PHP and regex: how to preg_match on multiple line?
You can also use to activate mode, allowing the dot to match across lines In PHP you can do this: Question: I have a string that contains normal characters, white charsets and newline characters between
and
. To them, a word boundary is simply a position that is either preceded by a word character and not followed by one, or followed by a word character and not preceded by one: So the position after the in first first test would only be a word boundary if it were followed by another word character ( ; in some regex flavors the definition is based on a broader range of characters, including accented English letters and letters from other scripts, but in PHP it’s only ASCII letters and digits).
PHP and regex: how to preg_match on multiple line?
line1 line2 line3 59800 line4 line5 line6
My goal is to capture: (25 left characters)59800(25 right characters):
How do I capture multiple lines?
Here is the test: http://regexr.com/39498
Instead of m , use the s (DOTALL) flag in your regex:
The s modifier is used to make DOT match newlines as well where m is used to make anchors ^ and $ match in each line of multiline input.
You don’t need the i flag as there are no letters mentioned in the regex
The g flag doesn’t exist in PHP.
You can also use (?s) to activate DOTALL mode, allowing the dot to match across lines
$regex = '~(?s).59800.~'; if (preg_match($regex, $yourstring, $m)) < $thematch = $m[0]; >else < // No match. >
PHP: Is it better to concatenate on 1 line or multiple, a) Creating a multi-line response so the code somewhat mimics what the user will see. I’ve found it makes it easier to catch typos and mistakes this way. I’ve found it makes it easier to catch typos and mistakes this way.
How to make dot match newline characters using regular expressions
I have a string that contains normal characters, white charsets and newline characters between
and
.
This regular expression doesn’t work: /(.*) . It is because .* doesn’t match newline characters. How can I do this?
You need to use the DOTALL modifier ( /s ).
This might not give you exactly what you want because you are greedy matching. You might instead try a non-greedy match:
You could also solve this by matching everything except ‘
Another observation is that you don’t need to use / as your regular expression delimiters. Using another character means that you don’t have to escape the / in
, improving readability. This applies to all the above regular expressions. Here’s it would look if you use ‘#’ instead of ‘/’:
However all these solutions can fail due to nested divs, extra whitespace, HTML comments and various other things. HTML is too complicated to parse with Regex, so you should consider using an HTML parser instead.
To match all characters, you can use this trick:
You can also use the (?s) mode modifier. For example,
There shouldn’t be any problem with just doing:
This matches either any character except newline or a newline, so every character. It solved it for me, at least.
Regex — php multiline preg_match_all, Sorted by: 1. Just as I mentioned in the comments, you should be very careful with greedy patterns, only use them when you need to obtain the largest substring possible including subblocks. In other cases, when you need individual substrings, use lazy matching. Here is a fixed regex:
Matching pattern with dot in PHP
I need to find and replace substring with dot in it. It’s important to keep search strict to word boundaries (\b). Here’s an example script to reproduce (i need to match «test.»):
x:\>php 1.php no match 1 x:\>php -v PHP 5.2.8 (cli) (built: Dec 8 2008 19:31:23) Copyright (c) 1997-2008 The PHP Group
BTW, I also don’t get any match if there’re square brackets in search pattern. I do escape them of course, but still no effect.
Regexes can’t read; they don’t really know what a «word» is. To them, a word boundary is simply a position that is either preceded by a word character and not followed by one, or followed by a word character and not preceded by one:
So the position after the . in first first test would only be a word boundary if it were followed by another word character ( [A-Za-z0-9_] ; in some regex flavors the definition is based on a broader range of characters, including accented English letters and letters from other scripts, but in PHP it’s only ASCII letters and digits).
I suspect what you want to do is make sure the . is either followed by whitespace, or it’s at the end of the string. You can express that directly as a positive lookahead:
. or more succinctly, as a negative lookahead:
. in other words, if there’s a next character, it’s not a non-whitespace character.
How to write Multi-Line Strings in PHP, Geeks For Geeks. Using Heredoc and Nowdoc Syntax: We can use the PHP Heredoc or the PHP Nowdoc syntax to write multiple-line string variables directly. The difference between heredoc and nowdoc is that heredoc uses double-quoted strings. Parsing is done inside a heredoc for escape sequences, etc …
Search and replace all lines in a multiline string
I have a string with a large list with items named as follows:
str = "f05cmdi-test1-name1 f06dmdi-test2-name2";
So the first 4 characters are random characters. And I would like to have an output like this:
'mdi-test1-name1', 'mdi-test2-name2',
As you can see the first characters from the string needs to be replaced with a ‘ and every line needs to end with ‘,
How can I change the above string into the string below? I’ve tried for ours with ‘strstr’ and ‘str_replace’ but I can’t get it working. It would save me a lot of time if I got it work.
EDIT : I deleted the above since the following method is better and more reliable and can be used for any possible combination of four characters.
So what do I do if there are a million different possibillites as starting characters ?
In your specific example I see that the only space is in between the full strings (full string = «f05cmdi-test1-name1» )
str = "f05cmdi-test1-name1 f06dmdi-test2-name2"; $result_array = []; // Split at the spaces $result = explode(" ", $str); foreach($result as $item) < // If four random chars take string after the first four random chars $item = substr($item, 5); $result_array = array_push($result_arrray, $item); >
Can I write PHP code across multiple lines per statement?, So yes, you can separate statements including those with operators into multiple lines. And the answer with the string concatenation — yes there are myriad answers on this forum already about that but I was asking about statements, not strings, which I could not find answered elsewhere. Thanks …
Поиск по нескольким строкам в PHP с функциями preg_match_all и preg_match
При написании регулярных выражений можно столкнуться с проблемой, что когда искомая строка написана в одну линию, то функции PHP её успешно находят, а когда она разбита на несколько строк, то функции PHP, такие как preg_match_all, preg_match и другие для работы с регулярными выражениями, больше не могут её найти.
Дело в том, что нужно помнить про печатные и непечатные символы. Перевод строки — это отдельный символ, который является непечатным (хотя результаты его действия — перевод строки — видны на экране). При этом хотя про символ . (точка) хотя и пишут во многих материалах, что он соответствует любым символам, на самом деле, он соответствует всем символам кроме перевода строк. Поэтому получается, что написанное регулярное выражение, которая совпадает со строкой в одну линию, перестаёт работать для этой же строки разбитой на несколько строк.
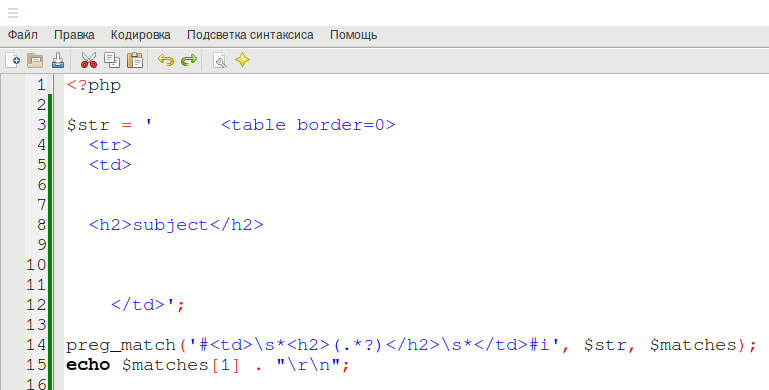
Возьмём к примеру HTML код, из которого мы хотим извлечь данные с помощью регулярного выражения:
Представим ситуацию, что нам нужно извлечь строку subject, которая помещена в заголовке, который помещён в таблице. В приведённом выше примере специально оставлены белые пробелы и переносы строк.
Во-первых, можно воспользоваться опцией s, которая указывается после регулярного выражения. Если использовать данный модификатор, то метасимвол «.» начинает означать «любой символ», в том числе включая перевод строк.
preg_match('#
.*
(.*?)
.*
#s', $str, $matches); // результат помещён в $matches[1]
Во-вторых, можно использовать экранирующую последовательность \s. Сочетание \s означает «любые белые пробелы». Поскольку пробелы могут присутствовать, а могут отсутствовать, то к \s нужно добавить квантор количества * (звёздочка), который означает «ноль или любое количество раз». В таком случае соответствующим регулярным выражением будет:
preg_match('#
\s*
(.*?)
\s*
#i', $str, $matches); // результат помещён в $matches[1]
Two modifiers are involved in php multiline regex expression: m and s. Specifically, the m modifier has influence on the interpretation of the ^ and $ symbols while the s modifier has influence on the dot symbol in the regular expression.
By default, the ^ symbol indicates the beginning of the whole subject string while the $ symbol indicates the end of the whole subject string, even there are newlines(\n) in between the subject string. So,
Since the dot symbol does not match newline by default, we cannot remove the “.com” in “myprogrammingnotes.com”. To match across multiple lines, we can use the following code:
With the s modifier, the php regex matches multiple lines of the subject string. This is true even you use the ungreedy indicator ? because $ only means the end of the while string, not the end of each line.
Now, the “.com” in every line of the subject is matched and deleted because with the m modifier, the ^ and $ mean the beginning and the end of every line, respectively, and we used ungreedy match.