- Conversion between bytes and strings#
- encode , decode #
- str.encode , bytes.decode #
- How to work with Unicode and bytes#
- Преобразование байтов в строку в Python
- Преобразование байтов в строку в Python 3
- Преобразование байтов в строку с помощью decode()
- Преобразование байтов в строку с кодеками
- Преобразование байтов в строку с помощью str()
- Преобразование байтов в строку в Python 2
- Преобразование байтов в Unicode (Python 2)
- Преобразование байтов в строку с помощью decode() (Python 2)
- Преобразование байтов в строку с помощью кодеков (Python 2)
- Помните о своей кодировке
- Конвертация между байтами и строками#
- encode, decode#
- str.encode, bytes.decode#
- Как работать с Юникодом и байтами#
- Python String encode() decode()
- Python String encode()
- Python Bytes decode()
Conversion between bytes and strings#
You can’t avoid working with bytes. For example, when working with a network or a filesystem, most often the result is returned in bytes. Accordingly, you need to know how to convert bytes to string and vice versa. That’s what the encoding is for.
Encoding can be represented as an encryption key that specifies:
- how to “encrypt” a string to bytes (str -> bytes). Encode method used (similar to encrypt)
- how to “decrypt” bytes to string (bytes -> str). Decode method used (similar to decrypt)
This analogy makes it clear that string-byte and byte-string transformations must use the same encoding.
encode , decode #
encode method is used to convert string to bytes:
In [1]: hi = 'привет' In [2]: hi.encode('utf-8') Out[2]: b'\xd0\xbf\xd1\x80\xd0\xb8\xd0\xb2\xd0\xb5\xd1\x82' In [3]: hi_bytes = hi.encode('utf-8')
decode method to get a string from bytes:
In [4]: hi_bytes Out[4]: b'\xd0\xbf\xd1\x80\xd0\xb8\xd0\xb2\xd0\xb5\xd1\x82' In [5]: hi_bytes.decode('utf-8') Out[5]: 'привет'
str.encode , bytes.decode #
Method encode is also present in str class (as are other methods of working with strings):
In [6]: hi Out[6]: 'привет' In [7]: str.encode(hi, encoding='utf-8') Out[7]: b'\xd0\xbf\xd1\x80\xd0\xb8\xd0\xb2\xd0\xb5\xd1\x82'
And decode method is available in bytes class (like other methods):
In [8]: hi_bytes Out[8]: b'\xd0\xbf\xd1\x80\xd0\xb8\xd0\xb2\xd0\xb5\xd1\x82' In [9]: bytes.decode(hi_bytes, encoding='utf-8') Out[9]: 'привет'
In these methods, encoding can be used as a key argument (examples above) or as a positional argument:
In [10]: hi_bytes Out[10]: b'\xd0\xbf\xd1\x80\xd0\xb8\xd0\xb2\xd0\xb5\xd1\x82' In [11]: bytes.decode(hi_bytes, 'utf-8') Out[11]: 'привет'
How to work with Unicode and bytes#
There is a rule called a “Unicode sandwich”:
- bytes that the program reads must be converted to Unicode (string) as early as possible
- inside the program work with Unicode
- Unicode must be converted to bytes as soon as possible before transmitting
Преобразование байтов в строку в Python
В этой статье мы рассмотрим, как преобразовать байты в строку в Python. К концу этой статьи у вас будет четкое представление о том, что это за типы и как эффективно обрабатывать данные с их помощью.
В зависимости от версии Python, которую вы используете, эта задача будет отличаться. Хотя Python 2 подошел к концу, многие проекты все еще используют его, поэтому мы включим оба подхода — Python 2 и Python 3.
Преобразование байтов в строку в Python 3
Начиная с Python 3, пришлось отказаться от старого способа работы с ASCII, и Python стал полностью Unicode.
Это означает, что мы потеряли явный тип Unicode: u»string» — каждая строка — это u»string» !
Чтобы отличить эти строки от старых добрых строк байтов, мы познакомились с новым спецификатором для них — b»string» .
Это было добавлено в Python 2.6, но не служило реальной цели, кроме подготовки к Python 3, поскольку все строки были байтовыми строками в 2.6.
Строки байтов в Python 3 официально называются bytes , неизменной последовательностью целых чисел в диапазоне 0
Преобразование байтов в строку с помощью decode()
Давайте посмотрим, как мы можем преобразовать байты в String, используя встроенный метод decode() для класса bytes :
b = b"Lets grab a \xf0\x9f\x8d\x95!" # Let's check the type print(type(b)) # # Now, let's decode/convert them into a string s = b.decode('UTF-8') print(s) # "Let's grab a 🍕!" Передав формат кодирования, мы преобразовали объект bytes в строку и распечатали ее.
Преобразование байтов в строку с кодеками
Как вариант, для этой цели мы можем использовать встроенный модуль codecs :
import codecs b = b'Lets grab a \xf0\x9f\x8d\x95!' print(codecs.decode(b, 'UTF-8')) # "Let's grab a 🍕!" Вам действительно не нужно передавать параметр кодировки, однако рекомендуется передавать его:
print(codecs.decode(b)) # "Let's grab a 🍕!" Преобразование байтов в строку с помощью str()
Наконец, вы можете использовать str() функцию, которая принимает различные значения и преобразует их в строки:
b = b'Lets grab a \xf0\x9f\x8d\x95!' print(str(b, 'UTF-8')) # "Let's grab a 🍕!" Не забудьте указать аргумент кодировки str() , иначе вы можете получить неожиданные результаты:
print(str(b)) # b'Lets grab a \xf0\x9f\x8d\x95!' Это снова подводит нас к кодировкам. Если вы укажете неправильную кодировку, в лучшем случае произойдет сбой вашей программы, потому что она не может декодировать данные. Например, если бы мы попытались использовать функцию str() с UTF-16 , нас бы встретили:
print(str(b, 'UTF-16')) # '敌❴\u2073牧扡愠\uf020趟↕' Это даже более важно, учитывая, что Python 3 любит использовать Unicode, поэтому, если вы работаете с файлами или источниками данных, которые используют непонятную кодировку, обязательно обратите на это особое внимание.
Преобразование байтов в строку в Python 2
В Python 2 набор байтов и строка — это практически одно и то же: строки — это объекты, состоящие из однобайтовых символов, что означает, что каждый символ может хранить 256 значений. Вот почему их иногда называют строками байтов.
Это замечательно при работе с байтовыми данными — мы просто загружаем их в переменную и готовы к печати:
s = "Hello world!" print(s) # 'Hello world!' print(len(s)) # 12Однако использование символов Unicode в строках байтов немного меняет это поведение:
s = "Let's grab a 🍕!" print(s) # 'Lets grab a \xf0\x9f\x8d\x95!' # Where has the pizza gone to? print(len(s)) # 17 # Shouldn't that be 15? Преобразование байтов в Unicode (Python 2)
Здесь нам придется использовать тип Python 2 Unicode , который предполагается и автоматически используется в Python 3. В нем строки хранятся как последовательность кодовых точек, а не байтов.
Представляет собой байты \xf0\x9f\x8d\x95 , последовательность шестнадцатеричных чисел и Python не знает, как представить их в виде ASCII:
>>> u = u"Let's grab a 🍕!" u"Let's grab a \U0001f355!"" >>> u "Let's grab a 🍕!" # Yum. >>> len(u) 15 Как вы можете видеть выше, строка Unicode содержит \U0001f355 — экранированный символ Unicode, который наш терминал распечатывает как кусок пиццы! Установить это было так же просто, как использовать спецификатор u перед значением байтовой строки.
Итак, как мне переключаться между ними?
Вы можете получить строку Unicode, расшифровав свою байтовую строку. Это можно сделать, создав объект Unicode, предоставив байтовую строку и строку, содержащую имя кодировки в качестве аргументов, или вызвав .decode(encoding) у байтовой строки.
Преобразование байтов в строку с помощью decode() (Python 2)
Вы также можете использовать codecs.encode(s, encoding) из модуля codecs .
>>> s = "Let's grab a \xf0\x9f\x8d\x95!" >>> u = unicode(s, 'UTF-8') >>> u "Let's grab a 🍕!" >>> s.decode('UTF-8') "Let's grab a 🍕!" Преобразование байтов в строку с помощью кодеков (Python 2)
Или, используя модуль codecs :
import codecs >>> codecs.decode(s, 'UTF-8') "Let's grab a 🍕!" Помните о своей кодировке
Здесь следует предостеречь — байты могут по-разному интерпретироваться в разных кодировках. Из- за того, что из коробки доступно около 80 различных кодировок, может быть нелегко узнать, есть ли у вас правильная!
s = '\xf8\xe7' # This one will let us know we used the wrong encoding >>> s.decode('UTF-8') UnicodeDecodeError: 'utf8' codec can't decode byte 0xf8 in position 0: invalid start byte # These two overlaps and this is a valid string in both >>> s.decode('latin1') øç s.decode('iso8859_5') јч Исходное сообщение было либо, øç либо јч , и оба кажутся допустимыми преобразованиями.
Конвертация между байтами и строками#
Избежать работы с байтами нельзя. Например, при работе с сетью или файловой системой, чаще всего, результат возвращается в байтах.
Соответственно, надо знать, как выполнять преобразование байтов в строку и наоборот. Для этого и нужна кодировка.
Кодировку можно представлять как ключ шифрования, который указывает:
- как «зашифровать» строку в байты (str -> bytes). Используется метод encode (похож на encrypt)
- как «расшифровать» байты в строку (bytes -> str). Используется метод decode (похож на decrypt)
Эта аналогия позволяет понять, что преобразования строка-байты и байты-строка должны использовать одинаковую кодировку.
encode, decode#
Для преобразования строки в байты используется метод encode:
In [1]: hi = 'привет' In [2]: hi.encode('utf-8') Out[2]: b'\xd0\xbf\xd1\x80\xd0\xb8\xd0\xb2\xd0\xb5\xd1\x82' In [3]: hi_bytes = hi.encode('utf-8')
Чтобы получить строку из байт, используется метод decode:
In [4]: hi_bytes Out[4]: b'\xd0\xbf\xd1\x80\xd0\xb8\xd0\xb2\xd0\xb5\xd1\x82' In [5]: hi_bytes.decode('utf-8') Out[5]: 'привет'
str.encode, bytes.decode#
Метод encode есть также в классе str (как и другие методы работы со строками):
In [6]: hi Out[6]: 'привет' In [7]: str.encode(hi, encoding='utf-8') Out[7]: b'\xd0\xbf\xd1\x80\xd0\xb8\xd0\xb2\xd0\xb5\xd1\x82'
А метод decode есть у класса bytes (как и другие методы):
In [8]: hi_bytes Out[8]: b'\xd0\xbf\xd1\x80\xd0\xb8\xd0\xb2\xd0\xb5\xd1\x82' In [9]: bytes.decode(hi_bytes, encoding='utf-8') Out[9]: 'привет'
В этих методах кодировка может указываться как ключевой аргумент (примеры выше) или как позиционный:
In [10]: hi_bytes Out[10]: b'\xd0\xbf\xd1\x80\xd0\xb8\xd0\xb2\xd0\xb5\xd1\x82' In [11]: bytes.decode(hi_bytes, 'utf-8') Out[11]: 'привет'
Как работать с Юникодом и байтами#
Есть очень простое правило, придерживаясь которого, можно избежать, как минимум, части проблем. Оно называется «Юникод-сэндвич»:
- байты, которые программа считывает, надо как можно раньше преобразовать в Юникод (строку)
- внутри программы работать с Юникод
- Юникод надо преобразовать в байты как можно позже, перед передачей
Python String encode() decode()

While we believe that this content benefits our community, we have not yet thoroughly reviewed it. If you have any suggestions for improvements, please let us know by clicking the “report an issue“ button at the bottom of the tutorial.
Python String encode()
Python string encode() function is used to encode the string using the provided encoding. This function returns the bytes object. If we don’t provide encoding, “utf-8” encoding is used as default.
Python Bytes decode()
Python bytes decode() function is used to convert bytes to string object. Both these functions allow us to specify the error handling scheme to use for encoding/decoding errors. The default is ‘strict’ meaning that encoding errors raise a UnicodeEncodeError. Some other possible values are ‘ignore’, ‘replace’ and ‘xmlcharrefreplace’. Let’s look at a simple example of python string encode() decode() functions.
str_original = 'Hello' bytes_encoded = str_original.encode(encoding='utf-8') print(type(bytes_encoded)) str_decoded = bytes_encoded.decode() print(type(str_decoded)) print('Encoded bytes =', bytes_encoded) print('Decoded String =', str_decoded) print('str_original equals str_decoded =', str_original == str_decoded) Encoded bytes = b'Hello' Decoded String = Hello str_original equals str_decoded = True Above example doesn’t clearly demonstrate the use of encoding. Let’s look at another example where we will get inputs from the user and then encode it. We will have some special characters in the input string entered by the user.
str_original = input('Please enter string data:\n') bytes_encoded = str_original.encode() str_decoded = bytes_encoded.decode() print('Encoded bytes =', bytes_encoded) print('Decoded String =', str_decoded) print('str_original equals str_decoded =', str_original == str_decoded) 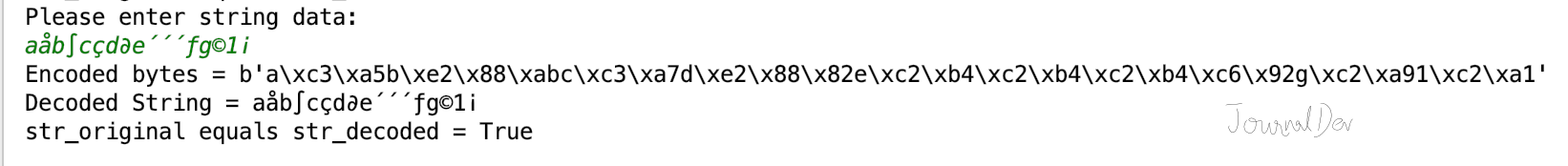
Output:
Please enter string data: aåb∫cçd∂e´´´ƒg©1¡ Encoded bytes = b'a\xc3\xa5b\xe2\x88\xabc\xc3\xa7d\xe2\x88\x82e\xc2\xb4\xc2\xb4\xc2\xb4\xc6\x92g\xc2\xa91\xc2\xa1' Decoded String = aåb∫cçd∂e´´´ƒg©1¡ str_original equals str_decoded = True You can checkout complete python script and more Python examples from our GitHub Repository. Reference: str.encode() API Doc, bytes.decode() API Doc
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases. Learn more about us