- Saved searches
- Use saved searches to filter your results more quickly
- License
- greenplum-db/GreenplumPython
- Name already in use
- Sign In Required
- Launching GitHub Desktop
- Launching GitHub Desktop
- Launching Xcode
- Launching Visual Studio Code
- Latest commit
- Git stats
- Files
- README.md
- Introduction to GreenplumPython: In-database processing of billions of rows with Python
- Step-by-step with GreenplumPython
- Installation
- Connect to the Greenplum database
- Read the News table
- Data Processing at scale
- Show the first 2 rows
- Select only a few columns
- Filter recent news
- Order values based on the date
- Data Transformation using PostgreSQL/Greenplum functions
- 1. Calculate the total number of rows
- 2. Calculate the length of the news
- 3. Uppercase news titles
- 4. Convert String to Date
- Data Transformation & Aggregation using UDFs and UDAs
- 1. Extract the year from the date column
- 2. Aggregate function to calculate the maximum news length
- 3. Calculate the number of news per year
- Save transformed DataFrame to Database
- In Summary
- More resources :
Saved searches
Use saved searches to filter your results more quickly
You signed in with another tab or window. Reload to refresh your session. You signed out in another tab or window. Reload to refresh your session. You switched accounts on another tab or window. Reload to refresh your session.
License
greenplum-db/GreenplumPython
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
Name already in use
A tag already exists with the provided branch name. Many Git commands accept both tag and branch names, so creating this branch may cause unexpected behavior. Are you sure you want to create this branch?
Sign In Required
Please sign in to use Codespaces.
Launching GitHub Desktop
If nothing happens, download GitHub Desktop and try again.
Launching GitHub Desktop
If nothing happens, download GitHub Desktop and try again.
Launching Xcode
If nothing happens, download Xcode and try again.
Launching Visual Studio Code
Your codespace will open once ready.
There was a problem preparing your codespace, please try again.
Latest commit
Git stats
Files
Failed to load latest commit information.
README.md
GreenplumPython is a Python library that enables the user to interact with Greenplum in a Pythonic way.
GreenplumPython provides a pandas-like DataFrame API that
- looks familiar and intuitive to Python users
- is powerful to do complex analytics, such as statistical analysis, with UDFs and UDAs
- encapsulates common best practices and avoids common pitfalls in Greenplum, compared to writing SQL directly
To install the latest development version, do
pip3 install --user git+https://github.com/greenplum-db/GreenplumPython
To install the latest released version, do
pip3 install --user greenplum-python
Note: The —user option in an active virtual environment will install to the local user python location. Since a user location doesn’t make sense for a virtual environment, to install the GreenplumPython library, just remove —user from the above commands.
The documentation of GreenplumPython can be viewed at:
Introduction to GreenplumPython: In-database processing of billions of rows with Python
GreenplumPython is a Python library that scales the Python data experience by building an API. It allows users to process and manipulate tables of billions of rows in Greenplum, using Python, without exporting the data to their local machines.
GreenplumPython enables Data Scientists to code in their familiar Pythonic way using the Pandas package, execute data transformations and train Machine Learning models faster and more securely in a single Greenplum platform.
Python users can indeed proceed with Greenplum’s interactive analysis performance and distributed environment without deep knowledge of SQL.

GreenplumPython pushes all its operations transparently as SQL statements to the Greenplum data warehouse. Hence, we don’t have to move any data out of Greenplum or spin up and manage additional systems.
Step-by-step with GreenplumPython
This section shows how to use the GreenplumPython package to process and transform a News dataset downloaded from Kaggle and augmented up to 132 million rows.
Installation
You can install the latest release of the GreenplumPython library with pip3:
$ pip3 install greenplum-python Note: GreenplumPython currently requires at least Python 3.9 to run.
Connect to the Greenplum database
After importing the package, we need to use the object to initialise the Greenplum session, as shown below :
import greenplumpython as gp db = gp.database( params=< "host": hostname, "dbname": dbname, "user": user, "password": password, "port": port, > ) It is nice to know that the GreenplumPython connection uses a psycopg2 driver since it is a PostgreSQL-based database.
Furthermore, the connection can also be established using the database‘s connection URI . It follows the same specification in the libpq document as follow:
db = gp.database(uri="postgres://user:password@hostname:port/dbname") Read the News table
DataFrame is the core data structure in GreenplumPython.
After selecting the database, we can create a DataFrame to access the table in the database by specifying its name. Two methods exist:
df = gp.DataFrame.from_table("news",db=db) # Or df = db.create_dataframe(table_name="news") Now we have a DataFrame. We can do basic data manipulation on it, just like in SQL.
Data Processing at scale
Show the first 2 rows
We note that data in the database are unordered.
For a quick glance, we can SELECT the first two unordered rows of DataFrame:

Select only a few columns
We can SELECT a subset of its columns:
# Select "date" and "title" columns df[["date", "title"]][:2] 
Filter recent news
We can SELECT a subset of its rows filtered by conditions:
# Filter specific date range news (since 1st January 2020) filtered_news = df.where(lambda t: t["date"] >= "2020-01-01") # Select the first five rows, and show only the title & date columns filtered_news[["title","date"]][:2] 
Order values based on the date
Having the data sorted in a desired order makes it convenient for many analytical tasks, such as statistics. For example, to get the top-N values.
In GreenplumPython, the order of data can be defined with the order_by() method:
filtered_news.order_by("date", ascending=False)[:5][["title", "date"]] 
Data Transformation using PostgreSQL/Greenplum functions
Calling functions is essential for data analytics. GreenplumPython supports calling Greenplum functions in Python.
Note: Greenplum Database supports built-in analytic and window functions that can be used in window expressions.
1. Calculate the total number of rows
GreenplumPython provides several predefined DataFrame functions in the database via the interface builtins.functions , such as count :
import greenplumpython.builtins.functions as F # Apply the row-count df.apply(lambda _: F.count()) 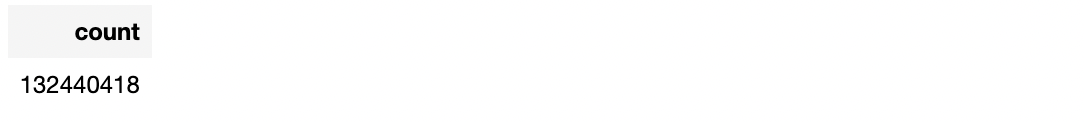
You can access other Greenplum and general-purpose aggregate functions with gp.function or gp.aggregate_function .
Note: Complex aggregate functions, such as ordered-set or hypothetical-set aggregate functions, are not yet supported.
2. Calculate the length of the news
# Load "length" SQL function length = gp.function("length") # For each row, calculate the length of news content # And create a new column called "news_length" df = df.assign( news_length = lambda t: length(t["content"]) ) 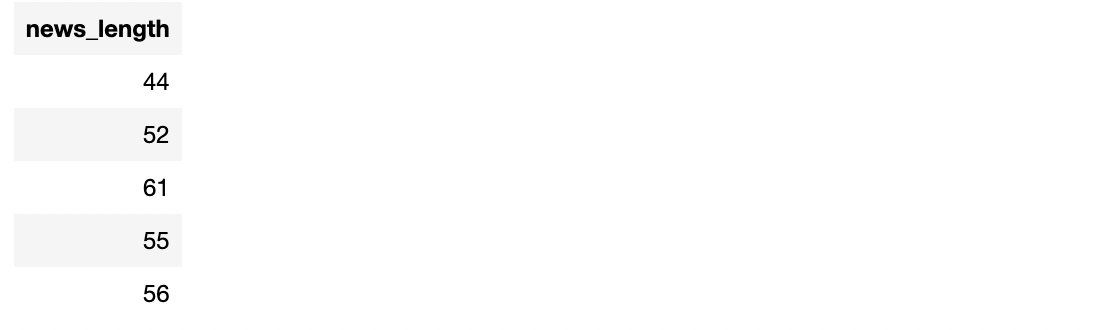
3. Uppercase news titles
# Load "upper" SQL function upper = gp.function("upper") # For each row, the uppercase news title # And create a new column called "uppercase_titles" df = df.assign( uppercase_titles = lambda t: upper(t["title"]) ) # Print original and transformed titles df[["title", "uppercase_titles"]][:5] 
4. Convert String to Date
# Load "to_date" SQL function to_date = gp.function("to_date") # Convert each "date" string value to the right DATE type df = df.assign( to_date = lambda t: upper(t["date"]) ) 
Data Transformation & Aggregation using UDFs and UDAs
GreenplumPython also supports creating Greenplum UDFs (User-defined functions) and UDAs (User-defined aggregation) from Python functions and calling them in Python.
You can create such functions with decorators @gp.create_function or @gp.create_aggregate , and you need to specify the type of inputs and outputs of functions.
1. Extract the year from the date column
@gp.create_function def extract_year_from_date(date: str) -> str: return date[:4] df = df.assign( year = lambda t: extract_year_from_date(t["date"]) ) 
2. Aggregate function to calculate the maximum news length
We can create an aggregate function to calculate the maximum length of news:
@gp.create_aggregate def max_length(result: int, val: str) -> int: import numpy as np if result is None: return len(str(val)) return np.max([result ,len(str(val))]) df.apply(lambda t: max_length(t["content"]), column_name="news_max_length") 
Of course, since we already have column news_length, we could also apply a simple predefined aggregation function max to obtain the result:
df.apply(lambda t: F.max(t["news_length"])) 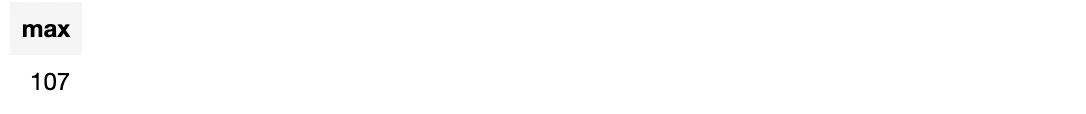
We note that these functions are called in the same way as ordinary Python functions.
3. Calculate the number of news per year
All the above functionalities can be combined with the chaining method:
df.group_by("year").apply( lambda _: F.count() ).where(lambda t: t["year"] != "").order_by("year", ascending = True)[:] 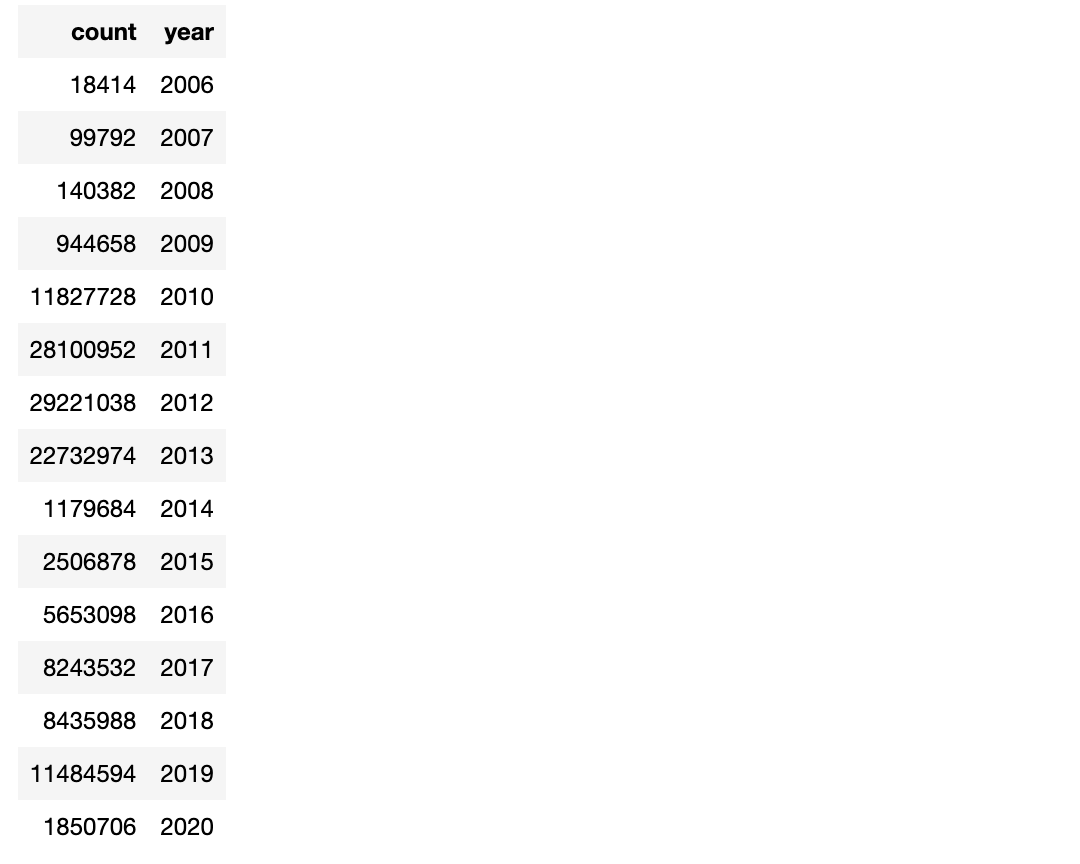
Save transformed DataFrame to Database
Finally, when we are done with data preparation, we can save the resulting DataFrame to the database as a table, either temporarily or persistently. Moreover, we can specify storage parameters with the storage_params attribute:
df = df.save_as( "news_cleaned", column_names=[ "date", "title", "content", "docid", "news_length", "uppercase_titles", "to_date", "year", ], temp=True, storage_params="appendoptimized": True>, )
In Summary
GreenplumPython provides a Pandas-like DataFrame API that:
- Looks familiar and intuitive to Python users.
- It is powerful to do complex analytics, such as Machine Learning, Deep Learning, NLP, and Statistical analysis on large datasets with UDFs and UDAs.
- Encapsulates standard best practices and avoids common pitfalls in Greenplum, compared to writing SQL directly.
And don’t forget! GreenplumPython supports working on large datasets on the Greenplum database directly, so you don’t need to bring data locally.
I will share more blogs on how to use GreenplumPython. Don’t hesitate if you have questions or feedback about it.
In the next blog, I will present how to implement TPC-H queries using GreenplumPython with data stored in Greenplum.
Now, it is your turn to try it!
More resources :
- Learn more about VMware Greenplum and OSS Greenplum
- Subscribe to read more Greenplum Data Clinics stories
- Read the GreenplumPython documentation
- See a real-life example at Train an ML model using GreenplumPython