- HTML Character Sets
- Example
- HTML Character Sets
- In the Beginning: ASCII
- In Windows: Windows-1252
- In HTML 4: ISO-8859-1
- Example
- Example
- Example
- In HTML5: Unicode UTF-8
- Example
- Example
- UTF-8 in HTML
- How does UTF-8 Works in HTML?
- Key Importance to Use UTF-8
- Examples of UTF-8 in HTML
- Example #1
- Example #2
- Example #3
- Example #4
- Conclusion
- Recommended Articles
- How do I set character encoding to UTF-8 for default.html?
- Displaying unicode symbols in HTML
- 5 Answers 5
HTML Character Sets
To display an HTML page correctly, the browser must know what character set (encoding) to use:
Example
HTML Character Sets
The HTML5 specification encourages web developers to use the UTF-8 character set!
This has not always been the case. The character encoding for the early web was ASCII.
Later, from HTML 2.0 to HTML 4.01, ISO-8859-1 was considered as the standard character set.
With XML and HTML5, UTF-8 finally arrived and solved a lot of character encoding problems.
In the Beginning: ASCII
Computer data is stored as binary codes (01000101) in the electronics.
To standardize the storing of text, the American Standard Code for Information Interchange (ASCII) was created. It defined a unique binary number for each storable character to support the numbers from 0-9, the upper and lower case alphabet (a-z, A-Z), and special characters like ! $ + — ( ) @ < >, .
Since ASCII used 7 bits for the character, it could only represent 128 different characters.
The biggest weakness with ASCII, was that it excluded non English letters.
ASCII is still in use today, especially in large mainframe computer systems.
For a closer look, please study our Complete ASCII Reference.
In Windows: Windows-1252
Windows-1252 was the default character set in Windows, up to Windows 95.
It is an extension to ASCII, with added international characters.
It uses a full byte (8-bits) to represent 256 different characters.
Since Windows-1252 has been the default in Windows, it is supported by all browsers.
In HTML 4: ISO-8859-1
The character set most often used in HTML 4 was ISO-8859-1.
ISO-8859-1 is an extension to ASCII, with added international characters.
Example
In HTML 4, a character set different from ISO-8859-1 can be specified in the tag:
Example
All HTML 4 processors also support UTF-8:
Example
When a browser detects ISO-8859-1 it normally defaults to Windows-1252, because Windows-1252 has 32 more international characters.
In HTML5: Unicode UTF-8
The HTML5 specification encourages web developers to use the UTF-8 character set.
Example
A character-set different from UTF-8 can be specified in the tag:
Example
The Unicode Consortium developed the UTF-8 and UTF-16 standards, because the ISO-8859 character-sets are limited, and not compatible a multilingual environment.
The Unicode Standard covers (almost) all the characters, punctuations, and symbols in the world.
All HTML5 and XML processors support UTF-8, UTF-16, Windows-1252, and ISO-8859.
UTF-8 in HTML

UTF-8 is defined as the default character encoding for HTML5 used to display an HTML page perfectly. It encourages web developers to use UTF-8 as it covers all the characters and symbols in the entity that uses one byte and works well in all the browsers. Unicode Transformation Format – 8 bits are a method converts typed character into machine-readable code. The charset attribute is used to perform a character encoding for the HTML.
Web development, programming languages, Software testing & others
Syntax of UTF-8 in HTML
Specification of UTF-8 Character encoding in the tag is given as:
Here meta gives data about the HTML document but is machine-readable. And their elements specify a keyword, last modified etc. This meta tag contains the charset, which tells the web browser while accessing the page.
Encoding is how the given numbers are converted to binary numbers, which a machine understood. Here each character is made up of one or more bytes respectively.
How does UTF-8 Works in HTML?
- The most popular encoding character is ASCII; as the internet grew up globally, the only supported Latin is not efficient; that’s why an industry moved on to Unicode as the best option. UTF-8 is the encoding for Unicode, which assigns a unique value called code point for all the characters and emojis. This encoding system solves the issue in ASCII space and is considered to be a dominant encoding for the W3C. And recommended that all e-mail messages could be created using UTF-8. This checks if the page explicitly declares as UTF-8 using a meta tag at the beginning of the document. The significant bit of UTF-8 is defined as 8,16, 24 or 32 bits as they are encoded as one to four bytes. UTF-8 is considered to be a global standard for existing applications as it understands more applications. This encoding helps to encode text and transfer data. UTF-8 encoding s most preferable on most websites. This standard covers all characters, symbols, punctuation all over the world.
- UTF-8 treats a range 0-127 as ASCII code and later up to 192 as shift keys. And the next characters, 224-239, has to be double shifted. Therefore, it is termed multi-byte variable encoding.
- Unicode assigns unique code to every character in a human language. The character set (Grouping all available characters into a specific set) could be overridden using the lang attribute. This Unicode translates into a Binary and vice-versa. It prevents unexpected results during form submission applications. UTF-8 should be considered when we find web pages are lagging inordinate amount of space. Storing UTF-8 text into a binary meanwhile char becomes binary, varchar shows to VARBINARY in SQL.
As an example, let’s take the text Hi, EDUCBA!
The UTF-8-character Encoding is given as below:
01001000 01101001 00101100 01100101 01000100 01010101 01000011 01000010 01000001 00100001
Which converts into a machine-readable binary structure.
Key Importance to Use UTF-8
- It is deliberately compatible with encoding standard ASCII.
- This preferred HTML encoding uses less space and supports many languages.
- This benefits the SEO. Suppose you use two standards, then it leads to a decoding issue that wrongly impacts the SEO. It means we need to implement the character correctly to Help SEO efforts.
Next, we shall see how the Unicode representation is important while taking up foreign languages in the content.
Examples of UTF-8 in HTML
Given below are the examples of UTF-8 in HTML:
Example #1
Simple example with the paragraph content.
body !مرحبا بالعالم
你叫什么名字? This is Chinese Language.
This is the code demonstrating encoding Process
Explanation:
- The screenshot below shows the content displayed in the Chinese language as well as in English. This is because when the above HTML code is executed in a modern Browser, it normally refers to Unicode.

Example #2
Using Buttons for the input text.
Explanation:
- The screenshot below shows the input content displayed in the Chinese language as well as in English. This is because when the above HTML code is executed in a modern Browser, it normally refers to Unicode.
Example #3
Code using foreign-language content.
Hi Instructor!
This is my formal e-mail for the joining.
Hola, me llamo Juan
Mucho gusto Explanation:

Example #4
span < color: blue; >span.name Thomas, John Betson, Valli Tromson आभरणा, आचुथान, अभिनंध Explanation:
- The above code uses functions to class the respective class. Before that, we have declared metadata for the encoding process. Here we have assigned an element with another language. Unfortunately, ASCII doesn’t have compatibility to access. Therefore, we have declared UTF-8 to support the type.
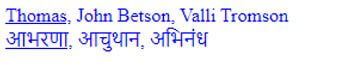
Conclusion
So that’s all about the encoding of UTF-8 in HTML. We have gone through Unicode and encodes in the HTML briefly and the implementation of HTML and JavaScript. In this emerging software world, the character sets are not made so feasible; therefore, there comes character encoding schemes to be done with the HTML and other programming languages. Therefore, it is said that it is best to use UTF-8 everywhere where it doesn’t need any conversions encoding.
Recommended Articles
This is a guide to UTF-8 in HTML. Here we discuss the introduction, working, key importance to use UTF-8 and examples, respectively. You may also have a look at the following articles to learn more –
89+ Hours of HD Videos
13 Courses
3 Mock Tests & Quizzes
Verifiable Certificate of Completion
Lifetime Access
4.5
97+ Hours of HD Videos
15 Courses
12 Mock Tests & Quizzes
Verifiable Certificate of Completion
Lifetime Access
4.5
HTML & CSS Course Bundle — 33 Courses in 1 | 9 Mock Tests
125+ Hours of HD Videos
33 Courses
9 Mock Tests & Quizzes
Verifiable Certificate of Completion
Lifetime Access
4.5
How do I set character encoding to UTF-8 for default.html?
I spent the last few hours getting my website to validate HTML 4.01 Strict and I actually have succeeded in that, but there is still one warning which I can’t get rid of. The warning is:
Character Encoding mismatch! The character encoding specified in the HTTP header (iso-8859-1) is different from the value in the element (utf-8). I will use the value from the HTTP header (iso-8859-1) for this validation.
The page in question is www.dubiousarray.net/default.html. As you can see from the page source I have the following meta element:
and I have made sure that the default.html file is saved with UTF-8 encoding. The strange thing is all the other pages in the site validate without this warning and they have the same meta tag and were saved in exactly the same way. I am pretty sure it is something to do with the server configuration. The .htaccess file looks like this at the moment:
# Use PHP 5 as default AddHandler application/x-httpd-php5 .php AddDefaultCharset UTF-8 But I have tried all the fixes shown on this page and none of them worked. How can I go about getting rid of this warning? In Firefox, if you right click on the page and select ‘View Page Info’, default.html shows as ISO-8859-1, while all the other pages show UTF-8. All the html file have been created and saved in the exact same way (character encoding set to UTF-8 without BOM), but default.html is the only one which isn’t displaying as UTF-8. So I assume the server is doing something special to the default.html file though I am not sure what as there is not sign of it in the .htaccess file.
Displaying unicode symbols in HTML
I want to simply display the tick (✔) and cross (✘) symbols in a HTML page but it shows up as either a box or goop ✔ — obviously something to do with the encoding. I have set the meta tag to show utf-8 but obviously I’m missing something.
Edit/Solution: From comments made, using FireBug I found the headers being passed by my page were in fact «Content-Type: text/html» and not UTF-8. Looking at the file format using Notepad++ showed my file was formatted as «UTF-8 without BOM». Changing this to just UTF-8 the symbols now show correctly. but firebug still seems to indicate the same content-type.
5 Answers 5
You should ensure the HTTP server headers are correct.
Content-Type: text/html; charset=utf-8 The meta tag is ignored by browsers if the HTTP header is present.
Also ensure that your file is actually encoded as UTF-8 before serving it, check/try the following:
- Ensure your editor save it as UTF-8.
- Ensure your FTP or any file transfer program does not mess with the file.
- Try with HTML encoded entities, like &#uuu; .
- To be really sure, hexdump the file and look as the character, for the ✔, it should be E2 9C 94 .
Note: If you use an unicode character for which your system can’t find a glyph (no font with that character), your browser should display a question mark or some block like symbol. But if you see multiple roman characters like you do, this denotes an encoding problem.
Actually, the meta tag is not ignored, but the HTTP header takes precedence. Thanks Konrad for that precision.
Note that to use a unicode character in the content property of a CSS ::before selector, one would need to use the backslash notation. e.g.: ‘\2713’ instead of ‘ઙ’.
I know an answer has already been accepted, but wanted to point a few things out.
Setting the content-type and charset is obviously a good practice, doing it on the server is much better, because it ensures consistency across your application.
However, I would use UTF-8 only when the language of my application uses a lot of characters that are available only in the UTF-8 charset. If you want to show a unicode character or symbol in one of cases, you can do so without changing the charset of your page.
HTML renderers have always been able to display symbols which are not part of the encoding character set of the page, as long as you mention the symbol in its numeric character reference (NCR) . Sounds weird but its true.
So, even if your html has a header that states it has an encoding of ansi or any of the iso charsets, you can display a check mark by using its html character reference, in decimal — ✓ or in hex — ✓