- Как строить красивые графики на Python с Seaborn
- Что такое Seaborn?
- Установка Seaborn
- Строим первые графики
- Динамика в деле: интерактивные графики в Dash
- Многомерные графики в Python — от трёхмерных и до шестимерных
- Давайте подготовим данные
- Двухмерная диаграмма рассеяния
- Диаграмма рассеяния в 3D
- Добавление четвёртого измерения
- Добавление пятого измерения
- Добавление шестого измерения
- Можем ли мы добавить больше измерений?
- Исходный код
Как строить красивые графики на Python с Seaborn

Визуализация данных — это метод, который позволяет специалистам по анализу данных преобразовывать сырые данные в диаграммы и графики, которые несут ценную информацию. Диаграммы уменьшают сложность данных и делают более понятными для любого пользователя.
Есть множество инструментов для визуализации данных, таких как Tableau, Power BI, ChartBlocks и других, которые являются no-code инструментами. Они очень мощные, и у каждого своя аудитория. Однако для работы с сырыми данными, требующими обработки, а также в качестве песочницы, Python подойдет лучше всего.
Несмотря на то, что этот путь сложнее и требует умения программировать, Python позволит вам провести любые манипуляции, преобразования и визуализировать ваши данные. Он идеально подходит для специалистов по анализу данных.
Python — лучший инструмент для data science и этому много причин, но самая важная — это его экосистема библиотек. Для работы с данными в Python есть много замечательных библиотек, таких как numpy , pandas , matplotlib , tensorflow .
Matplotlib , вероятно, самая известная библиотека для построения графиков, которая доступна в Python и других языках программирования, таких как R. Именно ее уровень кастомизации и удобства в использовании ставит ее на первое место. Однако с некоторыми действиями и кастомизациями во время ее использования бывает справиться нелегко.
Разработчики создали новую библиотеку на основе matplotlib , которая называется seaborn . Seaborn такая же мощная, как и matplotlib , но в то же время предоставляет большую абстракцию для упрощения графиков и привносит некоторые уникальные функции.
В этой статье мы сосредоточимся на том, как работать с seaborn для создания первоклассных графиков. Если хотите, можете создать новый проект и повторить все шаги или просто обратиться к моему руководству по seaborn на GitHub.
Что такое Seaborn?
Seaborn — это библиотека для создания статистических графиков на Python. Она основывается на matplotlib и тесно взаимодействует со структурами данных pandas.
Архитектура Seaborn позволяет вам быстро изучить и понять свои данные. Seaborn захватывает целые фреймы данных или массивы, в которых содержатся все ваши данные, и выполняет все внутренние функции, нужные для семантического маппинга и статистической агрегации для преобразования данных в информативные графики.
Она абстрагирует сложность, позволяя вам проектировать графики в соответствии с вашими нуждами.
Установка Seaborn
Установить seaborn так же просто, как и любую другую библиотеку, для этого вам понадобится ваш любимый менеджер пакетов Python. Во время установки seaborn библиотека установит все зависимости, включая matplotlib , pandas , numpy и scipy .
Давайте уже установим seaborn и, конечно же, также пакет notebook , чтобы получить доступ к песочнице с данными.
pipenv install seaborn notebookПомимо этого, перед началом работы давайте импортируем несколько модулей.
import seaborn as sns import pandas as pd import numpy as np import matplotlibСтроим первые графики
Перед тем, как мы начнем строить графики, нам нужны данные. Прелесть seaborn в том, что он работает непосредственно с объектами dataframe из pandas , что делает ее очень удобной. Более того, библиотека поставляется с некоторыми встроенными наборами данных, которые можно использовать прямо из кода, и не загружать файлы вручную.
Давайте посмотрим, как это работает на наборе данных о рейсах самолетов.
flights_data = sns.load_dataset("flights") flights_data.head()Динамика в деле: интерактивные графики в Dash
Dash представляет собой фреймворк для визуализации данных и построения веб-приложений, понятен и довольно прост в применении. Может быть интересен тем, кто хочет использовать интерактивные графики для анализа данных с помощью Python. Рассмотрим построение таких графиков с применением обратных вызовов в Dash.
Фреймворк Dash позволяет создавать веб-приложения с визуализацией различной информации, в частности – графиков. Несомненно, такая функция фреймворка очень полезна для специалиста по анализу данных.
Dash в основном использует «под капотом» Plotly.js (построение диаграмм), Flask (веб-сервер) и React (веб-интерфейс). Вам не нужно разбираться в этих технологиях, чтобы успешно применять Dash в своей работе, достаточно просто иметь базовые знания в Python и представлять, какие графики вы хотите видеть на своем дэшборде.
Интерактивность графических элементов – это способность таких элементов реагировать на действия пользователя (изменяться и перестраиваться в зависимости от выбранных параметров). В Dash данная ответная реакция возможна за счет обратных вызовов (callback). Такие графики динамичны, способны эффективно и наглядно отобразить самую разную информацию об исследуемых данных.
Подробнее про Dash и его функционал советую читать в документации.
Приведу пример создания простого веб-приложения с использованием интерактивных графических элементов фреймворка Dash.
Всю предобработку данных я буду проводить в Jupyter Notebook, а код для дэшборда писать в Visual Studio Code.
Для работы будем использовать датасет с соревнования kaggle: Video Game Sales with Ratings. В нем приведена информация по продажам видео игр с их рейтингами и оценками.
Поставим себе следующую задачу: пусть мы хотим отобразить на дэшборде график зависимости оценок игр от их жанров и гистограмму рейтингов игр по годам, начиная с 2000 года. Наши интерактивные графики должны реагировать на изменение фильтров по жанрам, рейтингам и годам. Для проверки будем выводить еще и интерактивный текст – результат фильтрации (сколько игр соответствует выбранным фильтрам).
Предварительно обработаем данные – оставим только интересующие нас параметры, удалим записи с пропусками и т.п. Код размещен в репозитории на github

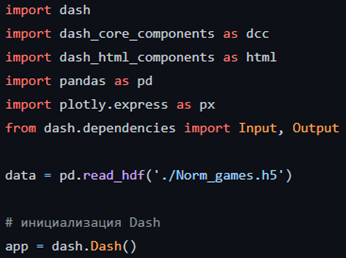
Итак, начало кода стандартно для работы с Dash: импортируем необходимые модули, загружаем обработанные данные и инициализируем Dash
Создадим переменные со всеми жанрами и рейтингами для дальнейшего создания фильтров

Начнем определение внешнего вида нашего приложения. Для этого будем использовать атрибут layout нашего класса Dash. Прописываем в нем древовидную структуру Html-элементов – родительский html.Div и дочерние элементы заголовка (html.H1) и абзаца (html.P). Также зададим элементарный стиль – цвет и положение фона, на котором будет отображаться заданный текст. Далее увидим, что удобно задавать общий стиль для элементов, оборачивая их в один html.Div

Посмотрим, что у нас получилось. Для того, чтобы веб-приложение открывалось, необходимо вызвать в коде его запуск

Запустим само приложение. Результат:

Теперь добавим в layout фильтры с множественным выбором и заготовку для интерактивного текста. В стиле укажем желаемое положение элементов на веб-странице и цвет фона
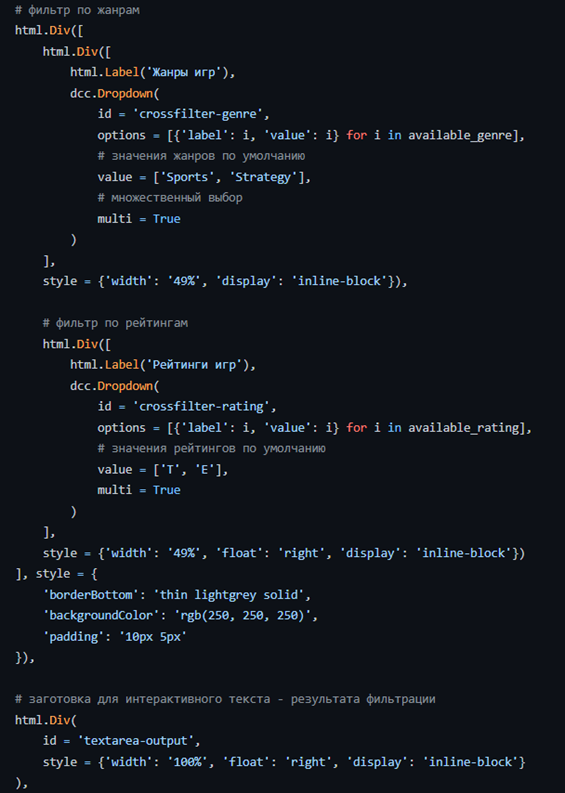
Замечу, что html.Label – подпись к элементу интерфейса, a dcc.Dropdown – выпадающий список.
При запуске видим фильтры жанров и рейтингов, интерактивный текст отобразим позже

Наконец, добавим заготовку для графиков и фильтр по годам (в виде слайдера). График зависимости оценок игр от их жанров зададим как диаграмму рассеяния

Результат – фильтр по годам и заготовка для графиков

Пришло время добавить в дэшборд немного динамики. Начнем с создания декоратора (app.callback) для результата фильтрации
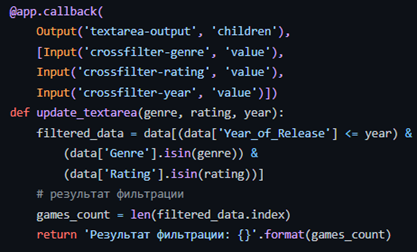
С изменением входных данных Input (значения фильтров) будут изменяться и выходные данные Output (область текста). Количественный результат фильтрации сохранится в переменной games_count, которую и вернет Output.
Фильтры по умолчанию, результат фильтрации – 712 игр

Добавим жанр Misc, результат фильтрации изменит значение на 895

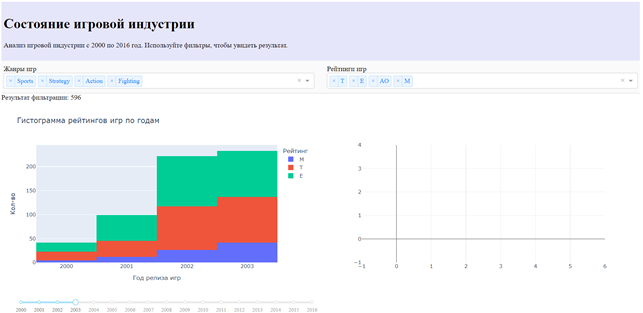
Теперь немного сложнее, создадим декоратор для гистограммы рейтингов игр по годам

Теперь Output будет возвращать график, который создается в функции update_stacked_area (переменная figure).

Добавим жанров и рейтингов, зададим год релиза – до 2003. График автоматически перестраивается
По аналогии напишем код для графика зависимости оценок игр от их жанров – будем использовать scatter plot (диаграмму рассеяния). По оси x будет оценка пользователей, по y – оценка критиков

Посмотрим на итоговый результат работы интерактивного дэшборда. Фильтры по умолчанию

Добавим жанров и рейтингов, зададим год релиза – до 2014. Интерактивный текст и графики изменятся в соответствии с заданными фильтрами

Полный код размещен в репозитории на github.
Описанный пример обзорно позволяет погрузиться в создание и работу интерактивных графиков в Dash. Это отличный инструмент для специалистов по обработке и анализу данных, который позволяет качественно и быстро визуализировать желаемую информацию.
Попробуйте создать свои собственные интерактивные графики в Dash!
Многомерные графики в Python — от трёхмерных и до шестимерных
Визуализация — важная часть анализа данных, а способность посмотреть на несколько измерений одновременно эту задачу облегчает. В туториале мы будем рисовать графики вплоть до 6 измерений.
Plotly — это питоновская библиотека с открытым исходным кодом для разнообразной визуализации, которая предлагает гораздо больше настроек, чем известные matplotlib и seaborn. Модуль устанавливается как обычно — pip install plotly. Его мы и будем использовать для рисования графиков.
Давайте подготовим данные
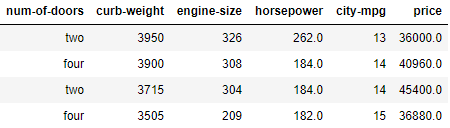
Для визуализации мы используем простые данные об автомобилях от UCI (Калифорнийский университет в Ирвине — прим. перев.), которые представляют собой 26 характеристик для 205 машин (26 столбцов на 205 строк). Для визуализации шести измерений мы возьмём такие шесть параметров.
Загрузим данные из CSV с помощью pandas.
import pandas as pd data = pd.read_csv("cars.csv")Теперь, подготовившись, начнем с двух измерений.
Двухмерная диаграмма рассеяния
Диаграмма рассеяния — весьма простой и распространенный график. Из 6 параметров, price и curb-weight используются ниже как Y и X соответственно.
# Импорт необходимых модулей import plotly import plotly.graph_objs as go # Создаём figure fig1 = go.Scatter(x=data['curb-weight'], y=data['price'], mode='markers') # Создаём layout mylayout = go.Layout(xaxis=dict(title="curb-weight"), yaxis=dict( title="price")) # Строим диаграмму и сохраняем HTML plotly.offline.plot(, auto_open=True)В plotly процесс немного отличен от аналогичного в Matplotlib. Мы должны создать layout и figure, передав их в функцию offline.plot, после чего результат будет сохранён в HTML файл в текущей рабочей директории. Вот скриншот того, что получится. В конце статьи будет ссылка на GitHub репозиторий с готовыми интерактивными HTML-графиками.
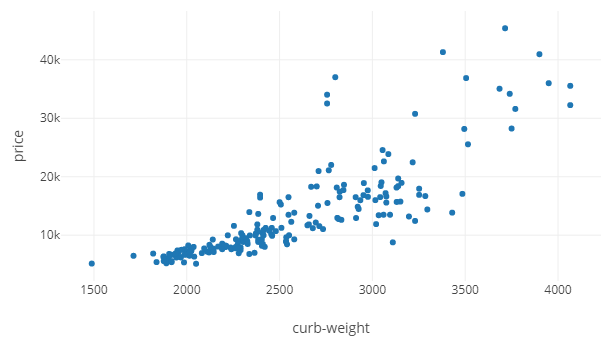
Диаграмма рассеяния в 3D
Мы можем добавить третий параметр horsepower (количество лошадиных сил) на ось Z. Plotly предоставляет функцию Scatter3D для построения интерактивных трёхмерных графиков.

Вместо того чтобы вставлять код сюда каждый раз, я добавлял его в репозиторий.
(Удобнее всего смотреть релевантный код в соседней вкладке параллельно со чтением — прим. перев.)
Добавление четвёртого измерения
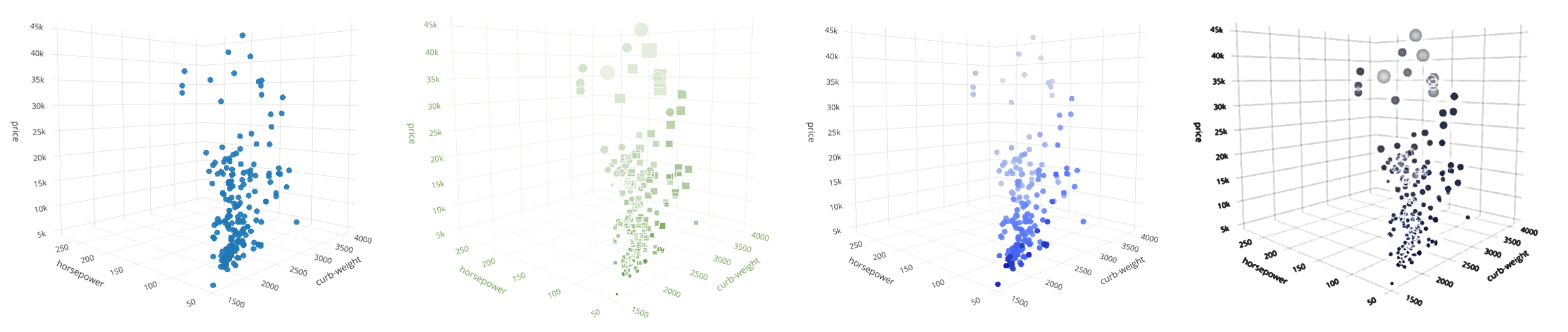
Мы знаем, что использовать больше трёх измерений напрямую нельзя, но есть обходной путь: мы можем эмулировать глубину для визуализации более высоких измерений с помощью цвета, размера или формы.
Здесь, наряду с тремя предыдущими характеристиками, мы будем использовать пробег в городских условиях — city-mpg как четвертое измерение, за которое будет отвечать параметр markercolor функции Scatter3D. Более светлый оттенок маркера будет означать меньший пробег.
Сразу же бросается в глаза, что чем выше цена, количество лошадей и масса, тем меньше будет пробег.

Добавление пятого измерения
Размер маркера можно использовать для визуализации 5-го измерения. Мы используем характеристику engine-size (размер двигателя) для параметра markersize функции Scatter3D.
Наблюдения: размер двигателя связан с некоторыми из предыдущих параметров. Чем выше цена, тем больше двигатель. Ра́вно как и: ниже пробег — больше двигатель.
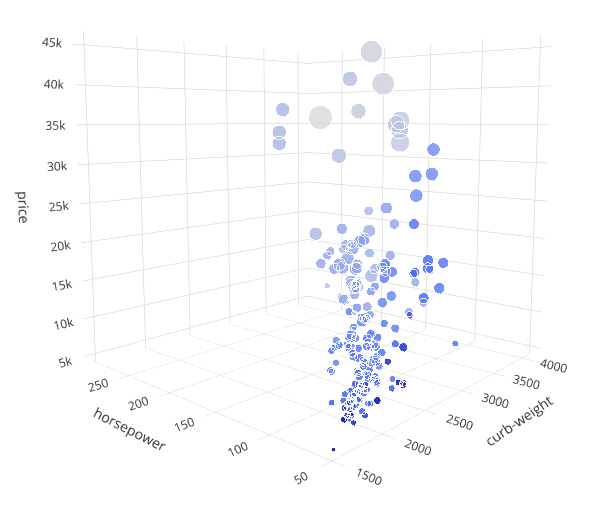
Добавление шестого измерения
Форма маркера отлично подходит для визуализации категорий. Plotly даёт на выбор 10 различных фигур для 3D графика (звёздочка, круг, квадрат и т.д.). Таким образом, в качестве формы можно показать до 10 различных значений.
У нас есть характеристика num-of-doors, которая содержит целые числа — количество дверей (2 или 4). Преобразуем эти значения в фигуры: квадрат для 4 дверей, круг для 2 дверей. Используется параметр markersymbol функции Scatter3D.
Наблюдения: такое чувство, что у всех самых дешёвых машин по 4 двери (круги). Продолжая изучать график, можно будет сделать больше предположений и выводов.
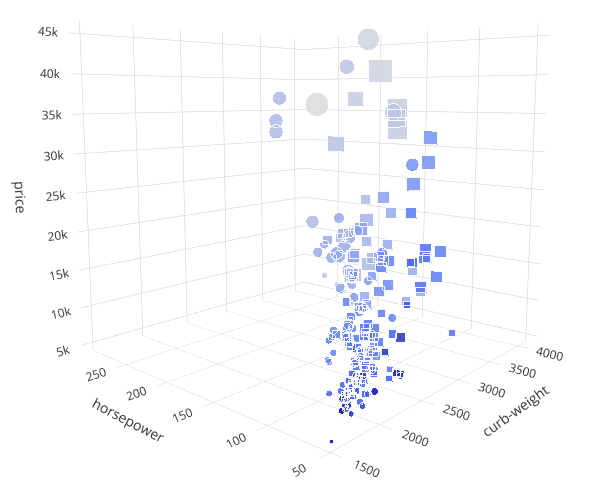
6D график с формой маркера в качестве шестого измерения (количество дверей)
Можем ли мы добавить больше измерений?
Конечно можем! У маркеров есть больше свойств, таких как непрозрачность и градиенты, которые можно задействовать. Но чем больше измерений мы добавляем, тем труднее удержать их все в голове.
Исходный код
Код на Python и интерактивные графики для всех фигур доступны на GitHub здесь.