- Binascii.Error: Incorrect padding in python django
- Answer by Kailey Gilmore
- Answer by Lana Lucas
- Answer by Ariya Abbott
- Answer by Kash Wade
- Python base64 b64decode incorrect padding
- # Table of Contents
- # Python binascii.Error: Incorrect padding [Solved]
- # Add padding to your bytes object before decoding
- # Make sure the validate keyword argument is set to False
- # Creating a reusable function that pads the bytes
- # Removing the prefix when decoding base64 image strings
- # Try using the base64.urlsafe_b64decode method instead
- # Additional Resources
Binascii.Error: Incorrect padding in python django
This last property of python’s base64 decoding ensures that the following code adding 3 padding = will never succumb to the TypeError and will always produce the same result.,It’s clumsy but effective method to deal with strings from different implementations of base64 encoders,without the == padding (this is how many things are encoded for e.g. access tokens),That is not quite right. Modulo alone isn’t going to give you the number of padding characters you need. This works:
Avoiding padding errors with Python’s base64 encoding
>>> import base64 >>> data = '' >>> code = base64.b64encode(data) >>> code 'eyJ1IjogInRlc3QifQ==' Note the trailing == to make len a multiple of 4. This decodes properly
>>> len(code) 20 >>> base64.b64decode(code) '' >>> base64.b64decode(code) == data True without the == padding (this is how many things are encoded for e.g. access tokens)
>>> base64.b64decode(code[0:18]) == data . TypeError: Incorrect padding However, you can add back the padding
>>> base64.b64decode(code + "==") == data True Or add an arbitrary amount of padding (it will ignore extraneous padding)
>>> base64.b64decode(code + "========") == data True This last property of python’s base64 decoding ensures that the following code adding 3 padding = will never succumb to the TypeError and will always produce the same result.
>>> base64.b64decode(code + "===") == data True Answer by Kailey Gilmore
Summaries Issues with patch Easy issues Stats , Issues with patch
All base64 decoding methods fail to decode a valid base64 string, throwing 'incorrect padding' regardless of the string padding. Here's an example: >>> base64.urlsafe_b64decode('AQAAQDhAAMAAQAAAAAAAAthAAAAJDczODFmZDM2LTNiOTYtNDVmYS04MjQ2LWRkYzJkMmViYjQ2YQ===') Traceback (most recent call last): File "", line 1, in File "/export/apps/python/3.6/lib/python3.6/base64.py", line 133, in urlsafe_b64decode return b64decode(s) File "/export/apps/python/3.6/lib/python3.6/base64.py", line 87, in b64decode return binascii.a2b_base64(s) binascii.Error: Incorrect padding The same string gets decoded without any issues using Perl's MIME::Base64 module or Java. So far Python's base64 module is the only one that fails to decode it.Answer by Lana Lucas
I'm not sure this applies to your situation, depending on where you're storing your encoded data. I had the same error, but it related to some encoded session data. I cleared out the session data (cookies, cache etc) in the browser Devtools, and it fixed my issue. Just posting this in case it applies or helps others who come along for the same reason.Answer by Ariya Abbott
Check for /var/log/rhsm/rhsm.log file to see the python trackback errors:,The trackback errors shows incompatibility between the O.S. and the subscription-manager as base64-encoded strings are not getting decrypted as required.,Run the yum command to update the coreutils package after creating the local repository.,Update the Coreutils (Decoded: base64) package using a local repository created from a latest RHEL 7 DVD ISO.
- Every time subscription-manager command is executed, we get an error ‘incorrect padding’ error message.
- Getting ‘Incorrect padding’ error message as follows:
# subscription-manager remove --all 0 subscriptions removed at the server. Incorrect padding Answer by Kash Wade
Here is the traceback of an error that seems to appear randomly on my developer box with nagare 0.3.0 : , I’m not sure why the problem appear in the first place (I don’t play with the cookie myself), but the decoding should never fail.
Here is the traceback of an error that seems to appear randomly on my developer box with nagare 0.3.0 :
Traceback (most recent call last): File "/home/spt/projects/sandboxes/ipages/lib/python2.6/site-packages/nagare-0.3.0-py2.6.egg/nagare/wsgi.py", line 362, in __call__ self.start_request(root, request, response) File "/home/spt/projects/pj-eureka/pj-eureka/ipages/app.py", line 137, in start_request super(EurekaApplication, self).start_request(shell_comp, request, response) File "/home/spt/projects/sandboxes/ipages/lib/python2.6/site-packages/nagare-0.3.0-py2.6.egg/nagare/wsgi.py", line 262, in start_request security.set_user(self.security.create_user(request, response)) # Create the User object File "/home/spt/projects/sandboxes/ipages/lib/python2.6/site-packages/nagare-0.3.0-py2.6.egg/nagare/security/common.py", line 150, in create_user (username, ids) = self.get_ids(request, response) File "/home/spt/projects/sandboxes/ipages/lib/python2.6/site-packages/nagare-0.3.0-py2.6.egg/nagare/security/basic_auth.py", line 58, in get_ids (username, password) = self._get_ids(request, response) File "/home/spt/projects/sandboxes/ipages/lib/python2.6/site-packages/nagare-0.3.0-py2.6.egg/nagare/security/form_auth.py", line 128, in _get_ids ids = self.get_ids_from_cookie(request.cookies) File "/home/spt/projects/sandboxes/ipages/lib/python2.6/site-packages/nagare-0.3.0-py2.6.egg/nagare/security/form_auth.py", line 97, in get_ids_from_cookie return self.cookie_decode(data) File "/home/spt/projects/sandboxes/ipages/lib/python2.6/site-packages/nagare-0.3.0-py2.6.egg/nagare/security/form_auth.py", line 82, in cookie_decode return [s.decode('base64').decode('utf-8') for s in cookie.split(':')] File "/home/spt/projects/sandboxes/ipages/lib/python2.6/encodings/base64_codec.py", line 42, in base64_decode output = base64.decodestring(input) File "/home/spt/opt/python-2.6.5-stackless/lib/python2.6/base64.py", line 321, in decodestring return binascii.a2b_base64(s) Error: Incorrect padding Python base64 b64decode incorrect padding
Last updated: Jul 4, 2023
Reading time · 4 min

# Table of Contents
# Python binascii.Error: Incorrect padding [Solved]
The Python «binascii.Error: Incorrect padding» occurs when you try to base64 decode a bytes object that doesn’t have the correct padding.
To solve the error add padding to the bytes object when calling base64.b64decode() .
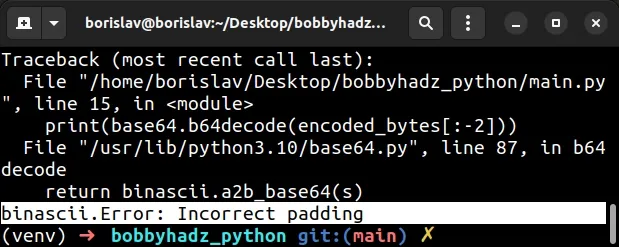
Here is an example of how the error occurs.
Copied!import base64 data = bytes('', encoding='utf-8') encoded_bytes = base64.b64encode(data) print(encoded_bytes) # b'eyJuYW1lIjogImJvYmJ5IGhhZHoifQ==' decoded_bytes = base64.b64decode(encoded_bytes) print(decoded_bytes) # 👉️ b'' # ⛔️ binascii.Error: Incorrect padding print(base64.b64decode(encoded_bytes[:-2]))
We used the base64.b64encode method to encode a bytes-like object using Base64.
The method returns the encoded bytes.
We then used the base64.b64decode method to decode the Base64 encoded bytes-like object.
The last line raises the «binascii.Error: Incorrect padding» error because we used slicing to remove the last 2 characters ( the padding — == ) from the bytes object.
# Add padding to your bytes object before decoding
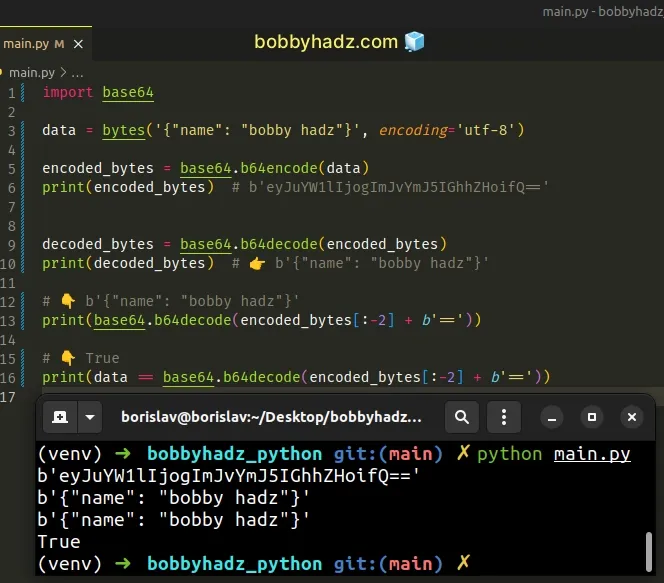
You can solve the error by adding padding ( == ) to your bytes object before decoding.
The base64.b64decode() method will truncate any extra padding, so even if your bytes object is padded sufficiently, it won’t cause any issues.
Copied!import base64 data = bytes('', encoding='utf-8') encoded_bytes = base64.b64encode(data) print(encoded_bytes) # b'eyJuYW1lIjogImJvYmJ5IGhhZHoifQ==' decoded_bytes = base64.b64decode(encoded_bytes) print(decoded_bytes) # 👉️ b'' # 👇️ b'' print(base64.b64decode(encoded_bytes[:-2] + b'==')) # 👇️ True print(data == base64.b64decode(encoded_bytes[:-2] + b'=='))
You can add padding to your bytes object by using the addition (+) operator.
Copied!# 👇️ b'' print(base64.b64decode(encoded_bytes[:-2] + b'=='))
The base64.b64decode() method truncates the extra padding, so the following code sample achieves the same result.
Copied!import base64 data = bytes('', encoding='utf-8') encoded_bytes = base64.b64encode(data) print(encoded_bytes) # b'eyJuYW1lIjogImJvYmJ5IGhhZHoifQ==' decoded_bytes = base64.b64decode(encoded_bytes) print(decoded_bytes) # 👉️ b'' # 👇️ b'' print(base64.b64decode(encoded_bytes[:-2] + b'=======')) # 👇️ True print(data == base64.b64decode(encoded_bytes[:-2] + b'========='))
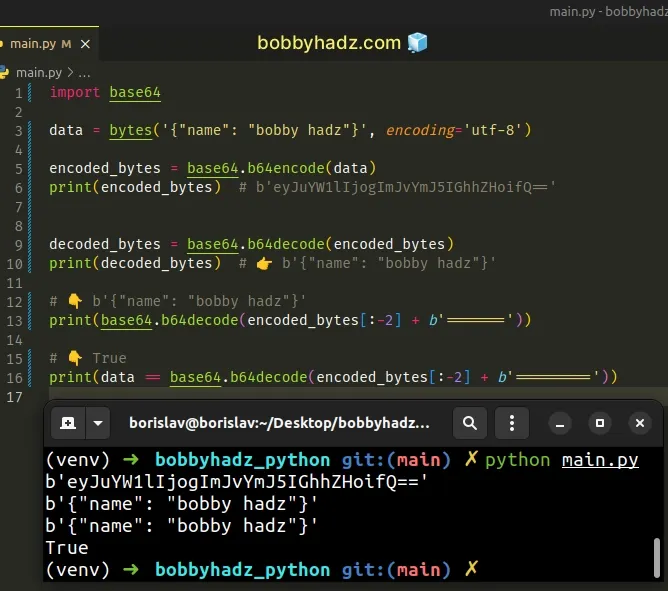
You can simply add the maximum number of pad characters that you need.
Copied!# 👇️ b'' print(base64.b64decode(encoded_bytes[:-2] + b'======='))
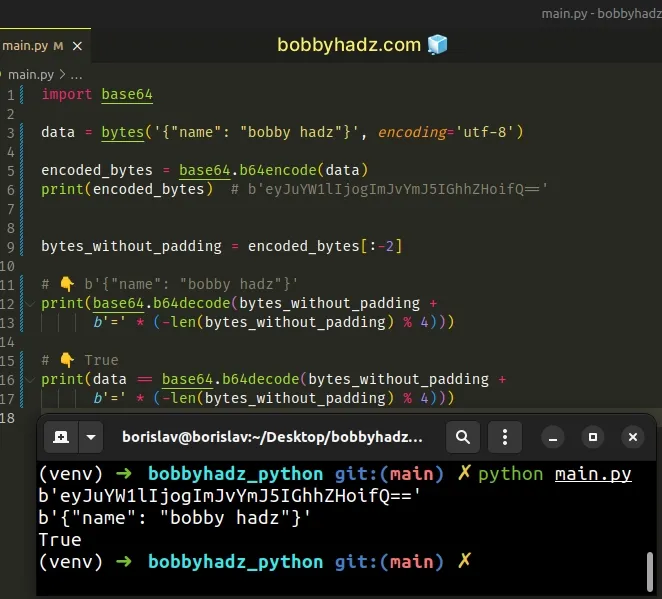
If you don’t want to add extra padding, use the following formula.
Copied!import base64 data = bytes('', encoding='utf-8') encoded_bytes = base64.b64encode(data) print(encoded_bytes) # b'eyJuYW1lIjogImJvYmJ5IGhhZHoifQ==' bytes_without_padding = encoded_bytes[:-2] # 👇️ b'' print(base64.b64decode(bytes_without_padding + b'=' * (-len(bytes_without_padding) % 4))) # 👇️ True print(data == base64.b64decode(bytes_without_padding + b'=' * (-len(bytes_without_padding) % 4)))
However, using the formula is not necessary and is a bit more difficult to read.
# Make sure the validate keyword argument is set to False
Make sure the validate keyword argument is set to False when calling the base64.b64decode() method.
Copied!import base64 data = bytes('', encoding='utf-8') encoded_bytes = base64.b64encode(data) print(encoded_bytes) # b'eyJuYW1lIjogImJvYmJ5IGhhZHoifQ==' decoded_bytes = base64.b64decode(encoded_bytes) print(decoded_bytes) # 👉️ b'' # 👇️ b'' print( base64.b64decode( encoded_bytes[:-2] + b'=======', validate=False ) ) # 👇️ True print(data == base64.b64decode( encoded_bytes[:-2] + b'=========', validate=False ) )
If your bytes-like object already has some padding, you have to set the validate keyword argument to False .
If validate is set to True , a binascii.Error error is raised if the padding is longer than 2 characters.
When the validate argument is set to False , the b64decode method truncates any extra padding automatically.
The default value for the validate keyword argument is False , so not passing it and setting it to False explicitly is equivalent.
# Creating a reusable function that pads the bytes
You can also create a reusable function that pads the bytes and base64 decodes them.
Copied!import re import base64 data = bytes('', encoding='utf-8') encoded_bytes = base64.b64encode(data) print(encoded_bytes) # b'eyJuYW1lIjogImJvYmJ5IGhhZHoifQ==' def decode_base64(encoded_bytes, altchars=b'+/'): encoded_bytes = re.sub( rb'[^a-zA-Z0-9%s]+' % altchars, b'', encoded_bytes) missing_padding_length = len(encoded_bytes) % 4 if missing_padding_length: encoded_bytes += b'=' * (4 - missing_padding_length) return base64.b64decode(encoded_bytes, altchars) bytes_without_padding = encoded_bytes[:-2] # 👇️ b'' print(decode_base64(bytes_without_padding))
The decode_base64 function:
- Takes an encoded bytes object as a parameter.
- Pads the bytes object sufficiently, so there is no missing padding.
- Base64 decodes the bytes object.
The re.sub() method is used to normalize the bytes object.
The method removes any non-Base64 characters and returns the result.
# Removing the prefix when decoding base64 image strings
If your string starts with a prefix of data:image/png;base64, , you have to remove it before base64 decoding it
Copied!from io import BytesIO import base64 from PIL import Image data = 'data:image/png;base64, iVBORw0KGgoAAAANSUhEUgAAAAUAAAAFCAYAAACNbyblAAAAHElEQVQI12P4//8/w38GIAXDIBKE0DHxgljNBAAO9TXL0Y4OHwAAAABJRU5ErkJggg==' im = Image.open(BytesIO(base64.b64decode(data.split(',')[1]))) im.save("my-image.png")
We used the str.split method to split the string on the comma and then accessed the element at index 1 (the second list element).
This effectively removes the data:image/png:base64 prefix from the string.
We can then pass the result to the base64.b64decode() method.
Make sure you have the Pillow module installed to be able to run the code sample.
Copied!pip install Pillow # 👇️ or with pip3 pip3 install Pillow
# Try using the base64.urlsafe_b64decode method instead
If the error persists, try to use the base64.urlsafe_b64decode method instead.
Copied!import base64 data = bytes('', encoding='utf-8') encoded_bytes = base64.b64encode(data) print(encoded_bytes) # b'eyJuYW1lIjogImJvYmJ5IGhhZHoifQ==' decoded_bytes = base64.urlsafe_b64decode(encoded_bytes) print(decoded_bytes) # 👉️ b''
The base64.urlsafe_b64decode method decodes the supplied bytes-like object or ASCII string using the URL and filesystem-safe alphabet.
The method substitutes + with — and / with _ in the standard Base64 alphabet.
The method returns the decoded bytes.
# Additional Resources
You can learn more about the related topics by checking out the following tutorials:
I wrote a book in which I share everything I know about how to become a better, more efficient programmer.