- Как я html-парсер на php писал, и что из этого вышло. Вводная часть
- Введение
- Что должен делать парсер?
- Разделяй и властвуй
- Что там насчет поиска элементов?
- Поиск children элементов
- Поиск текста
- Ошибки
- Script, style и комментарии
- Заключение
- Пишем простой парсер web страниц
- PHP HTML DOM парсер с jQuery подобными селекторами
Как я html-парсер на php писал, и что из этого вышло. Вводная часть
Сегодня я хочу рассказать, как написать html парсер, а также с какими проблемами я столкнулся, разрабатывая подобный парсер на php. А проблем было много. И в первой части я расскажу о проектировании парсера, и о возникших проблемах, ведь html парсер отличается от парсера привычных всем языков программирования.
Введение
Я старался написать текст этой статьи максимально понятно, чтобы любой, кто даже не знаком с общим устройством парсеров мог понять то, как работает html парсер.
Здесь и далее в статье я буду называть документ, содержащий html просто «Документ».
Dom дерево, находящееся в элементе, будет называться «Подмассив».
Что должен делать парсер?
Давайте сначала определимся, что должен делать парсер, чтобы в будущем отталкиваться от этого при разработке. А именно, парсер должен:
- Проектировать dom-дерево на основе документа
- Если есть ошибки в документе, то он должен их решать
- Находить элементы в dom-дереве
- Находить children элементы
- Находить текст
Впрочем, это мелочи. Основного функционала вполне хватит, чтобы поломать голову пару ночей напролет.
Но тут есть проблема, с которой я столкнулся сразу же: Html — это не просто язык, это язык гипертекста. У такого языка свой синтаксис, и обычный парсер не подойдет.
Разделяй и властвуй
Для начала, нужно разделить работу парсера на два этапа:
Для описания первого этапа я нарисовал схему, которая наглядно показывает, как обрабатываются данные на первом этапе:
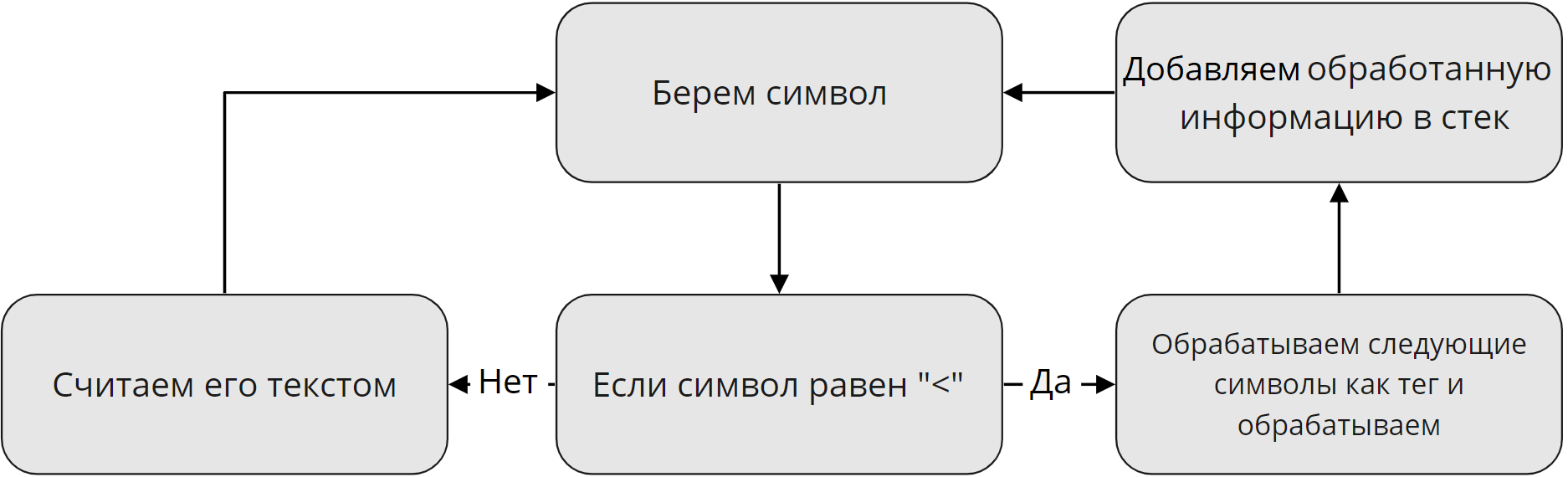
Я решил опустить все мелкие детали. Например, как отличить, что после открывающего »
Также тут стоит уточнить. Логично, что в документе помимо тегов есть еще и текст. Говоря простым языком, если парсер найдет открывающий тег и если в нем будет текст, он запишет его после открывающего тега в виде отдельного тега. Такой тег будет считаться как одиночный и не будет участвовать в дальнейшей работе парсера.
Ну и второй этап. Самый сложный с точки зрения проектирования, и самый простой на первый взгляд с точки зрения понимания:
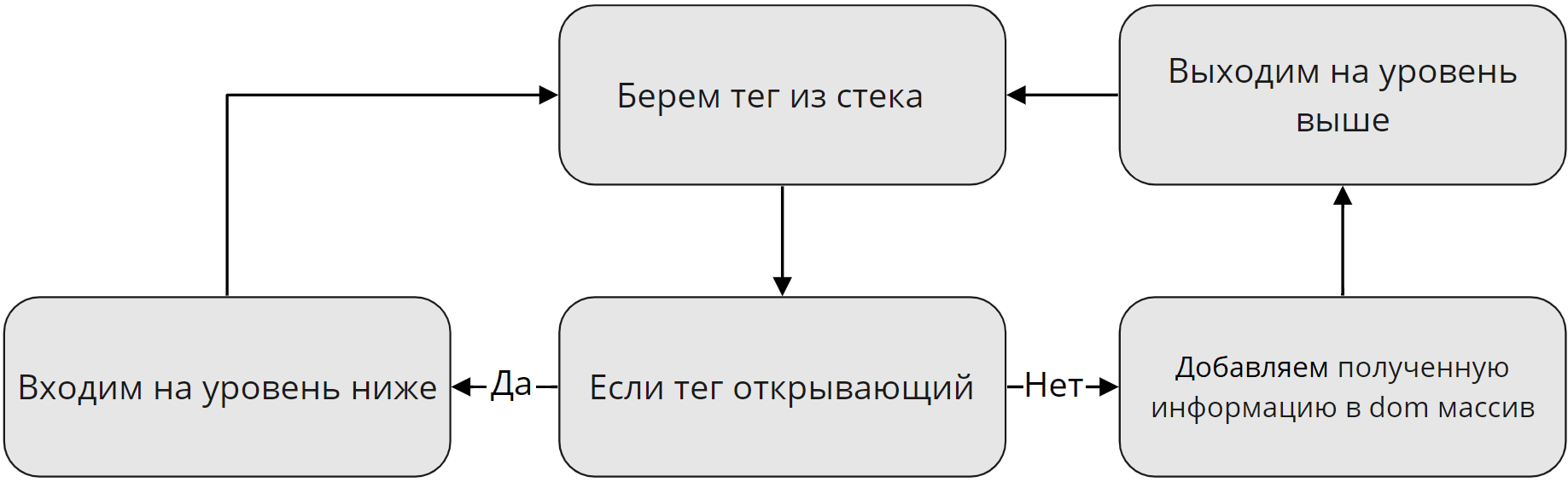
В данном случаи уровень означает уровень рекурсии. То есть если парсер нашел открывающий тег, он вызывает самого себя, «входит на уровень ниже», и так будет продолжаться до тех пор, пока не будет найден закрывающий тег. В этом случаи рекурсия выдает результат, «Выходит на уровень выше». Но, как обстоят дела с одиночными тегами? Такие теги считаются рекурсией ни как открывающие, ни как закрывающие. Они просто переходят в dom «Как есть».
В итоге у нас получится что-то вроде этого:
[0] => Array ( [is_closing] => [is_singleton] => [pointer] => 215 [tag] => div [0] => Array //открывается подмассив ( [0] => Array ( [is_closing] => [is_singleton] => [pointer] => 238 [tag] => div [id] => Array ( [0] => tjojo ) [0] => Array //открывается подмассив ( [0] => Array //Текст записывается в виде отдельного тега ( [tag] => __TEXT [0] => Привет! ) [1] => Array ( [is_closing] => 1 [is_singleton] => [pointer] => 268 [tag] => div ) ) ) ) ) Что там насчет поиска элементов?
А теперь давайте поговорим про поиск элементов. Но тут не все так однозначно, как можно подумать. Сначала стоит разобраться, по каким критериям мы ищем элементы. Тут все просто, мы ищем их по тем же критериям, как это делает Javascript: теги, классы и идентификаторы. Но тут проблема. Дело в том, что тег может быть только один, а вот классов и идентификаторов у одного элемента — множество, либо вообще не быть. Поэтому, поиск элемента по тегу будет отличаться от поиска по классу или идентификатору. Я нарисовал схему поиска по тегу, но не волнуйтесь: поиск по классу или идентификатору не особо отличаются.
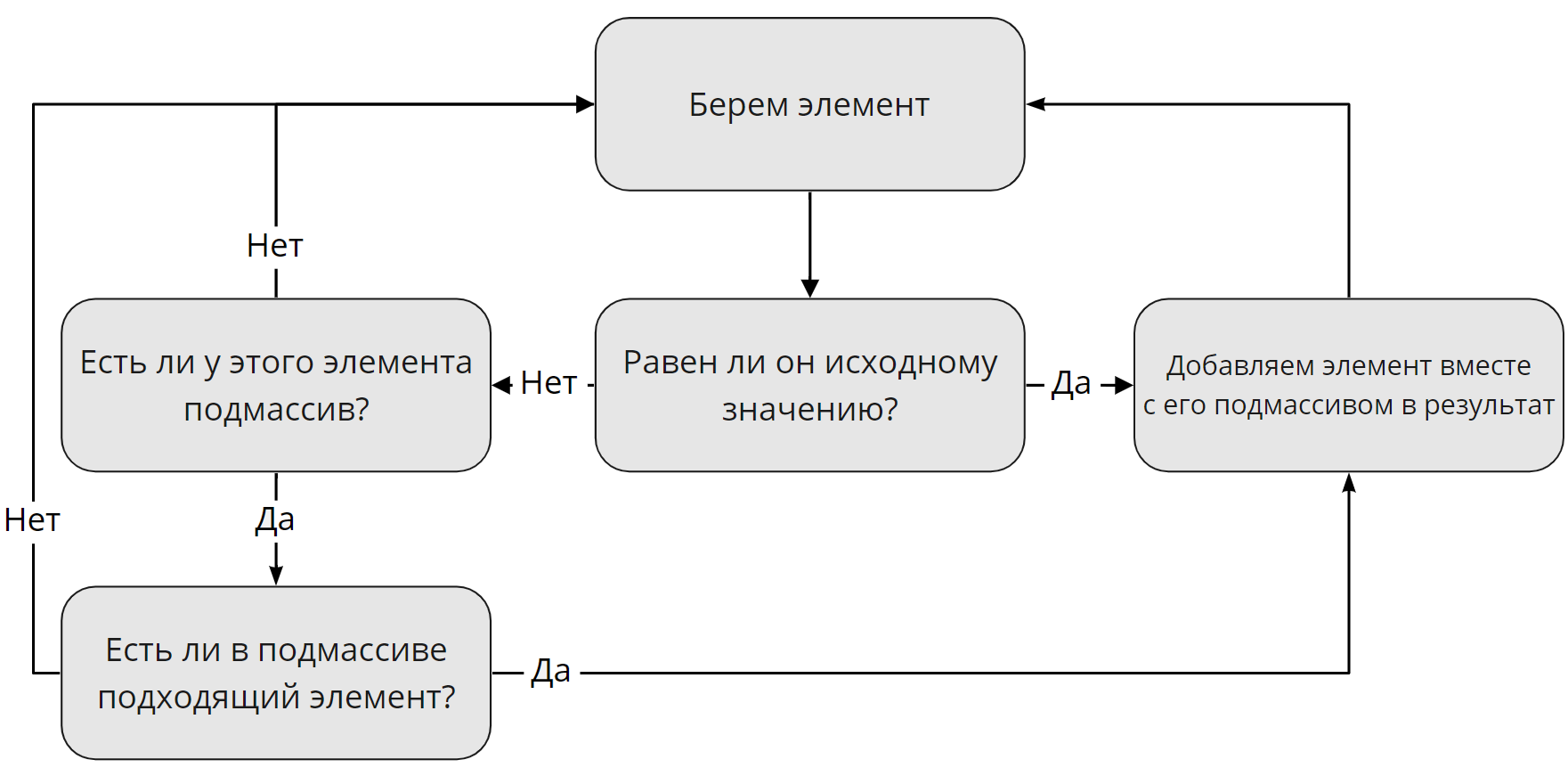
Немного уточнений. Под исходным значением я имел в виду название тега, «div» например. Также, если элемент не равен исходному значению, но у него есть подмассив с подходящим элементом, в результат запишется именно подходящий элемент с его подмассивом, если таковой существует.
Стоит также сказать, что у парсера будет функция, позволяющая искать определенный элемент в документе. Это заметно ускорит производительность парсера, что позволит ему выполняться быстрее. Можно будет, например, взять только первый найденный элемент, или пятый, как вы захотите. Согласитесь, в таком случаи парсеру будет гораздо проще искать элементы.
Поиск children элементов
Хорошо, с поиском элементов разобрались, а как насчет children элементов? Тут тоже все просто: наш парсер будет брать все вложенные подмассивы найденных до этого элементов, если таковые существуют. Если таковых нет, парсер выведет пустой результат и пойдет дальше:
![]()
Поиск текста
Тут говорить особо не о чем. Парсер просто будет брать весь полученный текст из подмассива и выводить его.
Ошибки
Документ может содержать ошибки, с которыми наш скрипт должен успешно справляться, либо, если ошибка критическая, выводить ее на экран. Тут будет приведен список всех возможных ошибок, о которых, в будущем, мы будем говорить:
- Символ «>» не был найден
Такая ошибка будет возникать в том случаи, если парсер дошел до конца документа и не нашел закрывающего символа «>». - Неизвестное значение атрибута
Данная ошибка сигнализирует о том, что была проведена попытка передачи значения атрибуту когда закрывающий тег был найден.
Script, style и комментарии
В парсере теги script и style будут сразу же пропускаться, поскольку я не вижу смысл их записывать. С комментариями ситуация другая. Если вы захотите из записывать, то вы сможете включить отдельную функцию скрипта, и тогда он будет их записывать. Комментарии будут записываться точно так же как и текст, то есть как отдельный тег.
Заключение
Эту статью скорее нужно считать небольшим экскурсом в тему парсеров html. Я ее написал для тех, кто задумывается над написанием своего парсера, либо для тех, кому просто интересно. Поверьте, это действительно весело!
Данная статья является первой вводной частью. В следующих частях этого цикла уже будет участвовать непосредственно код, и будет меньше картинок с алгоритмами(что прекрасно, потому что рисовать я их не умею). Stay tuned!
Пишем простой парсер web страниц

Здравствуйте. Меня зовут Сережа. Я хочу рассказать о том, как я писал простейшего вэб паука.
Поскольку это некоммерческий проект, созданный исключительно на моём энтузиазме, при работе я руководствовался следующим:
1. Минимум необходимых функций (сканирование web, сохранение необходимого в БД, простенький UI для доступа)
2. 0 финансовых затрат:
— В качестве сервера использую нетбук, который покупал в свое время для учебы acer aspare ONE KAV60, весьма бюджетный даже на момент покупки (2008 год), сейчас его процессора atom в 1600 МГц не хватает даже для нормальной работы в MS OFFICE
— Интернет — проводной домашний. Благо IP уже пол года не менялся, не пришлось заказывать статический
3. Минимум временых затрат. Проект делался после работы и дачи.
В качестве ПО использованы:
- ОС XUBUNTU
- Сервер ngINX
- nodeJS
- СУБД mySQL
- Для UI: jQuery, bootstrap3

Наш робот будет через определённые промежутки времени сканировать ресурс в поиске новых комментариев, которые будет вносить в БД, дабы всегда можно было посмотреть, что не понравилось модератору.
Нам потребуются следующие модули:
var jsdom = require("jsdom"); var mysql = require('mysql'); var CronJob = require('cron').CronJob; В основе нашего робота будет 2 функции:
// * * * Ищем ссылки на страницы function get_links()< jsdom.env('http://pikabu.ru',function(err, window)< if (err) return false; var page = window.document.getElementsByClassName('to-comments') for (var i=0; i) >Этой функцией мы запрашиваем главную страницу ресурса и ищем элементы с классом «.to-comments». В них хранятся ссылки на страницы с комментариями. Поскольку эти элементы идут впаре, нам нужен только каждый второй.
В данной функции нам очень помогает модуль jsdom. Он преобразует html код в DOM дерево, в котором мы легко можем найти нужный элемент.
Как мы видим, эта функция вызывает get_comments()
function get_comments(link) < jsdom.env(link,function(err, window)< if (err) return false; var comment = window.document.getElementsByClassName('comment') for (var i=0; i0 && block[0].textContent.substr(0,11)=='Комментарий') < console.log(block[0].baseURI+'#comment_'+id); continue>var com = comment[i].getElementsByClassName('comment_text')[0].outerHTML.replace(/"/g, '"').replace(/\n|\t/g, '').replace('previews_gif_comm', 'big_size_comm_an'); var query = 'INSERT IGNORE comments (id, user, comment) VALUES ('+id+', "'+author+'", "'+com+'")'; DBconnection.query(query, function(err, rows, fields) < if (err) throw err; >); > console.log(new Date()+' DATA ADDED. '); >); >Здесь мы также пробегаемся по дереву, ищем элементы с классом «comment», выделяем из них нужные элементы: id комментария, автора, отсеиваем удаленные комменты, убираем спецсимволы, немного переделываем код (убираем превьюшки) и заносим всё это в БД. В таблице comments поле id уникально, поэтому mySQL сама следит, чтобы не было дублированных комментариев.
Нам осталось завести таймер, пробуждающий робота каждые 5 минут. В node.JS это можно реализовать при помощи модуля croneJob — аналог планировщика crone в linux.
var job = new CronJob('*/5 * * * *', function()< get_links(); >); job.start(); На этом пока всё. Наш паук научился лазить по ресурсу и сохранять комментарии. Если хотите могу написать статью, про вэб интерфейс к этому роботу или про плагин хрома для этого робота.
PHP HTML DOM парсер с jQuery подобными селекторами
Добрый день, уважаемые хабровчане. В данном посте речь пойдет о совместном проекте S. C. Chen и John Schlick под названием PHP Simple HTML DOM Parser (ссылки на sourceforge).
Идея проекта — создать инструмент позволяющий работать с html кодом используя jQuery подобные селекторы. Оригинальная идея принадлежит Jose Solorzano’s и реализована для php четвертой версии. Данный же проект является более усовершенствованной версией базирующейся на php5+.
В обзоре будут представлены краткие выдержки из официального мануала, а также пример реализации парсера для twitter. Справедливости ради, следует указать, что похожий пост уже присутствует на habrahabr, но на мой взгляд, содержит слишком малое количество информации. Кого заинтересовала данная тема, добро пожаловать под кат.
Получение html кода страницы
$html = file_get_html('http://habrahabr.ru/'); //работает и с https:// Товарищ Fedcomp дал полезный комментарий насчет file_get_contents и 404 ответа. Оригинальный скрипт при запросе к 404 странице не возвращает ничего. Чтобы исправить ситуацию, я добавил проверку на get_headers. Доработанный скрипт можно взять тут.
Поиск элемента по имени тега
foreach($html->find('img') as $element) < //выборка всех тегов img на странице echo $element->src . '
'; // построчный вывод содержания всех найденных атрибутов src > Модификация html элементов
$html = str_get_html('HelloWorld'); // читаем html код из строки (file_get_html() - из файла) $html->find('div', 1)->class = 'bar'; // присвоить элементу div с порядковым номером 1 класс "bar" $html->find('div[id=hello]', 0)->innertext = 'foo'; // записать в элемент div с текст foo echo $html; // выведет fooWorld Получение текстового содержания элемента (plaintext)
echo file_get_html('http://habrahabr.ru/')->plaintext; Целью статьи не является предоставить исчерпывающую документацию по данному скрипту, подробное описание всех возможностей вы можете найти в официальном мануале, если у сообщества возникнет желание, я с удовольствием переведу весь мануал на русский язык, пока же приведу обещанный в начале статьи пример парсера для twitter.
Пример парсера сообщений из twitter
require_once 'simple_html_dom.php'; // библиотека для парсинга $username = 'habrahabr'; // Имя в twitter $maxpost = '5'; // к-во постов $html = file_get_html('https://twitter.com/' . $username); $i = '0'; foreach ($html->find('li.expanding-stream-item') as $article) < //выбираем все li сообщений $item['text'] = $article->find('p.js-tweet-text', 0)->innertext; // парсим текст сообщения в html формате $item['time'] = $article->find('small.time', 0)->innertext; // парсим время в html формате $articles[] = $item; // пишем в массив $i++; if ($i == $maxpost) break; // прерывание цикла > Вывод сообщений
for ($j = 0; $j < $maxpost; $j++) < echo ''; echo '' . $articles[$j]['text'] . '
'; echo '' . $articles[$j]['time'] . '
'; echo ''; > Благодарю за внимание. Надеюсь, получилось не очень тяжеловесно и легко для восприятия.
Похожие библиотеки
P.S.
Хаброжитель Groove подсказал что подобные материалы уже были
P.P.S.
Постараюсь в свободное время собрать все библиотеки и составить сводные данные по производительности и приятности использования.