sklearn.cluster.MeanShift
Средняя кластеризация сдвига с помощью плоского ядра.
Кластеризация среднего сдвига направлена на обнаружение «капель» в равномерной плотности выборок. Это алгоритм на основе центроидов, который работает путем обновления кандидатов на центроиды, чтобы они были средними точками в заданной области. Затем эти кандидаты фильтруются на этапе постобработки, чтобы исключить почти дубликаты и сформировать окончательный набор центроидов.
Посев осуществляется с использованием техники отбивания для масштабирования.
Parameters bandwidthfloat, default=None
Полоса пропускания,используемая в ядре RBF.
Если не указано,то пропускная способность оценивается с использованием sklearn.cluster.estimate_bandwidth;см.документацию по этой функции для подсказок о масштабируемости (см.также Примечания ниже).
seedsarray-like of shape (n_samples, n_features), default=None
Семена,используемые для инициализации ядер.Если параметр не установлен,семена вычисляются по методу clustering.get_bin_seeds с шириной полосы пропускания в качестве размера сетки и значениями по умолчанию для других параметров.
Если параметр true,то начальное расположение ядра-это не расположение всех точек,а расположение дискретизированной версии точек,где точки разбиты на сетку,грубость которой соответствует ширине полосы.Установка этого параметра в True ускорит работу алгоритма,так как будет инициализировано меньшее количество семян.Значение по умолчанию-False.Игнорируется,если аргумент seeds не None.
Чтобы ускорить работу алгоритма,в качестве семян принимайте только те бункеры,в которых есть хотя бы мин_бин_фрек.
Если это так,то все точки сгруппированы,даже те сироты,которые не входят ни в одно ядро.Сироты приписываются к ближайшему ядру.Если фальшивка,то сиротам присваивается ярлык кластера -1.
Количество рабочих мест для расчета.Это работает путем параллельного вычисления каждого из n_init.
None означает 1, если только в контексте joblib.parallel_backend . -1 означает использование всех процессоров. См. Глоссарий для более подробной информации.
Максимальное количество итераций на точку посадки до окончания кластеризации (для этой точки посадки),если она еще не сошла воедино.
Координаты кластерных центров.
labels_ndarray of shape (n_samples,)
Максимальное количество итераций,выполняемых для каждого семени.
Notes
Поскольку эта реализация использует плоское ядро и дерево шариков для поиска членов каждого ядра,сложность будет стремиться к O(T*n*log(n))в меньших размерах,с n количеством выборок и T количеством точек.В больших измерениях сложность будет стремиться к O(T*n^2).
Масштабируемость можно увеличить,используя меньшее количество семян,например,используя большее значение min_bin_freq в функции get_bin_seeds.
Обратите внимание,что функция estimate_bandwidth гораздо менее масштабируема,чем алгоритм сдвига среднего и будет узким местом при ее использовании.
References
Дорин Команичиу и Питер Меер, «Средний сдвиг: надежный подход к анализу пространства признаков». IEEE Transactions по анализу образов и машинному интеллекту. 2002. стр. 603-619.
Examples
>>> from sklearn.cluster import MeanShift >>> import numpy as np >>> X = np.array([[1, 1], [2, 1], [1, 0], . [4, 7], [3, 5], [3, 6]]) >>> clustering = MeanShift(bandwidth=2).fit(X) >>> clustering.labels_ array([1, 1, 1, 0, 0, 0]) >>> clustering.predict([[0, 0], [5, 5]]) array([1, 0]) >>> clustering MeanShift(bandwidth=2)
Methods
Выполняет кластеризацию на X и возвращает метки кластера.
Получить параметры для этой оценки.
Прогнозируйте ближайший кластер,к которому принадлежит каждый образец в Х.
Задайте параметры этой оценки.
Parameters Xarray-like of shape (n_samples, n_features)
yIgnored fit_predict(X, y=None) [source]
Выполняет кластеризацию на X и возвращает метки кластера.
Parameters Xarray-like of shape (n_samples, n_features)
Не используется,присутствует для согласованности API по соглашению.
Returns labelsndarray of shape (n_samples,), dtype=np.int64
Получить параметры для этой оценки.
Parameters deepbool, default=True
Если значение True,будут возвращены параметры для данного оценщика и содержащихся в нем подобъектов,являющихся оценщиками.
Имена параметров привязаны к их значениям.
Прогнозируйте ближайший кластер,к которому принадлежит каждый образец в Х.
Parameters X of shape (n_samples, n_features)
Новые данные для предсказания.
Returns labelsndarray of shape (n_samples,)
Индекс кластера,к которому принадлежит каждая выборка.
Задайте параметры этой оценки.
Метод работает как с простыми оценщиками, так и с вложенными объектами (такими как Pipeline ). Последние имеют параметры вида __ , так что можно обновить каждый компонент вложенного объекта.
Returns selfestimator instance
sklearn.cluster .MeanShift¶
Mean shift clustering aims to discover “blobs” in a smooth density of samples. It is a centroid-based algorithm, which works by updating candidates for centroids to be the mean of the points within a given region. These candidates are then filtered in a post-processing stage to eliminate near-duplicates to form the final set of centroids.
Seeding is performed using a binning technique for scalability.
Parameters : bandwidth float, default=None
Bandwidth used in the flat kernel.
If not given, the bandwidth is estimated using sklearn.cluster.estimate_bandwidth; see the documentation for that function for hints on scalability (see also the Notes, below).
seeds array-like of shape (n_samples, n_features), default=None
Seeds used to initialize kernels. If not set, the seeds are calculated by clustering.get_bin_seeds with bandwidth as the grid size and default values for other parameters.
bin_seeding bool, default=False
If true, initial kernel locations are not locations of all points, but rather the location of the discretized version of points, where points are binned onto a grid whose coarseness corresponds to the bandwidth. Setting this option to True will speed up the algorithm because fewer seeds will be initialized. The default value is False. Ignored if seeds argument is not None.
min_bin_freq int, default=1
To speed up the algorithm, accept only those bins with at least min_bin_freq points as seeds.
cluster_all bool, default=True
If true, then all points are clustered, even those orphans that are not within any kernel. Orphans are assigned to the nearest kernel. If false, then orphans are given cluster label -1.
n_jobs int, default=None
The number of jobs to use for the computation. The following tasks benefit from the parallelization:
- The search of nearest neighbors for bandwidth estimation and label assignments. See the details in the docstring of the NearestNeighbors class.
- Hill-climbing optimization for all seeds.
None means 1 unless in a joblib.parallel_backend context. -1 means using all processors. See Glossary for more details.
max_iter int, default=300
Maximum number of iterations, per seed point before the clustering operation terminates (for that seed point), if has not converged yet.
Coordinates of cluster centers.
labels_ ndarray of shape (n_samples,)
n_iter_ int
Maximum number of iterations performed on each seed.
Number of features seen during fit .
Names of features seen during fit . Defined only when X has feature names that are all strings.
Because this implementation uses a flat kernel and a Ball Tree to look up members of each kernel, the complexity will tend towards O(T*n*log(n)) in lower dimensions, with n the number of samples and T the number of points. In higher dimensions the complexity will tend towards O(T*n^2).
Scalability can be boosted by using fewer seeds, for example by using a higher value of min_bin_freq in the get_bin_seeds function.
Note that the estimate_bandwidth function is much less scalable than the mean shift algorithm and will be the bottleneck if it is used.
Dorin Comaniciu and Peter Meer, “Mean Shift: A robust approach toward feature space analysis”. IEEE Transactions on Pattern Analysis and Machine Intelligence. 2002. pp. 603-619.
>>> from sklearn.cluster import MeanShift >>> import numpy as np >>> X = np.array([[1, 1], [2, 1], [1, 0], . [4, 7], [3, 5], [3, 6]]) >>> clustering = MeanShift(bandwidth=2).fit(X) >>> clustering.labels_ array([1, 1, 1, 0, 0, 0]) >>> clustering.predict([[0, 0], [5, 5]]) array([1, 0]) >>> clustering MeanShift(bandwidth=2)
Perform clustering on X and returns cluster labels.
Get metadata routing of this object.
Get parameters for this estimator.
Predict the closest cluster each sample in X belongs to.
Set the parameters of this estimator.
Parameters : X array-like of shape (n_samples, n_features)
Not used, present for API consistency by convention.
Returns : self object
Perform clustering on X and returns cluster labels.
Parameters : X array-like of shape (n_samples, n_features)
Not used, present for API consistency by convention.
Returns : labels ndarray of shape (n_samples,), dtype=np.int64
Get metadata routing of this object.
Please check User Guide on how the routing mechanism works.
Returns : routing MetadataRequest
A MetadataRequest encapsulating routing information.
Get parameters for this estimator.
Parameters : deep bool, default=True
If True, will return the parameters for this estimator and contained subobjects that are estimators.
Returns : params dict
Parameter names mapped to their values.
Predict the closest cluster each sample in X belongs to.
Parameters : X array-like of shape (n_samples, n_features)
Returns : labels ndarray of shape (n_samples,)
Index of the cluster each sample belongs to.
Set the parameters of this estimator.
The method works on simple estimators as well as on nested objects (such as Pipeline ). The latter have parameters of the form __ so that it’s possible to update each component of a nested object.
Parameters : **params dict
Returns : self estimator instance
DataTechNotes
Mean Shift is a centroid based clustering algorithm. It is a nonparametric clustering technique and does not require prior knowledge of the cluster numbers. The basic idea of the algorithm is to detect mean points toward the densest area in a region and to group the points based on those mean centers. The method first selects the points in the window area, then calculates the mean point in the area, and shifts the window toward the dense area until the convergence of regions. The window area radius can be identified with the parameter of bandwidth in the model definition.
In this post, we’ll briefly learn how to cluster data with the Mean Shift algorithm with sklearn’s MeanShift class in Python. The article covers:
from sklearn.cluster import MeanShift from sklearn.datasets.samples_generator import make_blobs import matplotlib.pyplot as plt import numpy as np We’ll create a sample dataset for clustering with make_blob function and visualize it in a plot.
np.random.seed(1) x, _ = make_blobs(n_samples=300, centers=5, cluster_std=.8) plt.scatter(x[:,0], x[:,1]) plt.show() 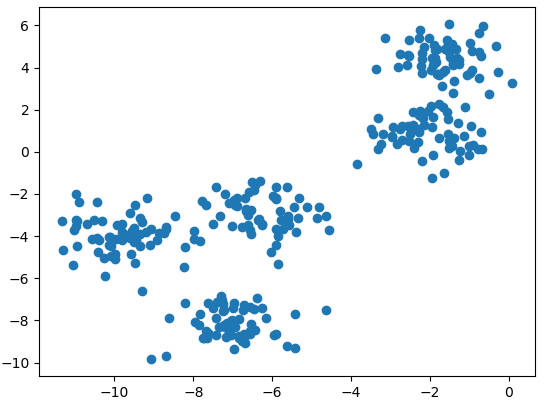
Clustering with Mean Shift
Next, we’ll define the MeanShift model and fit it with the x data. We set 2 for the bandwidth parameter to define the window area size.
mshclust=MeanShift(bandwidth=2).fit(x) print(mshclust) MeanShift(bandwidth=2, bin_seeding=False, cluster_all=True, min_bin_freq=1, n_jobs=1, seeds=None) Now, we can get labels (or cluster id) and center points of each cluster area.
labels = mshclust.labels_ centers = mshclust.cluster_centers_ Finally, we’ll visualize the clustered points by separating them with different colors and center points of each cluster in a plot.
plt.scatter(x[:,0], x[:,1], c=labels) plt.scatter(centers[:,0],centers[:,1], marker='*', color="r",s=80 ) plt.show() 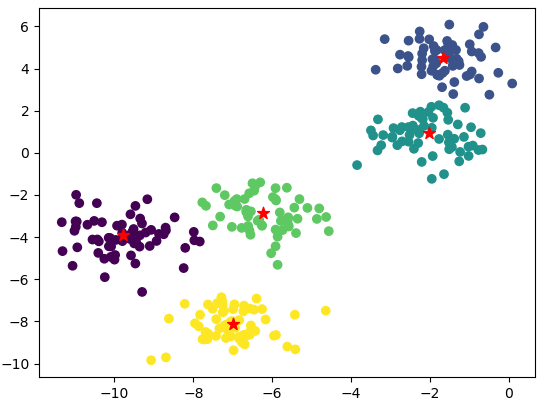
In this post, we’ve briefly learned how to cluster data with the Shift Mean method in Python.
from sklearn.cluster import MeanShift from sklearn.datasets.samples_generator import make_blobs import matplotlib.pyplot as plt import numpy as np np.random.seed(1) x, _ = make_blobs(n_samples=300, centers=5, cluster_std=.8) plt.scatter(x[:,0], x[:,1]) plt.show() mshclust=MeanShift(bandwidth=2).fit(x) print(mshclust) labels = mshclust.labels_ centers = mshclust.cluster_centers_ plt.scatter(x[:,0], x[:,1], c=labels) plt.scatter(centers[:,0],centers[:,1], marker='*', color="r",s=80 ) plt.show()