object you want to read, and it returns a table
Usage
Here is a quick example to get you going
In this case, you will get a table with two columns and two rows (header and first row of data) like these:
For more examples, refer to the tests folder
How it works
JSON Paths
Each path you specify is a column in your final table. Each path that is setup is expanded according to the standard JSON Path functionality. This is, for each path, the converter starts at the root of the JSON object and navigates each step (a.k.a node) of the path in order. When it reaches the final step in the path (a.k.a leaf), it outputs the resulting element of the JSON into the cell.
The final cell value is converted based on the standard JSON values as follows:
| JSON Value | Conversion | Sample Output |
|---|---|---|
| object | stringified object | » |
| array | stringified array | ‘[1,2,3]’ |
| string | string | ‘Foo’ |
| number | number | 4.7 |
| boolean | stringidied boolean | ‘False’ |
| null | None | None |
| missing value (i.e. the path did not find an element) | None | None |
The intention behind stringifying the object, array and boolean is to be able to pass the output to other data libraries (e.g Pandas) or to a relational database.
Array Expansion
With the exception of the final node, array elements are automatically expanded into rows. So for example a path ‘$.a.b’ applied to a JSON <"a":[<"b":1>,]> would result into two rows [[1],[2]] . The array expansion functionality can be applied to the final node by explicitly using the * operator as a final step (e.g. $.a.* )
[['Name', 'Telephone Number', 'Telephone Type'], ['Foo', '0000', 'mobile'], ['Foo', '1111', 'home']] The reverse of this functionality (not expand arrays if they are encountered before the end) is not implemented only due to the lack of need.
Joining Columns
Since a path may result in multiple rows, there is the need to be able to combine the result of each column into the same table. The joining mechanism is similar to an SQL join, where each cell (row-cell combination) is «matched» to a row in the result using a «matching value». The matching value in this case is the last common element of the paths.
This is best illustrated with an example, the following table shows the transformations applied to the sample JSON.
[ ['Name', 'Type', 'Number'], ['Foo', 'mobile', '0000'], ['Foo', 'home', '1111'], ['Bar', 'mobile', '2222'], ['Bar', 'home', '3333'] ]
[ ['Name', 'Number', 'Email'], ['Foo', '0000', 'foo@w.com'], ['Foo', '1111', 'foo@w.com'], ['Foo', '0000', 'foo@p.com'], ['Foo', '1111', 'foo@p.com'], ['Bar', '0000', 'bar@w.com'], ['Bar', '1111', 'bar@w.com'], ['Bar', '0000', 'bar@p.com'], ['Bar', '1111', 'bar@p.com'], ]
In the first case, the type and number have a common path telephone and therefore the columns are combined for the same telephone element. If we then look at the name path it has a common path contacts with the rest of the columns, and therefore, the value is repeated across the rows.
In the second case the email and number only have a common path contacts and since each path results in two rows, the only possible way to match these is to combine all the values, resulting in 4 rows per contact (total 8 rows since there are 2 contacts).
Operators
Currently there are two operators supported: * and ~
| Syntax | Description |
|---|---|
| * | Returns all values of the current element. If its an array, it will return one row per array value. If its an object (dictionary in Python) it will return one row per value. If its a value (string, number, boolean, null), it returns the same value |
| ~ | Return all indices of the current element. If its an array, it returns an ascending numbered sequence starting with 0 (e.g. [1,2] would return [[0],[1]]) . If its an object, it will return the keys (e.g. would return [[‘a’],[‘b’]]). If its a value it returns 0 |
More operators will be implemented in later releases.
New in this version
- A bug that was preventing list expansions at different depths (e.g. $.a as well as $.b.c) has been fixed.
- Implementation of the * and ~ operators
Both these changes were made possible by changing the search method from depth first to breadth first, as well as recursing through a tree rather than iterating through one column at a time.
Coming up
- Filtering
- List indexing
- More functions (basic arithmetics, string concatenation and expansion)
- Square bracket notation ($[a][b] for $.a.b)
- Stringify objects as an option
- Option to output pandas style named array
- Method to set paths and convert at the same time
- CSV Output/Input
References
I want to mention that whilst I inted to expand the functionality of this package, at the moment it can only take a simple sequence of keys to navigate a path. This is, the full functionality proposed by Stefan Gossner in his jsonpath is not yet implemented. but we will get there.
If you are looking for a package that simply extracts a single value from a JSON by using more complex paths (and its functions), I recommend you look at jsonpath-rw by Kenn Knowles jsonpath-ng by Tomas Aparicio or jsonpath2 by Mark Borkum.
Final disclaimer
I will continue to look for improvements in the package and hopefully add some useful functionality. Given the current popularity of the package, the maintenance is in a best effort manner. However if you have issues or bugs to report let me know here and I will try my best to help.
You can use this package as you wish, but unfortunatelly, I cannot take responsibility of how this code is used, or the results it provides. It is up to you to test this does what you want it to!
How to parse JSON data with Python Pandas?
One-liner to read and normalize JSON data into a flat table using Pandas.
If you are doing anything related to data whether it is Data Engineering, Data Analytics, or even Data Science, you would have surely come across JSONs.
JSON (JavaScript Object Notation) is one of the most used data formats for exchanging data over the web. NoSQL based databases like MongoDB store the data in this format. Although this format works well for storing the data, it needs to be converted into a tabular form for further analysis.
In this story, we will see how easy it is to parse JSON data and convert it into the tabular form. You can download the sample data from the GitHub repository mentioned below. Also, have a look at the notebook for more details about the data and APIs used.
ankitgoel1602/data-science
You can’t perform that action at this time. You signed in with another tab or window. You signed out in another tab or…
Data Details
I am going to use the data which I generated while working on the Machine Learning clustering problem. No need to worry if this data doesn’t make sense as it is used only for demo purposes. I will use two different JSON-
This is already flattened JSON and requires minimal processing.
Sample Record:
"Scaler": "Standard",
"family_min_samples_percentage": 5,
"original_number_of_clusters": 4,
"eps_value": 0.1,
"min_samples": 5,
"number_of_clusters": 9,
"number_of_noise_samples": 72,
"adjusted_rand_index": 0.001,
"adjusted_mutual_info_score": 0.009,
"homogeneity_score": 0.330,
"completeness_score": 0.999,
"v_measure_score": 0.497,
"fowlkes_mallows_score": 0.0282,
"silhouette_coefficient": 0.653,
"calinski_harabasz_score": 10.81,
"davies_bouldin_score": 1.70
>
2. JSON with nested lists/dictionaries.
This might seems a little complicated and in general, would require you to write a script for flattening. Later, we will see how it…