Практическое руководство. написание простого цикла Parallel.ForEach
В этой статье показано, как использовать Parallel.ForEach цикл для включения параллелизма данных в любом System.Collections.IEnumerable источнике данных или System.Collections.Generic.IEnumerable .
В этой документации для определения делегатов в PLINQ используются лямбда-выражения. Если вы не знакомы с лямбда-выражениями в C# или Visual Basic, см. статью Лямбда-выражения в PLINQ и TPL.
Пример
В этом примере показаны Parallel.ForEach операции с ресурсоемким ЦП. При выполнении примера он случайным образом создает 2 миллиона чисел и пытается выполнить фильтрацию по простым числам. Первый случай выполняет итерацию по коллекции с помощью for цикла . Во втором случае выполняется итерацию по коллекции с помощью Parallel.ForEach. Результирующее время, затраченное на каждую итерацию, отображается после завершения работы приложения.
using System; using System.Collections.Concurrent; using System.Collections.Generic; using System.Diagnostics; using System.Linq; using System.Threading.Tasks; namespace ParallelExample < class Program < static void Main() < // 2 million var limit = 2_000_000; var numbers = Enumerable.Range(0, limit).ToList(); var watch = Stopwatch.StartNew(); var primeNumbersFromForeach = GetPrimeList(numbers); watch.Stop(); var watchForParallel = Stopwatch.StartNew(); var primeNumbersFromParallelForeach = GetPrimeListWithParallel(numbers); watchForParallel.Stop(); Console.WriteLine($"Classical foreach loop | Total prime numbers : | Time Taken : ms."); Console.WriteLine($"Parallel.ForEach loop | Total prime numbers : | Time Taken : ms."); Console.WriteLine("Press any key to exit."); Console.ReadLine(); > /// /// GetPrimeList returns Prime numbers by using sequential ForEach /// /// /// private static IList GetPrimeList(IList numbers) => numbers.Where(IsPrime).ToList(); /// /// GetPrimeListWithParallel returns Prime numbers by using Parallel.ForEach /// /// /// private static IList GetPrimeListWithParallel(IList numbers) < var primeNumbers = new ConcurrentBag(); Parallel.ForEach(numbers, number => < if (IsPrime(number)) < primeNumbers.Add(number); >>); return primeNumbers.ToList(); > /// /// IsPrime returns true if number is Prime, else false.(https://en.wikipedia.org/wiki/Prime_number) /// /// /// private static bool IsPrime(int number) < if (number < 2) < return false; >for (var divisor = 2; divisor > return true; > > > Imports System.Collections.Concurrent Namespace ParallelExample Class Program Shared Sub Main() ' 2 million Dim limit = 2_000_000 Dim numbers = Enumerable.Range(0, limit).ToList() Dim watch = Stopwatch.StartNew() Dim primeNumbersFromForeach = GetPrimeList(numbers) watch.Stop() Dim watchForParallel = Stopwatch.StartNew() Dim primeNumbersFromParallelForeach = GetPrimeListWithParallel(numbers) watchForParallel.Stop() Console.WriteLine($"Classical foreach loop | Total prime numbers : | Time Taken : ms.") Console.WriteLine($"Parallel.ForEach loop | Total prime numbers : | Time Taken : ms.") Console.WriteLine("Press any key to exit.") Console.ReadLine() End Sub ' GetPrimeList returns Prime numbers by using sequential ForEach Private Shared Function GetPrimeList(numbers As IList(Of Integer)) As IList(Of Integer) Return numbers.Where(AddressOf IsPrime).ToList() End Function ' GetPrimeListWithParallel returns Prime numbers by using Parallel.ForEach Private Shared Function GetPrimeListWithParallel(numbers As IList(Of Integer)) As IList(Of Integer) Dim primeNumbers = New ConcurrentBag(Of Integer)() Parallel.ForEach(numbers, Sub(number) If IsPrime(number) Then primeNumbers.Add(number) End If End Sub) Return primeNumbers.ToList() End Function ' IsPrime returns true if number is Prime, else false.(https://en.wikipedia.org/wiki/Prime_number) Private Shared Function IsPrime(number As Integer) As Boolean If number < 2 Then Return False End If For divisor = 2 To Math.Sqrt(number) If number Mod divisor = 0 Then Return False End If Next Return True End Function End Class End Namespace Цикл Parallel.ForEach действует как цикл Parallel.For. Цикл разделяет исходную коллекцию на секции и распределяет задачи по нескольким потокам с учетом доступной среды системы. Чем больше в системе процессоров, тем быстрее выполняются параллельные методы. Для некоторых исходных коллекций последовательный цикл может выполняться быстрее в зависимости от размера источника и типа работы, выполняемой циклом. Дополнительные сведения о производительности см. в статье Потенциальные ошибки, связанные с параллелизмом данных и задач.
Чтобы использовать Parallel.ForEach цикл с неуниверсационной коллекцией, можно использовать Enumerable.Cast метод расширения для преобразования коллекции в универсальную коллекцию, как показано в следующем примере:
Parallel.ForEach(nonGenericCollection.Cast(), currentElement => < >); Parallel.ForEach(nonGenericCollection.Cast(Of Object), _ Sub(currentElement) ' . work with currentElement End Sub) Скомпилируйте и запустите код.
Код можно скомпилировать как консольное приложение для .NET Framework или .NET Core.
В Visual Studio существуют шаблоны консольных приложений Visual Basic и C# для Windows Desktop и .NET Core.
В командной строке можно использовать команды .NET CLI (например, dotnet new console или dotnet new console -lang vb ) или создать файл и использовать компилятор командной строки для платформа .NET Framework приложения.
Чтобы запустить консольное приложение .NET Core из командной строки, используйте dotnet run в папке, которая содержит ваше приложение.
Чтобы запустить консольное приложение из Visual Studio, нажмите клавишу F5 .
См. также
1. Введение в параллельное программирование
Приступая к изучению основ параллельного программирования, необходимо прежде всего четко понять, в чем же заключается принципиальное отличие программы параллельной от программы последовательной. С этой целью рассмотрим один простейший пример.
Пусть перед нами стоит задача вычисления следующей суммы:

. (1)
Очевидно, что решение этой задачи на обычном однопроцессорном персональном компьютере не представляет никакой сложности и соответствующая программа на языке С имеет следующий вид:
int main(int argc, char **argv)
int S=0; /* искомая сумма */
int k; /* переменная цикла */
/* печать результата на экран */
/* нормальное завершение работы программы */
Теперь предположим, что в нашем распоряжении имеется многопроцессорная вычислительная система (МВС), содержащая 32 процессора. Зададимся вопросом: каким образом можно осуществить вычисление суммы (1) на этой системе так, чтобы были задействованы все 32 процессора? При этом естественно ожидать, что время вычисления на МВС должно быть существенно меньше, чем на обычном персональном компьютере * ) . Очевидно, что выигрыш во времени вычислений будет получен лишь в том случае, когда процессоры МВС будут работать одновременно, или параллельно. Но для этого каждый процессор должен выполнять свой набор операций, не зависящих от операций, выполняющихся на других процессорах системы. Отсюда естественным образом возникает задача, получившая в практике параллельного программирования название задачи декомпозиции и заключающаяся в разделении исходной задачи на ряд автономных, т.е. независимых друг от друга, подзадач. Решение каждой подзадачи осуществляется на отдельном процессоре МВС.
Для рассматриваемой нами задачи (1) можно легко выделить 32 независимые подзадачи: очевидно, что это возведение в куб первых 32 натуральных чисел:
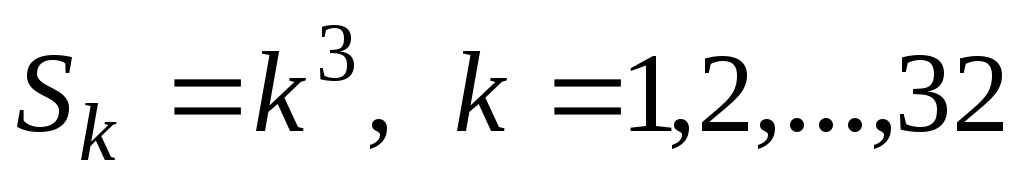
. (2)
Таким образом, мы можем поручить каждому из имеющихся в нашем распоряжении процессоров решение одной из задач (2). Для получения окончательного ответа нам необходимо просуммировать результаты, полученные на отдельных процессорах. Эту операцию будем выполнять на одном процессоре.
Какие же дополнительные функции нам потребуются, чтобы адаптировать рассмотренную выше программу для МВС? Прежде всего, это функции, позволяющие передавать данные от одного процессора к другому. Введем две такие гипотетические функции: Send и Recv. Применительно к рассматриваемой нами задаче эти функции могут иметь следующие прототипы:
void Send(int sbuf, int dest);
void Recv(int rbuf, int source);
Первая функция (Send) осуществляет передачу данных типа int, связанных с идентификатором sbuf на текущем процессоре, процессору с номером dest. Вторая функция (Recv) принимает данные типа int от процессора с номером source и связывает их с идентификатором rbuf на текущем процессоре. При этом под текущим понимается процессор, вызвавший ту или другую функцию.
При выполнении параллельной программы на МВС необходимо также знать порядковый номер каждого процессора и общее количество процессоров, которые задействованы в решении задачи. Именно через порядковый номер обычно происходит распределение подзадач по процессорам. Нумерация процессоров традиционно начинается с 0. Поэтому помимо уже введенных функций нам потребуются еще две функции:
void Rank(int MyID);
void Size(int NumProc);
Функция Rank(MyID) записывает в MyID номер текущего процессора, а функция Size(NumProc) возвращает в NumProc общее количество активных процессоров.
Теперь с помощью введенных функций мы можем написать параллельную программу для решения задачи (1):
int main(int argc, char **argv)
int S=0; /* искомая сумма */
int k; /* переменная цикла */
int SAdd; /* вспомогательная переменная */
int NumProc; /* количество процессоров */
int MyID; /* номер процессора */
/* определение количества
/* определение номера текущего процессора */
/* вычисление куба числа
/* передача результатов со всех процессоров
на процессор с номером 0 и вычисление на
этом процессоре окончательной суммы */
/*печать результата на экран */
/* нормальное завершение работы программы */
Каким же образом будет выполняться данная параллельная программа на МВС? Сразу необходимо понять следующее: в принятой нами модели параллельного программирования (забегая чуть вперед отметим, что именно такая модель лежит в основе MPI) весь программный код выполняется каждым процессором, но со своим набором данных. Другим словами, каждый процессор имеет свою копию программы, которую он и выполняет. Такая технология параллельного программирования носит название технологии разделения по данным. Так, в нашем случае после операции возведения в куб в переменной S на разных процессорах будут храниться разные числа: скажем, на втором процессоре это будет 27, а на девятом – 1000 (напомним, что процессоры нумеруются с 0!). Номер процессора хранится в переменной MyID.
Обратим также внимание на следующий весьма важный момент: если в параллельной программе необходимо выделить участок кода, который должен выполняться не всеми процессорами, а их частью или вообще одним процессором, то для этого используются условные операторы (структуры выбора языка С), в логические условия которых обязательно входит идентификатор номера процессора (в нашем случае MyID). Так, в приведенном примере функция Send будет вызвана всеми процессорами, кроме нулевого, а функция Recv, наоборот, будет вызвана только нулевым процессором, но 31 раз.
Далее отметим, что реализованный в нашей параллельной программе вычислительный алгоритм несколько отличается от алгоритма, по которому написана последовательная программа. А именно: в параллельной программе появилась дополнительная операция сложения – увеличение на единицу номера процессора. Поэтому количество вычислительных операций в последовательной и параллельной программе несколько различаются. Такая ситуация является достаточно типичной: при распараллеливании практически никогда не удается сохранить количество операций исходного последовательного алгоритма – в параллельном алгоритме оно всегда оказывается несколько больше.
В приведенном примере вывод результатов на экран осуществляет только нулевой процессор. Следует отметить, что стандарт MPI не оговаривает правила ввода-вывода и ряд его реализаций (в том числе и MPICH) допускают ввод и вывод данных через любой процессоор. Однако существуют реализации MPI не поддерживающие этот режим. Поэтому в данном пособии мы будем придерживаться следующего правила: ввод-вывод данных и весь диалог с пользователем в параллельной программе осуществляется только через нулевой процессор.
Подводя общий итог отметим, что для написания простейшей параллельной программы нам потребовалось ввести всего четыре гипотетические функции межпроцессорного обмена данными. Теоретически этих функций достаточно для написания любой параллельной программы. Тем не менее библиотека MPI содержит более 120 функций. Нетрудно догадаться, что такое многообразие обусловлено необходимостью создавать не просто параллельные программы, а эффективные параллельные программы. Поэтому прежде чем перейти к изучению самой библиотеки MPI остановимся кратко на вопросах оценки эффективности параллельных программ и факторах, влияющих на эту эффективность.