- Properties files java encoding
- Internationalization Enhancements in JDK 11
- Unicode 10.0.0
- Internationalization Enhancements in JDK 10
- Additional Unicode Language-Tag Extensions
- Internationalization Enhancements in JDK 9
- Unicode 8.0
- CLDR Locale Data Enabled by Default
- UTF-8 Properties Files
- Properties File — encoding
- How to configure encoding for Spring boot to read
- How to read from property file containing utf 8 character in java
- Conclusion
- Damir’s Corner .
- Netbeans — .properties files default encoding | Strange behaviour
- Case 1
- Case 2
- Case 3
- Question:
Properties files java encoding
Recent releases of the JDK include enhancements to the internationalization process to support updated standards.
Internationalization Enhancements in JDK 11
Internationalization enhancements for JDK 11 include:
Unicode 10.0.0
Support has been added for Unicode 10.0.0. Java Platform, Standard Edition (Java SE) 9 and 10 supported Unicode 8.0.
The Unicode 10.0 standard includes 16,018 characters and 10 scripts that were introduced since Unicode 8.0, all of which are supported in Java SE 11.
Internationalization Enhancements in JDK 10
Internationalization enhancements for JDK 10 include:
Additional Unicode Language-Tag Extensions
The IETF BCP (best current practice) 47 language tags standard, which has been supported in the Locale class since Java SE 7, includes a Unicode extension subtag. As of Java SE 9, only the -ca (calendar) and -nu (number) extensions are supported.
Java SE 10 adds support for the following additional extensions in the relevant JDK classes:
- -cu (currency type)
- -fw (first day of week)
- -rg (region override)
- -tz (time zone)
In JDK 10, if an application specifies a locale of en-US-u-cu-EUR , which means US English with Euro currency, java.util.Currency.getInstance(locale) instantiates a Euro Currency . If the locale is en-US-u-cu-JPY , a Japanese Yen Currency is instantiated.
Internationalization Enhancements in JDK 9
Internationalization enhancements for Oracle Java Development Kit 9 include:
Unicode 8.0
Support has been added for Unicode 8.0. Java Platform, Standard Edition (Java SE) 8 supported Unicode 6.2.
The Unicode 6.3, 7.0, and 8.0 standards introduced 10,555 characters, 29 scripts, and 42 blocks, all of which are supported in Java SE 9.
CLDR Locale Data Enabled by Default
The XML-based locale data of the Unicode Common Locale Data Repository (CLDR), first added in JDK 8, is the default locale data in JDK 9. In previous releases, the default was JRE .
There are four distinct sources for locale data, identified by the following keywords:
- CLDR represents the locale data provided by the Unicode CLDR project.
- HOST represents the current user’s customization of the underlying operating system’s settings. It works only with the user’s default locale, and the customizable settings may vary depending on the operating system. However, primarily date, time, number, and currency formats are supported.
- SPI represents the locale-sensitive services implemented by the installed Service Provider Interface (SPI) providers.
- COMPAT (formerly called JRE ) represents the locale data that is compatible with releases prior to JDK 9. JRE can still be used as the value, but COMPAT is preferred.
To select a locale data source, use the java.locale.providers system property, listing the data sources in the preferred order. If a provider cannot offer the requested locale data, the search proceeds to the next provider in order. For example:
java.locale.providers=HOST,SPI,CLDR,COMPATIf you do not set this property, the default behavior is equivalent to the following setting:
java.locale.providers=CLDR,COMPAT,SPITo enable behavior that is compatible with JDK 8, set the java.locale.providers system property to a value with COMPAT to the left of CLDR .
UTF-8 Properties Files
In Java SE 9, properties files are loaded in UTF-8 encoding. In previous releases, ISO-8859-1 encoding was used for loading property resource bundles. UTF-8 is a much more convenient way to represent non-Latin characters.
Most existing properties files should not be affected: UTF-8 and ISO-8859-1 have the same encoding for ASCII characters, and human-readable non-ASCII ISO-8859-1 encoding is not valid UTF-8. If an invalid UTF-8 byte sequence is detected, the Java runtime automatically rereads the file in ISO-8859-1.
java.util.PropertyResourceBundle.encoding=ISO-8859-1Properties File — encoding
This tutorial explains step by step to read and write a properties file in spring boot with encoding default and UTF-8 example with example.
Sometimes, We want to read the properties file that contains non-English characters.
For example, the properties file contains UTF-8 encoding characters. The default encoding for properties file reading is ISO-8859-1 .
Spring framework loads the properties file in default encoding.
In this tutorial, you will learn how to read and write the content of a property file with a specified encoding in Java.
How to configure encoding for Spring boot to read
In this example, you will learn how to Read keys and their values from a property file spring boot application.
Let’s have a properties file — application_fr.properties which contains non-English characters.
There are many ways properties file read in spring core and boot applications.
create a Bean object returning PropertiesFactoryBean using the @Bean annotation
set encoding using setFileEncoding method
configure to read properties file from ClassPathResource setLocation method
Next, you can access the properties file mapped to member variables using @Value annotation with the below syntax
Another way, using @PropertySource annotation with value contains the name of file and encoding to `UTF-8
@PropertySource(value = “classpath:/application_properties.properties”, encoding=“UTF-8”)
read individual properties with the getProperty method with encoding
How to read from property file containing utf 8 character in java
Reading properties file is an easy way to do it in java.
You can apply encoding for file input stream as seen in the below example
catch (FileNotFoundException fie) < fie.printStackTrace(); >catch (IOException e) < e.printStackTrace(); >System.out.println(properties.getProperty("hostname")); Set keys = properties.stringPropertyNames(); for (String key : keys) < System.out.println(key + " - " + properties.getProperty(key)); >> > Conclusion
You learned how to configure properties files to read UTF-8 character encoding in spring framework and boot as well as Java.
Damir’s Corner .
In Java, .properties files are used for storing key-value pairs, most typically for text localization. However, by default they are saved in ISO-8859-1 encoding, not in Unicode. Since many languages use characters not included in this encoding, these characters will need to be expressed using Unicode escape sequences.
This means that the following contents using Unicode literals would not be valid for a .properties file in ISO-8859-1 encoding:
To be correctly interpreted, these characters must be represented with Unicode escape sequences:
unicode=\u010D\u0161\u017E\u010C\u0160\u017D Of course, such files are inconvenient to read and edit.
Fortunately, IntelliJ IDEA can automatically handle conversion between the Unicode literals and their corresponding escape sequences. The feature is named Transparent native-to-ascii conversion and is not enabled by default. It is located on the Editor > File Encodings page of the Settings window.
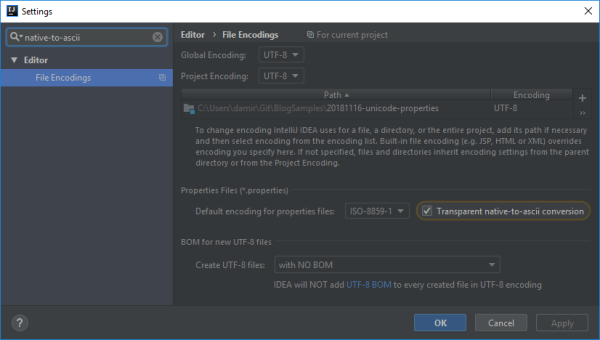
When this setting is enabled, Unicode escape sequences in .properties files will be rendered as regular Unicode literals, but they will still be saved as escape sequences so that the Java code will be able to interpret them correctly.
Since Java 1.6, it’s also possible to specify the encoding when loading the contents from a .properties file by using the Properties.load method overload accepting a Reader ) instead of passing it the InputStream directly:
Properties properties = new Properties(); InputStream stream = Thread.currentThread().getContextClassLoader() .getResourceAsStream("strings.properties"); InputStreamReader reader = new InputStreamReader(stream, StandardCharsets.UTF_8); properties.load(reader); If you use this approach, you’ll still need to specify the correct encoding for .properties files in IntelliJ IDEA settings:
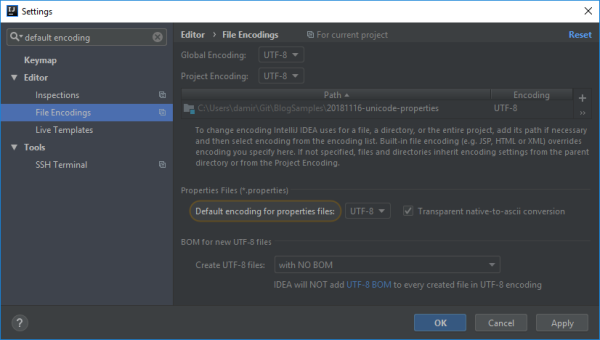
Of course, this is only an option if you’re starting a new project and have the whole stack under your control, i.e. you are writing the code for loading the .properties files yourself. Otherwise, you’ll be stuck with ISO-8859-1 encoding and will have to use IntelliJ IDEA’s transparent conversion feature.
If you’re looking for online one-on-one mentorship on a related topic, you can find me on Codementor.
If you need a team of experienced software engineers to help you with a project, contact us at Razum.
Netbeans — .properties files default encoding | Strange behaviour
I have a problem with .properties files in Netbeans. I use such files in order to provide some localized strings in my app.
Case 1
If I create a new .properties file in Netbeans ( New -> Properties File ) and I but some lines there:
INFO_OEFFNEN=Открыть информацию FILE=Файл SPRACHE=Язык 
everything works fine and all strings are translated properly: But if I open this file by means of Notepad++ I see what follows (Notepad++ recognizes the encoding, maybe incorrectly, as UTF-8 ):
INFO_OEFFNEN=\u041e\u0442\u043a\u0440\u044b\u0442\u044c \u0438\u043d\u0444\u043e\u0440\u043c\u0430\u0446\u0438\u044e FILE=\u0424\u0430\u0439\u043b SPRACHE=\u042f\u0437\u044b\u043a Case 2
INFO_OEFFNEN=Открыть информацию FILE=Файл SPRACHE=Язык INFO_OEFFNEN=ÐÑкÑÑÑÑ Ð¸Ð½ÑоÑмаÑÐ¸Ñ FILE=Файл SPRACHE=ЯзÑк 
In GUI I can see something very strange:
Case 3

I make the same as in case 2 but I in Netbeans I set the » use project encoding » property of a .properties file to true . Now in Netbeans editor I see correct text (but 100% marked as «modified» by SVN). When I start the App strings looks like this:
Question:
I assume that the default encoding of properties files created by Netbeans is not UTF-8. How can I check which encoding does Netbeans use by default in this case? I would like to write a short Java app which reads a .properties file (created by Netbeans), adds or replaces some lines and creates a new file which should be read by Netbeans correctly. Which encoding should I use in InputStreamReader ? Please give me some tips about this problem. Is my assumption about different default encoding in Netbeans correct? I’m affraid I don’t understand some important issue here. Some addional info:
- Netbeans project encoding: UTF-8 - Help->About: *NetBeans IDE 8.1 (Build 201510222201) *Java: 1.8.0_92; Java HotSpot(TM) 64-Bit Server VM 25.92-b14 *System: Windows 7 version 6.1 running on amd64; UTF-8; de_DE (nb)