- парсим сайты легко и непринуждённо вместе с phpQuery
- Пример парсинга html-страницы на phpQuery
- Подготовка
- Включение вывода ошибок PHP:
- Локаль:
- Мета-теги
- Заголовок страницы (title)
- Результат:
- Keywords и Description
- Результат:
- Несколько элементов
- Результат:
- Заголовок h1
- Результат:
- Хлебные крошки
- Результат:
- Артикул
- Результат:
- Цены
- Результат:
- Изображения
- Результат:
- Списки dl dd dt
- Результат:
- Списки ul
- Результат:
- Таблицы
- Результат:
- Произвольный контент
- Результат:
- PHP HTML DOM парсер с jQuery подобными селекторами
парсим сайты легко и непринуждённо вместе с phpQuery
Имеется довольно много способов сделать это.
phpQuery::newDocument($html, $contentType = null) Создаём новый документ из разметки. Если не указали $contentType, будет определен основываясь на разметке. Если не получится то будем считать что это, text/html в utf-8.
phpQuery::newDocumentFile($file, $contentType = null) Создаём новый документ из файла. Работает также как и newDocument()
phpQuery::newDocumentHTML($html, $charset = ‘utf-8’)
phpQuery::newDocumentXHTML($html, $charset = ‘utf-8’)
phpQuery::newDocumentXML($html, $charset = ‘utf-8’)
phpQuery::newDocumentPHP($html, $contentType = null) Подробнее можете почитать об этом здесь.
phpQuery::newDocumentFileHTML($file, $charset = ‘utf-8’)
phpQuery::newDocumentFileXHTML($file, $charset = ‘utf-8’)
phpQuery::newDocumentFileXML($file, $charset = ‘utf-8’)
phpQuery::newDocumentFilePHP($file, $contentType) Подробнее можете почитать об этом здесь.
Ну а мы, далеко ходить не будем. Давай %username%, распарсим твои записи в блоге. Сначала скачаем phpQuery. Теперь создаём что то вроде index.php
find('div.hentry'); foreach ($hentry as $el) < $pq = pq($el); // Это аналог $ в jQuery $pq->find('h2.entry-title > a.blog')->attr('href', 'http://%username%.habrahabr.ru/blog/')->html('%username%'); // меняем атрибуты найденого элемента $pq->find('div.entry-info')->remove(); // удаляем ненужный элемент $tags = $pq->find('ul.tags > li > a'); $tags->append(': ')->prepend(' :'); // добавляем двоеточия по бокам $pq->find('div.content')->prepend('
')->prepend($tags); // добавляем контент в начало найденого элемента > echo $hentry; ?> Это всего лишь малая часть того что возможно сделать.
Также вместе с ней поставляется такая штука как jQueryServer. По сути, это тоже самое что и phpQuery, но на стороне клиента.
Пример из демки
Данный вариант довольно практичный и позволяет распарсить контент с нескольких сайтов в несколько секунд, не утруждая себя в написании php кода.
Материалы по теме
Если вам интересно в следующей статье я хочу рассмотреть парсинг сайтов доступных только авторизованным пользователям (без капчи конечна). Да, phpQuery умеет и это, правда не без помощи Zend Framework.
Пример парсинга html-страницы на phpQuery
phpQuery – это удобный HTML парсер взявший за основу селекторы, фильтры и методы jQuery, которые позволяют манипулировать элементами HTML/XML и получать их содержимое.
В примерах используется страница карточки товара https://snipp.ru/demo/76/index.html, все спарсенные данные помещаются в общий массив $data .
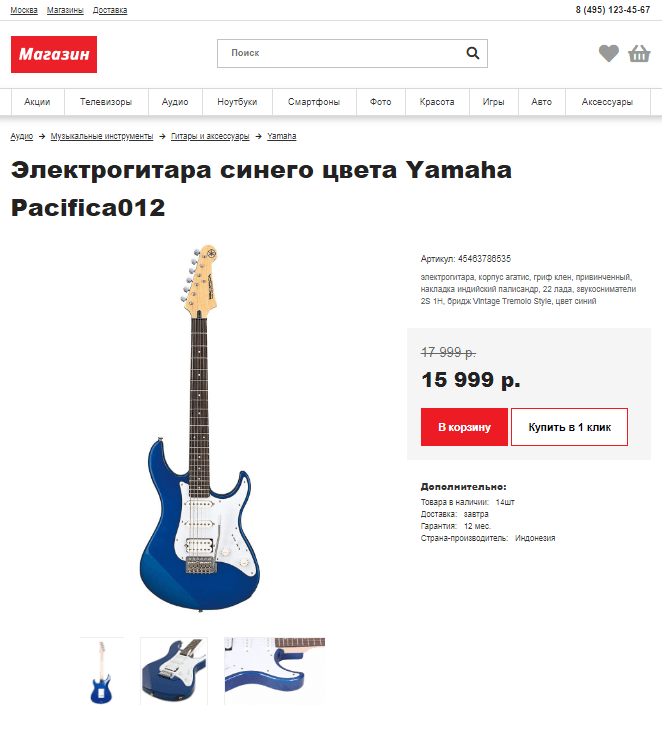
Подготовка
Включение вывода ошибок PHP:
error_reporting(E_ALL); ini_set('display_errors', 1);Локаль:
setlocale(LC_ALL, 'ru_RU'); date_default_timezone_set('Europe/Moscow'); header('Content-type: text/html; charset=utf-8');include_once __DIR__ . '/phpQuery.php'; $doc = phpQuery::newDocument(file_get_contents('https://snipp.ru/demo/76/index.html'));Если кодировка сайта-донора отличается от вашей, возможно в спарсенных данных кириллица будет иероглифами. В таком случаи потребуется перекодировка, например:
$html = file_get_contents('https://snipp.ru/demo/76/index.html'); $html = iconv('utf-8//IGNORE', 'windows-1251//IGNORE', $html); include_once __DIR__ . '/phpQuery.php'; $doc = phpQuery::newDocument($html);Подробнее в статье «Перекодировка текста UTF-8 и WINDOWS-1251». Ещё бывают случаи, когда file_get_contents возвращает полученный контент сжатый в GZIP, например: �mw�Ƒ0�����&IkAI��f��j4/
function getcontents($url) < $ch = curl_init(); curl_setopt($ch, CURLOPT_URL, $url); curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1); curl_setopt($ch, CURLOPT_ENCODING, 'gzip'); curl_setopt($ch, CURLOPT_SSL_VERIFYHOST, 0); curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, 0); $output = curl_exec($ch); curl_close($ch); return $output; >include_once __DIR__ . '/phpQuery.php'; $doc = phpQuery::newDocument(getcontents('https://snipp.ru/demo/76/index.html'));Мета-теги

Заголовок страницы (title)
Метод find(‘selector’) находит элементы по селектору, далее вызывается функция pq() , которая возвращает объект найденного элемента (подобно $ в jquery). К этому объекту можно применить методы, например text() – получить текстовое содержимое элемента.
$entry = $doc->find('title'); $data['title'] = pq($entry)->text(); echo $data['title'];Результат:
Пример магазина - Электрогитара синего цвета Yamaha Pacifica012Keywords и Description
$entry = $doc->find('head meta[name="keywords"]'); $data['keywords'] = pq($entry)->attr('content'); echo $data['keywords']; $entry = $doc->find('head meta[name="description"]'); $data['description'] = pq($entry)->attr('content'); echo $data['description'];Результат:
Электрогитара,Yamaha,Pacifica012 Интернет-магазин цифровой и бытовой техникиНесколько элементов
$data['css'] = array(); $entry = $doc->find('head link[rel="stylesheet"]'); foreach ($entry as $row) < $data['css'][] = pq($row)->attr('href'); > print_r($data['css']);Результат:
Array ( [0] => style.css [1] => https://snipp.ru/cdn/fontawesome/5.11.2/css/all.css )Заголовок h1

$entry = $doc->find('h1'); $data['h1'] = pq($entry)->text(); echo $data['h1'];Результат:
Электрогитара синего цвета Yamaha Pacifica012Хлебные крошки

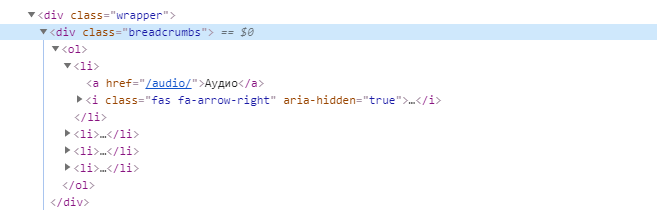
$data['breadcrumbs'] = array(); $entry = $doc->find('.breadcrumbs li a'); foreach ($entry as $row) < $ent = pq($row); $name = $ent->text(); $url = $ent->attr('href'); $data['breadcrumbs'][$name] = $url; > print_r($data['breadcrumbs']);Результат:
Array ( [Аудио] => /audio/ [Музыкальные инструменты] => /audio/instruments/ [Гитары и аксессуары] => /audio/instruments/guitar/ [Yamaha] => /audio/instruments/guitar/yamaha )Артикул


В данном случаи нужно только значение, c помощью метода remove() удаляется элемент с текстом «Артикул».
$entry = $doc->find('.prod .prod-sku'); $entry->find('span')->remove(); $data['sku'] = trim(pq($entry)->text()); echo $data['sku'];Результат:
Цены
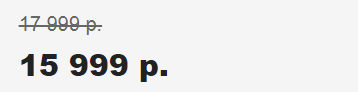

Цены выводятся с форматированием, его можно удалить регулярным выражением и привести значение к типу float или сразу применить PHP-функцию clean_price().
/* Старая цена - strike */ $entry = $doc->find('.price-price strike'); $val = pq($entry)->text(); $data['price_old'] = floatval(mb_ereg_replace('[^0-9.,]', '', $val)); var_dump($data['price_old']); /* Старая цена - span */ $entry = $doc->find('.price-price span'); $val = pq($entry)->text(); $data['price'] = floatval(mb_ereg_replace('[^0-9.,]', '', $val)); var_dump($data['price']);Результат:
Изображения
Для оптимизации скорости, фото товаров в тегах уменьшают и оборачивают их ссылками на оригинальные изображения.

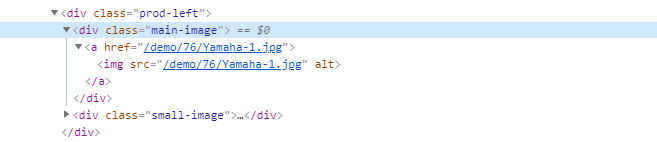
$data['images'] = array(); $entry = $doc->find('.prod-left img'); foreach ($entry as $row) < $link = pq($row)->parents('a'); $data['images'][] = pq($link)->attr('href'); > print_r($data['images']);Результат:
Array ( [0] => /demo/76/Yamaha-1.jpg [1] => /demo/76/Yamaha-2.jpg [2] => /demo/76/Yamaha-3.jpg [3] => /demo/76/Yamaha-4.jpg )Списки dl dd dt

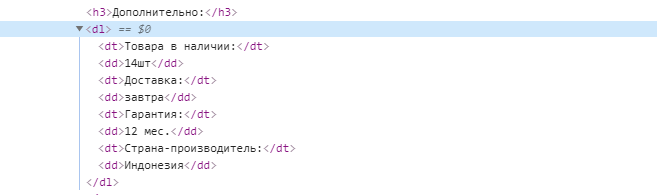
Сложность парсинга списков определений заключается в том, что у нескольких
/* dt */ $dt = array(); $entry = $doc->find('dl dt'); foreach ($entry as $row) < $dt[] = trim(pq($row)->text(), ':'); > /* dl */ $dd = array(); $entry = $doc->find('dl dd'); foreach ($entry as $row) < $dd[] = pq($row)->text(); > $data['attrs'] = array_combine($dt, $dd); print_r($data['attrs']);Результат:
Array ( [Товара в наличии] => 14шт [Доставка] => завтра [Гарантия] => 12 мес. [Страна-производитель] => Индонезия )Списки ul

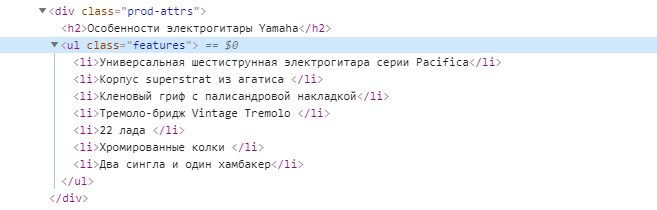
$data['list'] = array(); $entry = $doc->find('ul.features li'); foreach ($entry as $row) < $data['list'][] = pq($row)->text(); > print_r($data['list']);Результат:
Array ( [0] => Универсальная шестиструнная электрогитара серии Pacifica [1] => Корпус superstrat из агатиса [2] => Кленовый гриф с палисандровой накладкой [3] => Тремоло-бридж Vintage Tremolo [4] => 22 лада [5] => Хромированные колки [6] => Два сингла и один хамбакер )Таблицы
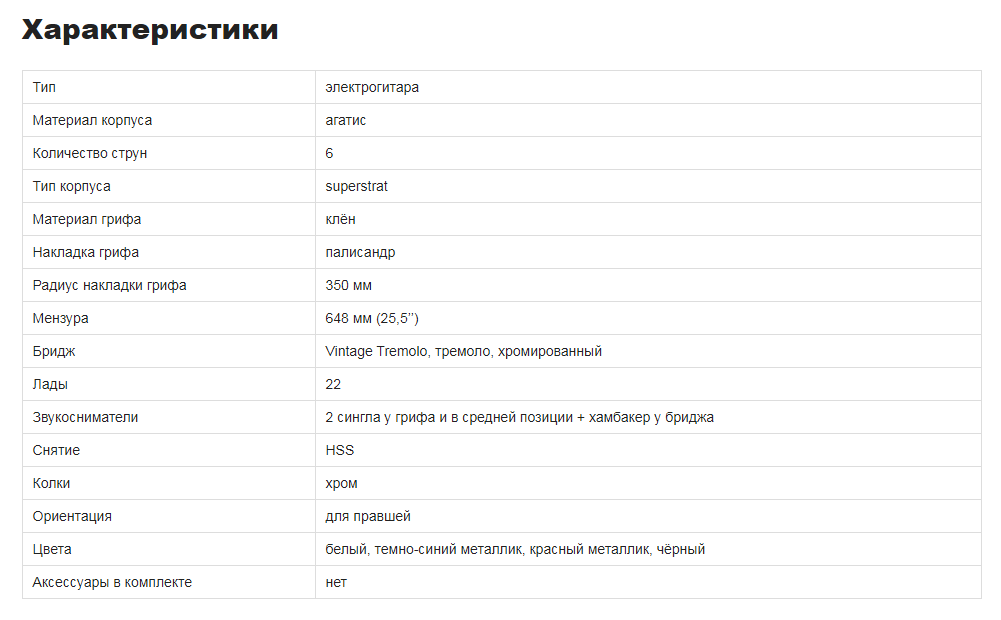
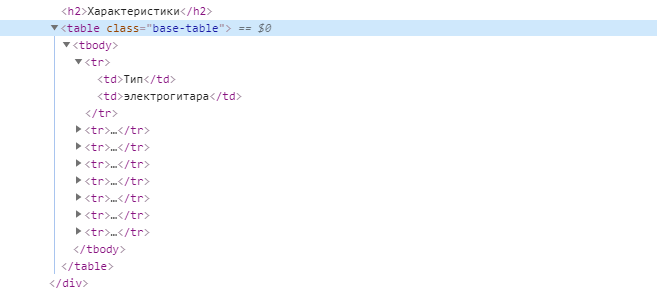
Найдем все
$data['table'] = array(); $entry = $doc->find('table.base-table tr'); foreach ($entry as $row) < $row = pq($row); $name = $row->find('td:eq(0)')->text(); $value = $row->find('td:eq(1)')->text(); $data['table'][$name] = $value; > print_r($data['table']);Результат:
Array ( [Тип] => электрогитара [Материал корпуса] => агатис [Количество струн] => 6 [Тип корпуса] => superstrat [Материал грифа] => клён [Накладка грифа] => палисандр [Радиус накладки грифа] => 350 мм [Мензура] => 648 мм (25,5’’) [Бридж] => Vintage Tremolo, тремоло, хромированный [Лады] => 22 [Звукосниматели] => 2 сингла у грифа и в средней позиции + хамбакер у бриджа [Снятие] => HSS [Колки] => хром [Ориентация] => для правшей [Цвета] => белый, темно-синий металлик, красный металлик, чёрный [Аксессуары в комплекте] => нет )Произвольный контент


Найдем
$entry = $doc->find('div.text'); $entry->find('h2')->remove(); $data['text'] = pq($entry)->html(); echo $data['text'];Результат:
Разработанная на основе модели Pacifica 112, новая, еще более доступная по цене модель 012 характеризуется аналогичными контурами корпуса, мощным хамбакером в бриджевой позиции и 2 синглами, обеспечивающими чистое звучание. Гитара оснащена удобным грифом, 5-позиционным переключателем выбора звукоснимателей и тремоло типа Vintage.
Корпус: агатис. Гриф: привинченный, клен. Накладка грифа: сонокелинг, радиус 350 мм. Лады: 22. Мензура: 648 мм. Звукосниматель: 2 сингла, 1 хамбакер. Регуляторы: 5-позиционный переключатель звукоснимателей, мастер-громкость, тембр. Бридж: тремоло типа Vintage.
PHP HTML DOM парсер с jQuery подобными селекторами
Добрый день, уважаемые хабровчане. В данном посте речь пойдет о совместном проекте S. C. Chen и John Schlick под названием PHP Simple HTML DOM Parser (ссылки на sourceforge).
Идея проекта — создать инструмент позволяющий работать с html кодом используя jQuery подобные селекторы. Оригинальная идея принадлежит Jose Solorzano’s и реализована для php четвертой версии. Данный же проект является более усовершенствованной версией базирующейся на php5+.
В обзоре будут представлены краткие выдержки из официального мануала, а также пример реализации парсера для twitter. Справедливости ради, следует указать, что похожий пост уже присутствует на habrahabr, но на мой взгляд, содержит слишком малое количество информации. Кого заинтересовала данная тема, добро пожаловать под кат.
Получение html кода страницы
$html = file_get_html('http://habrahabr.ru/'); //работает и с https:// Товарищ Fedcomp дал полезный комментарий насчет file_get_contents и 404 ответа. Оригинальный скрипт при запросе к 404 странице не возвращает ничего. Чтобы исправить ситуацию, я добавил проверку на get_headers. Доработанный скрипт можно взять тут.
Поиск элемента по имени тега
foreach($html->find('img') as $element) < //выборка всех тегов img на странице echo $element->src . '
'; // построчный вывод содержания всех найденных атрибутов src > Модификация html элементов
$html = str_get_html('HelloWorld'); // читаем html код из строки (file_get_html() - из файла) $html->find('div', 1)->class = 'bar'; // присвоить элементу div с порядковым номером 1 класс "bar" $html->find('div[id=hello]', 0)->innertext = 'foo'; // записать в элемент div с текст foo echo $html; // выведет fooWorld Получение текстового содержания элемента (plaintext)
echo file_get_html('http://habrahabr.ru/')->plaintext; Целью статьи не является предоставить исчерпывающую документацию по данному скрипту, подробное описание всех возможностей вы можете найти в официальном мануале, если у сообщества возникнет желание, я с удовольствием переведу весь мануал на русский язык, пока же приведу обещанный в начале статьи пример парсера для twitter.
Пример парсера сообщений из twitter
require_once 'simple_html_dom.php'; // библиотека для парсинга $username = 'habrahabr'; // Имя в twitter $maxpost = '5'; // к-во постов $html = file_get_html('https://twitter.com/' . $username); $i = '0'; foreach ($html->find('li.expanding-stream-item') as $article) < //выбираем все li сообщений $item['text'] = $article->find('p.js-tweet-text', 0)->innertext; // парсим текст сообщения в html формате $item['time'] = $article->find('small.time', 0)->innertext; // парсим время в html формате $articles[] = $item; // пишем в массив $i++; if ($i == $maxpost) break; // прерывание цикла > Вывод сообщений
for ($j = 0; $j < $maxpost; $j++) < echo ''; echo '' . $articles[$j]['text'] . '
'; echo '' . $articles[$j]['time'] . '
'; echo ''; > Благодарю за внимание. Надеюсь, получилось не очень тяжеловесно и легко для восприятия.
Похожие библиотеки
P.S.
Хаброжитель Groove подсказал что подобные материалы уже были
P.P.S.
Постараюсь в свободное время собрать все библиотеки и составить сводные данные по производительности и приятности использования.