Pivot Data Using Informatica Java Transformation
Java transformation is very powerful in Informatica. But there are not many examples on web about using Java Transformation. That because for most mappings you don’t need Java transformation. But for some cases, using Java transformation will make your mappings simpler and easier. In this blog I will show you a full example of using Java transformation to pivot data. Suppose you have source data like this:
Source:
| STUDENTID | NAME | SUBJECT | SCORE |
|---|---|---|---|
| 1001 | Alice | Math | 100 |
| 1001 | Alice | English | 85 |
| 1002 | Bob | Math | 98 |
| 1002 | Bob | English | 95 |
| 1002 | Bob | Science | 90 |
| 1003 | Chris | Math | 95 |
| 1003 | Chris | Science | 90 |
| 1003 | Chris | English | 80 |
Normally, you would have to use Expression, Sorter and Aggregator Transformations to achieve this. As you can find lots of discussions on web using this way. Though it works, it’s tedious and unmaintainable especially when the target has many columns and many different aggregations. Here are steps to use Java transformation to pivot the source data: Step 1 – Create a mapping having source «PIVOT_TEST_SRC» and target » PIVOT_TEST_TGT»: 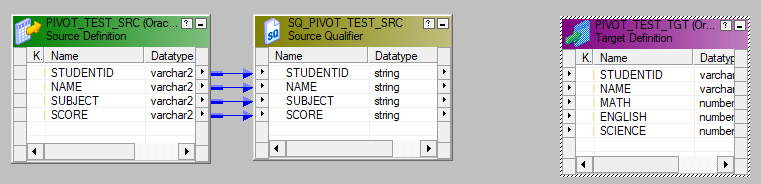 Step 2 – In the create transformation window, select Java from the list and enter a name for the transformation :
Step 2 – In the create transformation window, select Java from the list and enter a name for the transformation : 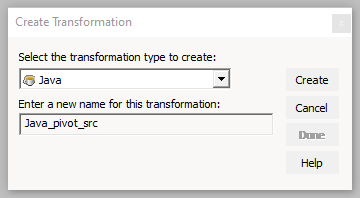 Then choose Active type. With the Active type, the number of input rows can differ from the number of output rows.
Then choose Active type. With the Active type, the number of input rows can differ from the number of output rows. 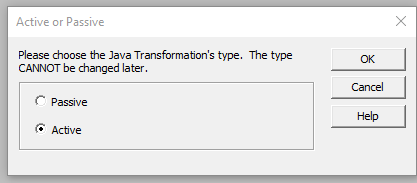 Step 3 – Drag and drop all the Source qualifier columns to the Java transformation:
Step 3 – Drag and drop all the Source qualifier columns to the Java transformation:  Step 4 – Double click the Java_pivot_src and choose the Ports tab; add ports out_studentId, out_studentName, out_mathScore, out_englishScore, and out_scienceSore as output ports:
Step 4 – Double click the Java_pivot_src and choose the Ports tab; add ports out_studentId, out_studentName, out_mathScore, out_englishScore, and out_scienceSore as output ports:  Save your work. You mapping looks like this:
Save your work. You mapping looks like this:  Step 5 – Double click the Java_pivot_src and choose the “Java Code” tab on top. By default, you are in “On Input Row” tab at the bottom.
Step 5 – Double click the Java_pivot_src and choose the “Java Code” tab on top. By default, you are in “On Input Row” tab at the bottom.  There are other tabs “Import Packages”, “Helper Code”, “On End of Data”, etc, which are self-explanatory. For this example, I am going to use Java Hashmap to save student name, subject and its score where key are Name, Math, English and Science (target column names) and values are student_name, respective subject scores :
There are other tabs “Import Packages”, “Helper Code”, “On End of Data”, etc, which are self-explanatory. For this example, I am going to use Java Hashmap to save student name, subject and its score where key are Name, Math, English and Science (target column names) and values are student_name, respective subject scores :
Name -> student_name Math -> math_score English -> English_score Science -> science_score This hashmap will be embedded in another hashmap (allRecords) where key is student id. So the final hashmap structure looks like:
|--> Name -> student_name Student_id-> |--> Math -> math_score |--> English -> English_score |--> Science-> science_score import java.util.HashMap; import java.util.Map; private HashMapString, HashMapString, Object>> allRecords= new HashMapString, HashMapString, Object>>(); static int inputRows=0; static int outputRows=0; HashMapString, Object> subjectSore; if (!isNull("STUDENTID")) inputRows += 1; if (allRecords.containsKey(STUDENTID)) subjectSore = allRecords.get(STUDENTID); subjectSore.put(SUBJECT, SCORE); > else //build new key value pair subjectSore = new HashMapString, Object>(); subjectSore.put("Name", NAME); subjectSore.put("Math", null); subjectSore.put("English", null); subjectSore.put("Science", null); subjectSore.put(SUBJECT, SCORE); //add subjectSore to hashmap allRecords.put(STUDENTID, subjectSore); > > HashMapString, Object> outsubjectSoreMap; for (Map.EntryString, HashMapString, Object>> entry : allRecords.entrySet()) outsubjectSoreMap = entry.getValue(); out_studentId = entry.getKey(); //get("STUDENTID"); out_studentName = (String) outsubjectSoreMap.get("Name"); if (outsubjectSoreMap.get("Math") == null) out_mathSore = ""; > else out_mathSore = (String) outsubjectSoreMap.get("Math"); > if (outsubjectSoreMap.get("English") == null) out_englishSore = ""; > else out_englishSore = (String) outsubjectSoreMap.get("English"); > if (outsubjectSoreMap.get("Science") == null) out_scienceScore = ""; > else out_scienceScore = (String) outsubjectSoreMap.get("Science"); > generateRow(); outputRows +=1; > // end for loop: output records allRecords.clear(); //release memory logInfo("The total number of records generated is: " + outputRows); inputRows=0; outputRows=0; generateRow() is PowerCenter Java API, which generates rows according to the defined output ports values.
If the input records are too many to hold in the hashmap, you can use generateRow() in the “On Input row” tab to generate some output ports values and then release memory. If you want to this, you need sort expression to sort the input records before Java Transformation, Otherwise you may get duplicated student ids in output records.
HashMapString, Object> subjectSore; if (!isNull("STUDENTID")) inputRows += 1; if (allRecords.containsKey(STUDENTID)) subjectSore = allRecords.get(STUDENTID); subjectSore.put(SUBJECT, SCORE); > else //build new key value pair if (inputRows >=1000) // output records when processed 1000 rows to release memory HashMapString, Object> outsubjectSoreMap; for (Map.EntryString, HashMapString, Object>> entry : allRecords.entrySet()) outsubjectSoreMap = entry.getValue(); out_studentId = entry.getKey(); //get("STUDENTID"); out_studentName = (String) outsubjectSoreMap.get("Name"); if (outsubjectSoreMap.get("Math") == null) out_mathSore = ""; > else out_mathSore = (String) outsubjectSoreMap.get("Math"); > if (outsubjectSoreMap.get("English") == null) out_englishSore = ""; > else out_englishSore = (String) outsubjectSoreMap.get("English"); > if (outsubjectSoreMap.get("Science") == null) out_scienceScore = ""; > else out_scienceScore = (String) outsubjectSoreMap.get("Science"); > generateRow(); outputRows +=1; > // end for loop: output records allRecords.clear(); //release memory > //end if countRows >= 1000 subjectSore = new HashMapString, Object>(); subjectSore.put("Name", NAME); subjectSore.put("Math", null); subjectSore.put("English", null); subjectSore.put("Science", null); subjectSore.put(SUBJECT, SCORE); //add subjectSore to hashmap allRecords.put(STUDENTID, subjectSore); > > 
Inside the java code, you can use java System.out.println() or PowerCenter Java API logInfo() to log debug information, which can be found in session log. I added an Expression transformation to convert string to integer to match data type in target:
that’s it. If you Java code ran into exceptions, open the session log and found the error messages. For example, here was the error I got:
JAVA PLUGIN_1762 [ERROR] java.lang.NullPointerException JAVA PLUGIN_1762 [ERROR] at com.informatica.powercenter.server.jtx.JTXPartitionDriverImplGen.execute(JTXPartitionDriverImplGen.java:382) This “JTXPartitionDriverImplGen.java:382” gave you where exactly which row has the error. Open the Java transformation, click the ‘Full code” link, it pops up a window with full java code in it. Copy the java code and paste to your favorite editor, go the error line (in this example the line number is 382) then analyze why it threw you that error. As you can see from the example above, how easy it is to pivot date using Java transformation. Java transformation can be used to compress data, encrypt/decrypt data, concatenate some fields, aggregate special fields and much more. Just minor changes of the code in this example, you can easily build mappings to ETL data from non-SQL database to an SQL database and vice versa.
Transformations
functionality with the Java transformation. The Java transformation provides a simple, native programming interface to define transformation functionality with the Java programming language.
You can use the Java transformation to quickly define simple or moderately complex transformation functionality without advanced knowledge of the Java programming language. The Java transformation can be an active or passive transformation.
The Secure Agent requires a Java Development Kit (JDK) to compile the Java code and generate byte code for the transformation. Azul OpenJDK is installed with the Secure Agent, so you do not need to install a separate JDK. Azul OpenJDK includes the Java Runtime Environment (JRE).
task that includes a Java transformation, the Secure Agent uses the JRE to execute the byte code, process input rows, and generate output rows.
To create a Java transformation, you write Java code snippets that define the transformation logic. Define transformation behavior for a Java transformation based on the following events:
You cannot use the Java transformation with a Graviton-enabled cluster. For more information about Graviton-enabled clusters, see the Administrator help.
When you create a Java transformation, ensure that you review the Java code to verify that it is free from potentially unsafe active content such as queries, remote scripts, or data connections before you run the code in a mapping task.
Java Transformation in Informatica with Example

![]()
Java Transformation in Informatica , is a connected and active /Passive transformation which provides a simple native programming interface to define transformation functionality with the Java programming language. You can use Java transformation in Informatica to quickly define simple or moderately complex transformation functionality without advanced knowledge of the Java programming language or an external Java development environment
Must read : check more about Informatica Naming convention
Few of the sample scenarios are as follows:
- A Java transformation contains two input ports that represent a start date and an end date. You can generate an output row for each date between the start date and end date.
- you can define transformation logic to loop through input rows and generate multiple output rows based on a specific condition.
Must check : Please also check how to create Aggregator Transformation
![]()
A very good example of Active Java transformation can be found here
Create a Informatica mapping to convert subject wise marks (populated in different rows) for student into a single row for each student with marks in a separate column for each subject.
Source Data:
STUDENT_MARKS Table Data
| STUDENT_NO | SUBJECT | MARKS |
|---|---|---|
| 1 | Math | 87 |
| 1 | Eng | 66 |
| 1 | Science | 78 |
| 2 | Math | 45 |
| 2 | Eng | 64 |
| 2 | Science | 55 |
| 3 | Math | 46 |
| 3 | Eng | 89 |
| 4 | Science | 86 |