How to read an existing pdf file in java using iText jar?
To read an existing pdf file using iText jar first download the iText jar files and include in the application classpath.
Steps:
1. Create PdfReader instance.
2. Get the number of pages in pdf
3. Iterate the pdf through pages.
4. Extract the page content using PdfTextExtractor.
5. Process the page content on console.
6. Close the PdfReader.
Example:
PDFReadExample.java
import com.itextpdf.text.pdf.PdfReader; import com.itextpdf.text.pdf.parser.PdfTextExtractor; /** * This class is used to read an existing * pdf file using iText jar. * @author w3spoint */ public class PDFReadExample { public static void main(String args[]){ try { //Create PdfReader instance. PdfReader pdfReader = new PdfReader("D:\\testFile.pdf"); //Get the number of pages in pdf. int pages = pdfReader.getNumberOfPages(); //Iterate the pdf through pages. for(int i=1; ipages; i++) { //Extract the page content using PdfTextExtractor. String pageContent = PdfTextExtractor.getTextFromPage(pdfReader, i); //Print the page content on console. System.out.println("Content on Page " + i + ": " + pageContent); } //Close the PdfReader. pdfReader.close(); } catch (Exception e) { e.printStackTrace(); } } }
Output:
Content on Page 1: Hello world, this a test pdf file.
Content on Page 1: Hello world, this a test pdf file.
IText: вытаскиваем текст из PDF

Недавно столкнулся с задачей: научиться вытаскивать текст из PDF запоминая его позицию на странице. И, конечно же, в несложной поначалу задаче вылезли подводные камни. Как же в итоге получилось это решить? Ответ под катом.
Немного о PDF формате
PDF (Portable Document Format) — популярный межплатформенный формат документов, использующий язык PostScript. Основное его предназначение — корректное отображение на различных операционных системах и т. д.
- слова могут быть нелогично разбиты на части. Например отображение слова «алгоритмы» записано, грубо говоря, тремя частями: отобрази «алг» «орит» «мы»
- строчки в тексте и слова в строчках могут отображаться совсем не в том порядке, как мы привыкли читать
- в одних документах пробелы задаются явно (т.е. есть команды содержащие ‘ ‘), в других — они образуются при помощи того, что соседние слова отображаются друг от друга на некотором расстоянии
Потому желание парсить pdf самостоятельно пропало моментально.
p.s. от всего этого невольно вспомнилась цитата
Затем, поигравшись с несколькими библиотеками (pdfminer, pdfbox), я решил остановиться на iText.
Немного про iText
iText: библиотека на Java, предназначенная для работы с pdf (также есть версия на C#: iTextSharp). Начиная с версии 5.0.0 свободно распространяется по лицензии AGPL (обязывающая предоставлять пользователям возможность получения исходного кода), но также есть и коммерческая версия. Снабжена неплохой документацией. А тем, кто хочет ознакомиться с библиотекой по-лучше, советую книгу от создателя библиотеки «iText in Action».
Простой способ вытащить текст из PDF
Вот этот код неплохо извлекает текст из PDF, но не предоставляет какой-либо информации, о его расположении в документе.
public class SimpleTextExtractor < public static void main(String[] args) throws IOException < // считаем, что программе передается один аргумент - имя файла PdfReader reader = new PdfReader(args[0]); // не забываем, что нумерация страниц в PDF начинается с единицы. for (int i = 1; i // убираем за собой reader.close(); > > А теперь разберемся во всем по порядку.
PdfReader — класс, читающий PDF. Умеет конструироваться не только от имени файла, но и от InputStream, Url или RandomAccessFileOrArray.
TextExtractionStrategy — интерфейс, определяющий стратегию извлечения текста. Подробнее о нем — ниже.
SimpleTextExtractionStrategy — класс, реализующий TextExtractionStrategy. Несмотря на название, очень неплохо вытаскивает текст из PDF (справляется с переменчивой структурой PDF, а именно, если сначала текст идет в двух колонках, а затем переключается на обычное написание во всю страницу.
PdfTextExtractor — статический класс, содержащий лишь 2 метода getTextFromPage с одной разницей — указываем мы явно стратегию извлечения текста или нет.
Вытаскиваем текст, запоминая координаты
Для этого нам нужно обратить внимание на интерфейс TextExtractionStrategy. А именно на эти две функции:
public void renderText(TextRenderInfo renderInfo)— при вызове getTextFromPage эта функция вызывается при каждой команде, отображающей текст. В TextRenderInfo хранится вся необходимая информация: текст, шрифт, координаты.
public string GetResultantText()— эта функция вызывается перед окончанием getTextFromPage и ее результат вернется пользователю.
В качестве образца, научимся простейшим образом вытаскивать пары вида для каждой строки на странице.
public class TextExtractionStrategyImpl implements TextExtractionStrategy < private TreeMap> textMap; public TextExtractionStrategyImpl() < // reverseOrder используется потому что координата y на странице идет снизу вверх textMap = new TreeMap>(Collections.reverseOrder()); > @Override public String getResultantText() < StringBuilder stringBuilder = new StringBuilder(); // итерируемся по строкам for (Map.Entry> stringMap: textMap.entrySet()) < // итерируемся по частям внутри строки for (Map.Entryentry: stringMap.getValue().entrySet()) < stringBuilder.append(entry.getValue()); >stringBuilder.append('\n'); > return stringBuilder.toString(); > @Override public void beginTextBlock() <> @Override public void renderText(TextRenderInfo renderInfo) < // вытаскиваем координаты Float x = renderInfo.getBaseline().getStartPoint().get(Vector.I1); Float y = renderInfo.getBaseline().getStartPoint().get(Vector.I2); // если до этого мы не добавляли элементы из этой строчки файла. if (!textMap.containsKey(y)) < textMap.put(y, new TreeMap()); > textMap.get(y).put(x, renderInfo.getText()); > @Override public void endTextBlock() <> @Override public void renderImage(ImageRenderInfo imageRenderInfo) <> // метод для извлечения строчек с их y-координатой ArrayList getStringsWithCoordinates() < ArrayList result = new ArrayList(); for (Map.Entry> stringMap: textMap.entrySet()) < StringBuilder stringBuilder = new StringBuilder(); for (Map.Entryentry: stringMap.getValue().entrySet()) < stringBuilder.append(entry.getValue()); >result.add(new Pair(stringMap.getKey(), stringBuilder.toString())); > return result; > > А основной код выглядит так:
public class TextExtractor < public static void main(String[] args) throws IOException < PdfReader reader = new PdfReader(args[0]); for (int i = 1; i pair: strategy.getStringsWithCoordinates()) < System.out.println(pair.getKey().toString() + " " + pair.getValue()); >> reader.close(); > > Примечания
Конечно, для хорошего извлечения текста надо добавить всякие фишки для корректной обработки текста в нескольких колонках, обработки пробелов не заданных явно и т.д., но я не хочу в пределах этой статьи углубляться в такие детали.
И еще хотелось бы отметить, что это лишь малая часть возможностей библиотеки. При помощи нее можно создавать документы, добавлять текст и изображения в уже существующие (включая водяные знаки).
И ссылка на репозиторий (ох уж этот AGPL)
Java – Read and Write PDF with iText
In this iText tutorial, we are writing various code examples to read a PDF file and write a PDF file. iText library helps in dynamically generating the .pdf files from Java applications.
The given code examples are categorized into multiple sections based on the functionality they achieve. With each example, I have attached a screenshot of the generated PDF file to visualize what exactly the code is writing in the PDF file. You may extend these examples to suit your needs.
On the brighter side, iText is an open-source library. Note that though iText is open source, you still need to purchase a commercial license if you want to use it for commercial purposes.
iText is freely available from https://itextpdf.com/. The iText library is powerful and supports the generation of HTML, RTF, and XML documents and generating PDFs.
We can choose from various fonts to be used in the document. Also, the structure of iText allows us to generate any of the above-mentioned type of documents with the same code. Isn’t it a great feature, right?
The iText library contains classes to generate PDF text in various fonts, create tables in PDF documents, add watermarks to pages, and so on. There are many more features available with iText which I will leave on you to explore.
To add iText into your application, include the following maven repository into our pom.xml file.
com.itextpdf itextpdf 5.5.13.2 Or we can download the latest jar files from its maven repository.
Let’s list down and get familiar with the essential classes we will use in this application.
- com.itextpdf.text.Document : This is the most important class in iText library and represent PDF document instance. If you need to generate a PDF document from scratch, you will use the Document class. First you must create a Document instance. Then you must open it. After that you add content to the document. Finally you close the Document instance.
- com.itextpdf.text.Paragraph : This class represents a indented “paragraph” of text. In a paragraph you can set the paragraph alignment, indentation and spacing before and after the paragraph.
- com.itextpdf.text.Chapter : This class represents a chapter in the PDF document. It is created using a Paragraph as title and an int as chapter number.
- com.itextpdf.text.Font : This class contains all specifications of a font, such as family of font, size, style, and color. Various fonts are declared as static constants in this class.
- com.itextpdf.text.List : This class represents a list, which, in turn, contains a number of ListItems.
- com.itextpdf.text.pdf.PDFPTable : This is a table that can be put at an absolute position but can also be added to the document as the class Table.
- com.itextpdf.text.Anchor : An Anchor can be a reference or a destination of a reference. A link like we have in HTML pages.
- com.itextpdf.text.pdf.PdfWriter : When this PdfWriter is added to a certain PdfDocument, the PDF representation of every Element added to this Document will be written to the outputstream attached to writer (file or network).
- com.itextpdf.text.pdf.PdfReader : Used to read a PDF document. Simple and clear.
3. iText Hello World Example
Let’s start writing our example codes with the typical Hello World application. I will create a PDF file with a single statement in the content.
import java.io.FileNotFoundException; import java.io.FileOutputStream; import com.itextpdf.text.Document; import com.itextpdf.text.DocumentException; import com.itextpdf.text.Paragraph; import com.itextpdf.text.pdf.PdfWriter; public class JavaPdfHelloWorld < public static void main(String[] args) < Document document = new Document(); try < PdfWriter writer = PdfWriter.getInstance(document, new FileOutputStream("HelloWorld.pdf")); document.open(); document.add(new Paragraph("A Hello World PDF document.")); document.close(); writer.close(); >catch (DocumentException e) < e.printStackTrace(); >catch (FileNotFoundException e) < e.printStackTrace(); >> >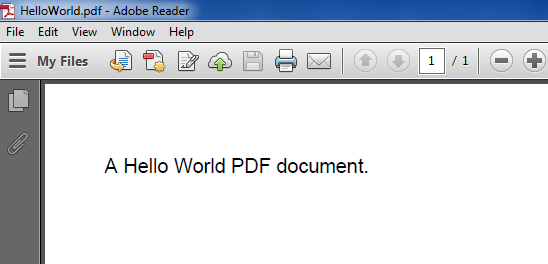
4. Setting File Attributes to PDF
This example shows how to set various attributes like author name, created date, creator name or simply title of the pdf file.
Document document = new Document(); try < PdfWriter writer = PdfWriter.getInstance(document, new FileOutputStream("SetAttributeExample.pdf")); document.open(); document.add(new Paragraph("Some content here")); //Set attributes here document.addAuthor("Lokesh Gupta"); document.addCreationDate(); document.addCreator("HowToDoInJava.com"); document.addTitle("Set Attribute Example"); document.addSubject("An example to show how attributes can be added to pdf files."); document.close(); writer.close(); >catch (Exception e) 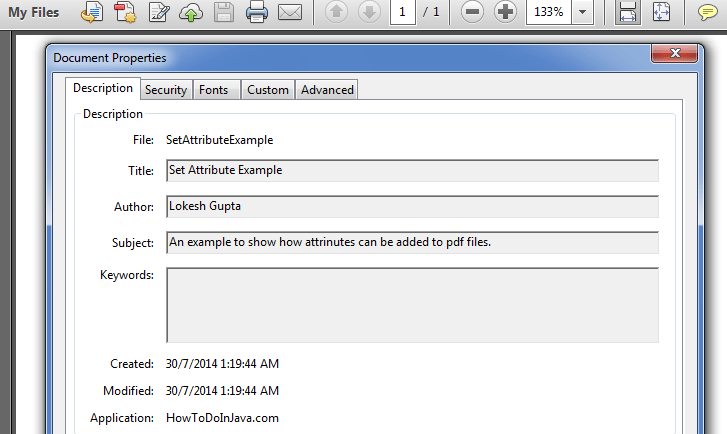
An example to show how we can add images to PDF files. The example contains adding images from the file system as well as URLs. Also, I have added code to position the pictures within the document.
Document document = new Document(); try < PdfWriter writer = PdfWriter.getInstance(document, new FileOutputStream("AddImageExample.pdf")); document.open(); document.add(new Paragraph("Image Example")); //Add Image Image image1 = Image.getInstance("temp.jpg"); //Fixed Positioning image1.setAbsolutePosition(100f, 550f); //Scale to new height and new width of image image1.scaleAbsolute(200, 200); //Add to document document.add(image1); String imageUrl = "http://www.eclipse.org/xtend/images/java8_logo.png"; Image image2 = Image.getInstance(new URL(imageUrl)); document.add(image2); document.close(); writer.close(); >catch (Exception e) 
6. Generating a Table in PDF
Below example shows how to add tables in a pdf document.
public static void main(String[] args) < Document document = new Document(); try < PdfWriter writer = PdfWriter.getInstance(document, new FileOutputStream("AddTableExample.pdf")); document.open(); PdfPTable table = new PdfPTable(3); // 3 columns. table.setWidthPercentage(100); //Width 100% table.setSpacingBefore(10f); //Space before table table.setSpacingAfter(10f); //Space after table //Set Column widths float[] columnWidths = ; table.setWidths(columnWidths); PdfPCell cell1 = new PdfPCell(new Paragraph("Cell 1")); cell1.setBorderColor(BaseColor.BLUE); cell1.setPaddingLeft(10); cell1.setHorizontalAlignment(Element.ALIGN_CENTER); cell1.setVerticalAlignment(Element.ALIGN_MIDDLE); PdfPCell cell2 = new PdfPCell(new Paragraph("Cell 2")); cell2.setBorderColor(BaseColor.GREEN); cell2.setPaddingLeft(10); cell2.setHorizontalAlignment(Element.ALIGN_CENTER); cell2.setVerticalAlignment(Element.ALIGN_MIDDLE); PdfPCell cell3 = new PdfPCell(new Paragraph("Cell 3")); cell3.setBorderColor(BaseColor.RED); cell3.setPaddingLeft(10); cell3.setHorizontalAlignment(Element.ALIGN_CENTER); cell3.setVerticalAlignment(Element.ALIGN_MIDDLE); //To avoid having the cell border and the content overlap, if you are having thick cell borders //cell1.setUserBorderPadding(true); //cell2.setUserBorderPadding(true); //cell3.setUserBorderPadding(true); table.addCell(cell1); table.addCell(cell2); table.addCell(cell3); document.add(table); document.close(); writer.close(); > catch (Exception e) < e.printStackTrace(); >>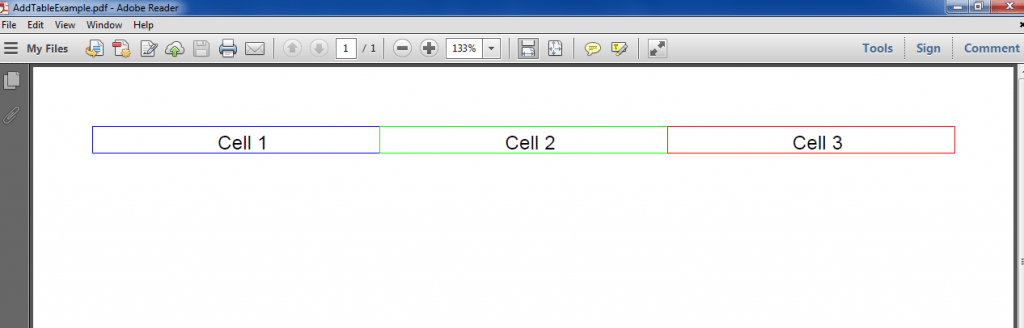
7. Creating List of Items in PDF
Below example will help you understand how to write lists in pdf files using the iText library.
Document document = new Document(); try < PdfWriter writer = PdfWriter.getInstance(document, new FileOutputStream("ListExample.pdf")); document.open(); document.add(new Paragraph("List Example")); //Add ordered list List orderedList = new List(List.ORDERED); orderedList.add(new ListItem("Item 1")); orderedList.add(new ListItem("Item 2")); orderedList.add(new ListItem("Item 3")); document.add(orderedList); //Add un-ordered list List unorderedList = new List(List.UNORDERED); unorderedList.add(new ListItem("Item 1")); unorderedList.add(new ListItem("Item 2")); unorderedList.add(new ListItem("Item 3")); document.add(unorderedList); //Add roman list RomanList romanList = new RomanList(); romanList.add(new ListItem("Item 1")); romanList.add(new ListItem("Item 2")); romanList.add(new ListItem("Item 3")); document.add(romanList); //Add Greek list GreekList greekList = new GreekList(); greekList.add(new ListItem("Item 1")); greekList.add(new ListItem("Item 2")); greekList.add(new ListItem("Item 3")); document.add(greekList); //ZapfDingbatsList List Example ZapfDingbatsList zapfDingbatsList = new ZapfDingbatsList(43, 30); zapfDingbatsList.add(new ListItem("Item 1")); zapfDingbatsList.add(new ListItem("Item 2")); zapfDingbatsList.add(new ListItem("Item 3")); document.add(zapfDingbatsList); //List and Sublist Examples List nestedList = new List(List.UNORDERED); nestedList.add(new ListItem("Item 1")); List sublist = new List(true, false, 30); sublist.setListSymbol(new Chunk("", FontFactory.getFont(FontFactory.HELVETICA, 6))); sublist.add("A"); sublist.add("B"); nestedList.add(sublist); nestedList.add(new ListItem("Item 2")); sublist = new List(true, false, 30); sublist.setListSymbol(new Chunk("", FontFactory.getFont(FontFactory.HELVETICA, 6))); sublist.add("C"); sublist.add("D"); nestedList.add(sublist); document.add(nestedList); document.close(); writer.close(); >catch (Exception e) 
8. Styling the PDF Content
Let’s see some examples of styling the content of PDF. The example contains the usage of Fonts, chapters, and sections.
Font blueFont = FontFactory.getFont(FontFactory.HELVETICA, 8, Font.NORMAL, new CMYKColor(255, 0, 0, 0)); Font redFont = FontFactory.getFont(FontFactory.COURIER, 12, Font.BOLD, new CMYKColor(0, 255, 0, 0)); Font yellowFont = FontFactory.getFont(FontFactory.COURIER, 14, Font.BOLD, new CMYKColor(0, 0, 255, 0)); Document document = new Document(); try < PdfWriter writer = PdfWriter.getInstance(document, new FileOutputStream("StylingExample.pdf")); document.open(); //document.add(new Paragraph("Styling Example")); //Paragraph with color and font styles Paragraph paragraphOne = new Paragraph("Some colored paragraph text", redFont); document.add(paragraphOne); //Create chapter and sections Paragraph chapterTitle = new Paragraph("Chapter Title", yellowFont); Chapter chapter1 = new Chapter(chapterTitle, 1); chapter1.setNumberDepth(0); Paragraph sectionTitle = new Paragraph("Section Title", redFont); Section section1 = chapter1.addSection(sectionTitle); Paragraph sectionContent = new Paragraph("Section Text content", blueFont); section1.add(sectionContent); document.add(chapter1); document.close(); writer.close(); >catch (Exception e) 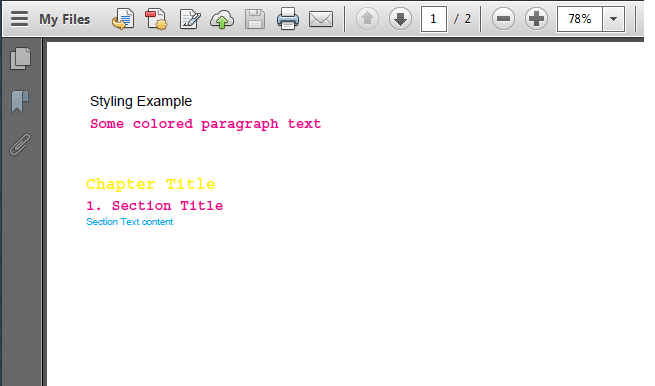
Let’s see an example of creating password protected pdf file. Here writer.setEncryption() is used to set a password to the generated PDF.
We need to add bouncy castle jars generating for password protected PDFs. I have added these jars in sourcecode of examples for this post.
private static String USER_PASSWORD = "password"; private static String OWNER_PASSWORD = "lokesh"; public static void main(String[] args) < try < OutputStream file = new FileOutputStream(new File("PasswordProtected.pdf")); Document document = new Document(); PdfWriter writer = PdfWriter.getInstance(document, file); writer.setEncryption(USER_PASSWORD.getBytes(), OWNER_PASSWORD.getBytes(), PdfWriter.ALLOW_PRINTING, PdfWriter.ENCRYPTION_AES_128); document.open(); document.add(new Paragraph("Password Protected pdf example !!")); document.close(); file.close(); >catch (Exception e) < e.printStackTrace(); >>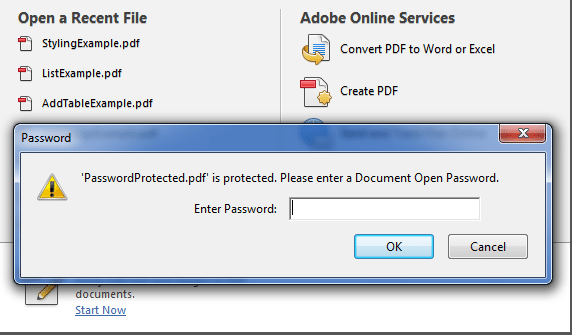
10. Creating PDF with Limited Permissions
In this example, I am setting a few file permissions for a pdf file to limit access for other users. Following are several permission values:
PdfWriter.ALLOW_PRINTING PdfWriter.ALLOW_ASSEMBLY PdfWriter.ALLOW_COPY PdfWriter.ALLOW_DEGRADED_PRINTING PdfWriter.ALLOW_FILL_IN PdfWriter.ALLOW_MODIFY_ANNOTATIONS PdfWriter.ALLOW_MODIFY_CONTENTS PdfWriter.ALLOW_SCREENREADERS You can provide multiple permissions by ORing different values. For example, PdfWriter.ALLOW_PRINTING | PdfWriter.ALLOW_COPY.
public static void main(String[] args) < try < OutputStream file = new FileOutputStream(new File( "LimitedAccess.pdf")); Document document = new Document(); PdfWriter writer = PdfWriter.getInstance(document, file); writer.setEncryption("".getBytes(), "".getBytes(), PdfWriter.ALLOW_PRINTING , //Only printing allowed; Try to copy text !! PdfWriter.ENCRYPTION_AES_128); document.open(); document.add(new Paragraph("Limited Access File !!")); document.close(); file.close(); >catch (Exception e) < e.printStackTrace(); >>11. Reading and Modifying an Existing PDF
To complete this tutorial, let’s see an example of reading and modifying a PDF file using PDFReader class provided by the iText library itself. In this example, I will read content from a PDF and add some random content to all its pages.
public static void main(String[] args) < try < //Read file using PdfReader PdfReader pdfReader = new PdfReader("HelloWorld.pdf"); //Modify file using PdfReader PdfStamper pdfStamper = new PdfStamper(pdfReader, new FileOutputStream("HelloWorld-modified.pdf")); Image image = Image.getInstance("temp.jpg"); image.scaleAbsolute(100, 50); image.setAbsolutePosition(100f, 700f); for(int i=1; i<= pdfReader.getNumberOfPages(); i++) < PdfContentByte content = pdfStamper.getUnderContent(i); content.addImage(image); >pdfStamper.close(); > catch (IOException e) < e.printStackTrace(); >catch (DocumentException e) < e.printStackTrace(); >>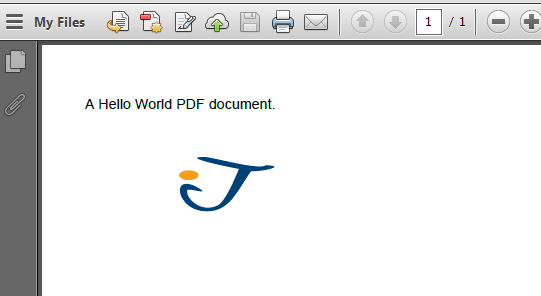
12. Writing PDF to HttpOutputStream
This is the last example in the list, and in this example, I am writing the content of created PDF file into the output stream attached to the HttpServletResponse object. This will be needed when you stream the PDF file in a client-server environment.
Document document = new Document(); try< response.setContentType("application/pdf"); PdfWriter.getInstance(document, response.getOutputStream()); document.open(); document.add(new Paragraph("howtodoinjava.com")); document.add(new Paragraph(new Date().toString())); //Add more content here >catch(Exception e) < e.printStackTrace(); >document.close(); >That’s all for the iText example codes. Leave a comment if something is unclear to you, OR you would like to add any other example to this list.