Приветствую коллеги. Данная статья является третьей и последней статьей в серии статей о веб-компонентах.Первые две статьи доступны по ссылкам:
В данной статье речь пойдет о элементе а также об HTML импортах.
HTML Templates элемент
Элемент представляет собой инструмент, позволяющий хранить контент на стороне клиента без его рендеринга на страницу, однако с возможностью его отображения в процессе исполнения посредством JavaScript.
Содержимое элемента при парсинге страницы обрабатывается исключительно в части валидации содержимого, но без его рендеринга (согласно спецификации, при рендеринге этот элемент ничего не представляет). Содержимое элемента можно клонировать и вставлять в документ из скриптов, что и используется как самостоятельно для шаблонизации так и при создании веб-компонентов.
Содержимое
К содержимому , как и к любому узлу, не имеющему браузерного контекста, не применимы никакие требования соответствия, кроме требований к правильности HTML и XML синтаксиса. Это означает, что в содержимом шаблона можно, например, указать элемент img не указав значение атрибутов src и alt, таким образом:
однако, вне элемента такой синтаксис валидным не является. При этом пропуск закрывающего тега
был бы нарушением HTML синтаксиса и не является допустимым для содержимого .
Все элементы указанные внутри тега в html коде не являются его дочерними элементами.
Бразуеры при создании элемента создают DocumentFragment чьим документом является т.н. approptiate template contents owner document, определяемый по этому алгоритму, документа в котором указан и указывает значением свойства .content созданный DocumentFragment.
То есть свойство .content у элемента template содержит DocumentFragment, и элементы, которые в html коде были указаны внутри тегов являются дочерними элементами именно этого DocumentFragment.
При этом элементу , как и любому другому, можно добавить дочерние элементы (appendChild()), но это будет считаться нарушение модели содержимого шаблона.
Клонирование шаблона
При клонирования содержимого шаблона важно помнить, что первый аргумент в .cloneNode([deep]) или второй в .importNode(externalNode, deep) передавать обязательно надо (согласно спецификации, если аргумент не будет передан, дальнейшее выполнение происходить не должно).
Кстати, да, не смотря на то что большинство примеров используют именно .cloneNode(), использование .importNode() тоже возможно. Разница только в том, когда документ обновится (для .cloneNode() — после вызова appendChild(); для .importNode() — после клонирования).
Использование шаблонов действительно очень простое. Я продолжу пример компоненты таб, с кодом которых я работала в примерах предыдущих статей.
Начинать я буду с того, что создам в html разметке два элемента и перенесу в них ту разметку, что была в методе .render() классов TabNavigationItem и TabContentItem (я также изменила некоторые стили но на функциональность это не влияет):
В конструкторе каждого класса я сохраню свойство template. Для TabNavigationItem это будет:
В этом примере оба шаблона указаны в html, что выглядит громозким и не есть гуд. Это плавно переводит нас к теме:
HTML импорты
Импорты представляют собой HTML документы которые подключены в качестве внешних ресурсов другим HTML документом. Система взаимоотношений между документами хорошо описана в черновике спецификации и не является предметом данной статьи.
Общая схема видна на изображении:
.
Для того чтобы реализовать импорты был добавлен новый тип в HTML link types (значения атрибута rel).
Слово import, указанное в значение атрибута rel элемента собственно и создает ссылку к импортируемому ресурсу (дефолтным типом ресурса является text/html).
У элемента может присутствовать атрибут async.
Расширения, предлагаемые черновиком спецификации предлагаются в АПИ HTMLLinkElement: добавляется свойство import, доступное только для чтения и содержащее импортируемый документ.
Свойство может содержать значение null в двух случаях: когда не представляет import или не находится в документе.
В спецификации отдельно указано что один и тот же объект должен будет возвращаться всегда.
В контексте импортов, есть так называемый мастер-документ (master document), которым является тот документ, который импортирует ресурсы одновременно не являясь при этом чьим либо импортируемым ресурсом.
ContentSecurityPolicy такого документа должна ограничивать все импорты. Так, если Content Security Header Field поставлен в значение импорта, браузер должен принудительно исполнять политику именно мастер-документа к импортируемому документу.
На практике
Для компонента таб, я создаю папку templates. В ней я создам два файла, в которые я перенесу разметку компоненты.
В файла index.html я импортирую шаблоны:
Элементам я добавляю id атрибуты, так как мне понадобится обращаться к ним из js. Теперь в конструкторах классов TabNavigationItem и TabContentItem для получения документа шаблона мне достаточно будет найти соответствующий элемент и обратится к его свойству import, после чего поиск шаблона я буду выполнять уже в импортируемом документе:
Поддержка HTML templates: Edge c 16, Firefox c 59, Chrome c 49, Safari c 11. С поддержкой импортов печальнее: Chrome c 49. Потому примеры из этой статьи можно посмотреть только в последних Chrome.
HTML Starter Template – A Basic HTML5 Boilerplate for index.html
Dillion Megida
HTML has different tags, some of which have semantic meanings. A basic boilerplate for an HTML file looks like this:
Welcome to My Website
In the rest of this article, I’ll explain what each part of this boilerplate means.
HTML Boilerplate Syntax
DOCTYPE
This element is the doctype declaration of the HTML file. tells the browser to render the HTML codes as HTML5 (as opposed to some other version of HTML).
This is important, because without this declaration, HTML5 elements like section , article , and so on may not be rendered correctly.
html tag
The html tag is the root of the HTML document. It houses the head tag, the body tag, and every other HTML element (except the DOCTYPE) used in your website.
It also has the lang attribute, which you can use to specify the language of the text content on a website. The default value is «unknown», so it is recommended that you always specify a language.
Defining a language helps screen readers read words correctly and helps search engines return language-specific search results.
head tag
The head tag houses the metadata of your website. These are visually invisible data to the user, but they provide information about your website’s content. Search engines especially use this data to rank your website.
Metadata in the head tag includes meta tags, title tags, link tags, scripts, stylesheets, and more.
meta tags
The meta tag is a metadata element used to add more metadata to your website than the kind that non-meta tags like title provide.
You can use these tags for various purposes:
adding metadata for social media platforms to create link previews
adding a description for your website
adding a character encoding for your website
and many more.
Search engines, social media platforms, and web services use this metadata to understand the content of your website and determine how to present them to users.
title tag
The title tag is used to specify a title for your website. Your browser uses this to display a title at the title bar:
This tag also helps search engines show titles for your website on their search results:
link tag
You use the link tag, as the name implies, to link to another document. Usually, this establishes different kinds of relationships between the current document and a separate document.
For example, as seen in the code block above, we’ve established a «stylesheet» document relationship with the styles.css file.
The most common use of this tag is to add stylesheets to a document and to also add favicons to a website:
A favicon is a small image close to the title of the webpage, as seen below:
body tag
The body tag houses the body content of a website, which is visible to users. Although non-visible elements like style and script can also be added here, most body tags are usually visible.
From headings to paragraphs to media and lots more, those elements are added here. Any element not found here (which could be included in the head tag) will not be shown on the screen.
main tag
The main tag specifies the essential content of a website. This would be the content related to the website’s title.
For example, a blog post page. The social media sharing on the left, advertisements on the right, header, and footer are minor parts of the web page. The post itself showing the cover image, the title, and post text content is the central part, which would be in the main element.
h1 tag
HTML has different heading elements which are h1 , h2 , h3 , h4 , h5 and h6 . Heading elements are used to describe different sections of a web page. And these elements have an order, with the h1 being the highest.
You should only have one h1 element on a webpage as this starts the main section. And then, you have other sections and subsections for which you can use the other heading elements.
Also, note that you shouldn’t skip headings. For example, you shouldn’t use an h4 element after using an h2 element. A good structure could be like this:
Welcome to my website
What do I have to offer
1. Financial Benefits
2. Society improves
a. Improving the tax system
b. Providing more refuse dumps
Who am I
Conclusion
From this code, you can see how the heading levels specify their position in sections and subsections.
Wrap up
In this piece, we’ve seen an HTML starter boilerplate and what each tag used in this template means.
This list of elements is non-exhaustive as many more elements can be found in the head tag and the body tag, with numerous attributes, too.
В новом стандарте многое упростилось и теперь базовая часть выглядит так:
Новые теги HTML5
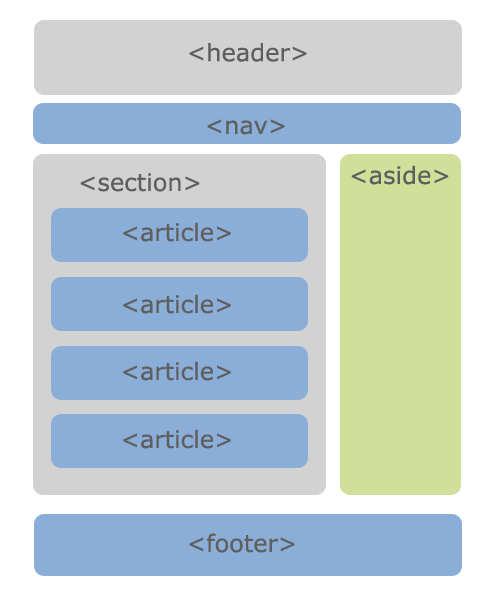
В HTML5 для структуры кода введено несколько новых тегов: , , , , , которые заменяют в некоторых случаях привычный . Сделано это для поисковых роботов, чтобы они лучше распознавали код страниц и отделяли основной контент от вспомогательных элементов.
С использованием новых тегов пустой шаблон HTML5 может выглядеть так:
Заголовок страницыКонтент - основное содержимое страницы.
Упрощение написания DOCTYPE
Вспомним как было раньше, в HTML4 тег DOCTYPE выглядел так:
Теперь же запись минимальна, проще, наверное некуда :
Похожие упрощения произошли и с остальными тегами, так что переход на стандарт HTML5 существенно облегчает написание.
Необязательные теги в HTML5
Новый стандарт принес много послаблений верстальщикам. В частности, использование элементов HTML, HEAD и BODY уже не является обязательным для разметки HTML5. Если их нет, то браузер все равно считает, что они существуют. По сути из обязательных в HTML5 остался только .
Трактовка русского языка как основного языка HTML документа
Тег определяет язык документа. В сети регулярно возникают дискуссии о правильном его написании, в частности правильность написания «ru-RU». Я склоняюсь к варианту, что «-RU» является избыточным, так как у русского языка нет диалектов и вариантов написания как у Английского языка (Британский и Американский). Суффикс RU уточняет, где говорят на русском языке. То есть если en-US означает «английский язык на котором говорят в США», то ru-RU означает «русский язык на котором говорят в России», что является излишним.
В прочем, ничего страшного не случится, если вы и дальше будете использовать вариант «ru-RU».
Благодарности
При написании статьи были использованы следующие источники: