- Сравнение Lock-free алгоритмов — CAS и FAA на примере JDK 7 и 8
- Compare-and-Swap
- Fetch-and-Add
- Что бы я еще хотел бы добавить.
- Тесты
- Saved searches
- Use saved searches to filter your results more quickly
- License
- byronlai/lock-free-data-structures
- Name already in use
- Sign In Required
- Launching GitHub Desktop
- Launching GitHub Desktop
- Launching Xcode
- Launching Visual Studio Code
- Latest commit
- Git stats
- Files
- README.md
- Lock Free Stack using Java
Сравнение Lock-free алгоритмов — CAS и FAA на примере JDK 7 и 8
Атомарные операции (atomics), например, Compare-and-Swap (CAS) или Fetch-and-Add (FAA) широко распространены в параллельном программировании.
Мульти- или многоядерные архитектуры установлены одинаково как в продуктах настольных и серверных компьютеров, так и в крупных центрах обработки данных и суперкомпьютерах. Примеры конструкций включают Intel Xeon Phi с 61 ядрами на чипе, который установлен в Tianhe-2, или AMD Bulldozer с 32 ядрами на узле, развернутых в Cray XE6. Кроме того, количество ядер на кристалле неуклонно растет и процессоры с сотнями ядер, по прогнозам, будут изготовлены в обозримом будущем. Общей чертой всех этих архитектур является растущая сложность подсистем памяти, характеризующаяся несколькими уровнями кэш-памяти с разными политиками включения, различными протоколами когерентности кэш-памяти, а также различными сетевыми топологиями на чипе, соединяющими ядра и кэш-память.
Практически все такие архитектуры обеспечивают атомарные операции, которые имеют многочисленные применения в параллельном коде. Многие из них (например, Test-and-Set) могут быть использованы для реализации блокировок и других механизмов синхронизации. Другие, например, Fetch-and-Add и Compare-and-Swap позволяют строить разные lock-free и wait-free алгоритмы и структуры данных, которые имеют более прочные гарантии прогресса, чем блокировки на основе кода. Несмотря на их важность и повсеместное употребление, выполнение атомарных операций полностью не проанализировано до сих пор. Например, по общему мнению, Compare-and-Swap идет медленнее, чем Fetch-and-Add. Тем не менее, это всего лишь показывает, что семантика Compare-and-Swap вводит понятие «wasted work», в результате – более низкая производительность некоторого кода.
Compare-and-Swap
Вспомним, что из себя представляет CAS (в процессорах Intel он осуществляется группой команд cmpxchg) – Операция CAS включает 3 объекта-операнда: адрес ячейки памяти (V), ожидаемое старое значение (A) и новое значение (B). Процессор атомарно обновляет адрес ячейки (V), если значение в ячейке памяти совпадает со старым ожидаемым значением(A), иначе изменения не зафиксируется. В любом случае, будет выведена величина, которая предшествовала времени запроса. Некоторые варианты метода CAS просто сообщают, успешно ли прошла операция, вместо того, чтобы отобразить само текущее значение. Фактически, CAS только сообщает: «Наверное, значение по адресу V равняется A; если так оно и есть, поместите туда же B, в противном случае не делайте этого, но обязательно скажите мне, какая величина — текущая.»
Самым естественным методом использования CAS для синхронизации будет чтение значения A со значением адреса V, проделать многошаговое вычисление для получения нового значения B, и затем воспользоваться методом CAS для замены значения параметра V с прежнего, A, на новое, B. CAS выполнит задание, если V за это время не менялось. Что, собственно говоря, наблюдается в JDK 7:
public final int incrementAndGet() < for (;;) < int current = get(); int next = current + 1; if (compareAndSet(current, next)) return next; >> public final boolean compareAndSet(int expect, int update)
Где сам метод — unsafe.compareAndSwapInt является native, выполняется на процессоре атомарно и на ассемблере выглядит следующим образом, если включить распечатку ассемблерного кода:
Инструкция выполняется следующим образом: читается значение из области памяти, указанное первым операндом и блокировка шины после чтения не снимается. Затем происходит сравнение значения по адресу памяти с регистром eax, где хранится ожидаемое старое значение, и если они были равны, то процессор записывает значение второго операнда (регистр ecx) в область памяти, указанную первым операндом. По завершении записи блокировка шины снимается. Особенности x86 в этом, что запись происходит в любом случае, за тем небольшим исключением, что если значения были не равны, то в область памяти заносится значение, которое было получено на этапе чтения из этой же области памяти.
Таким образом мы получаем работу в цикле с проверкой переменной, причем которая может окончиться неудачей и всю работу в цикле до проверки необходимо начинать заново.
Fetch-and-Add
Fetch-and-Add работает проще и не содержит никаких циклов (в архитектуре Intel осуществляется группой команд xadd). Также он включает 2 объекта-операнда: адрес ячейки памяти (V) и значение (S), на которое следует увеличить старое значение, хранимое по адресу памяти (V). Так, FAA можно описать в таком виде: получить значение, располагаемое по указанному адресу (V) и сохранить его временно. Затем в указанный адрес (V) занести сохраненное ранее значение, увеличенное на значение, которое из себя представляет 2 объект-операнд (S). Причем, все указанные выше операции выполняются атомарно и реализованы на аппаратном уровне.
public final int incrementAndGet() < return unsafe.getAndAddInt(this, valueOffset, 1) + 1; >public final int getAndAddInt(Object var1, long var2, int var4) < int var5; do < var5 = this.getIntVolatile(var1, var2); >while(!this.compareAndSwapInt(var1, var2, var5, var5 + var4)); return var5; > «Ноо, — скажете Вы, — чем данная реализация отличается от 7 версии»?
Тут приблизительно такой же цикл и все выполняется схожим образом. Однако, тот код, который вы видите и написан на Java не выполняется в конечном итоге на процессоре. Тот код, который связан с циклом и установкой нового значения заменяется в конечном итоге на одну операцию ассемблера:
Где, соответственно, в регистре eax хранится значение, на которое нужно будет увеличить старое значение, хранимое по адресу [esi+0xC]. Повторюсь, все выполняется атомарно. Но такой фокус сработает, если у Вас 8 версия JDK, иначе выполнится обычный CAS.
Что бы я еще хотел бы добавить.
Хочу тут отметить, что здесь упоминается протокол MESI, о котором можно почитать в очень хорошем цикле статей: Lock-free структуры данных. Основы: откуда пошли быть барьеры памяти.
Спасибо kmu1990 за уточнение перевода с англ.
- CAS является «оптимистичным» алгоритмом и допускает невыполнение операции, в то время как FAA нет. У FAA нет явной лазейки в виде уязвимости из-за удаленного вмешательства, следовательно, нет необходимости в цикле для повторных попыток.
Тесты
Ну и напоследок я написал простенький тест, который иллюстрирует работу атомарного инкрементирования в JDK 7 и 8:
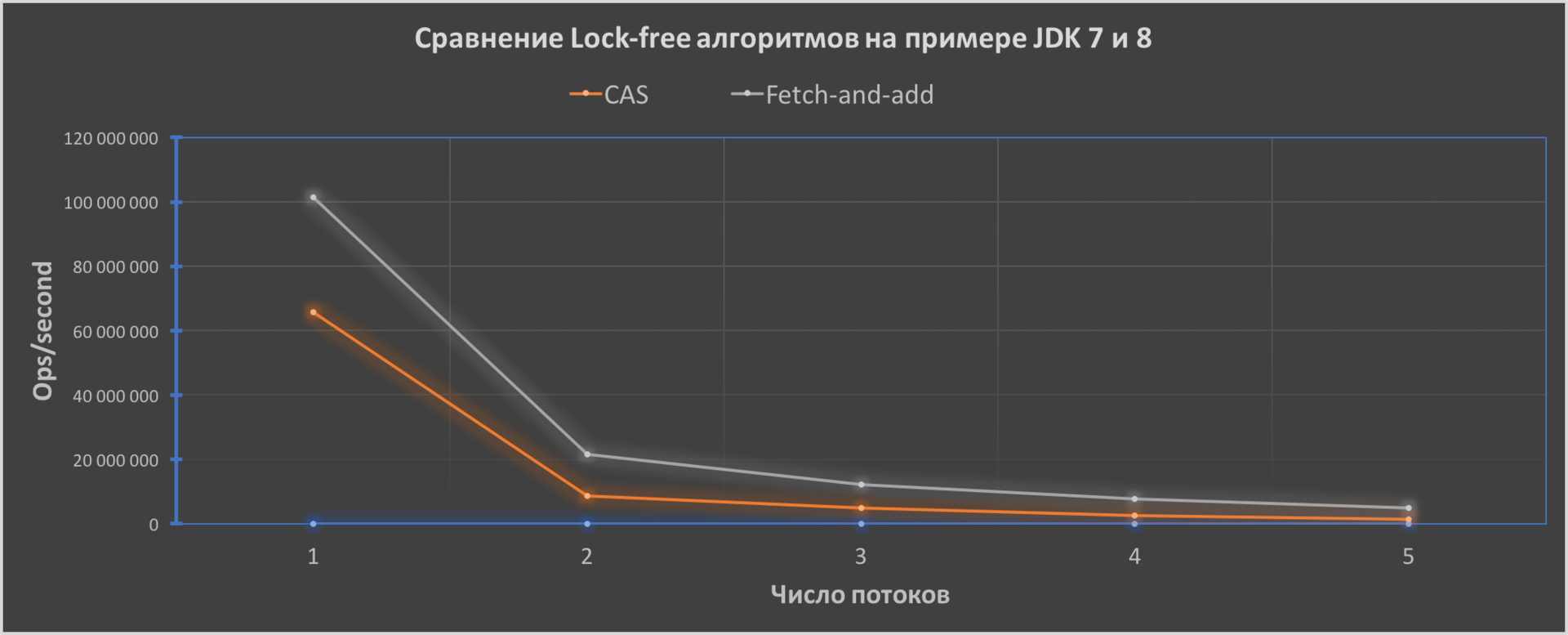
Как мы видим, производительность кода у FAA будет лучше и его эффективность увеличивается с увеличением числа потоков от 1.6 раза до приблизительно 3.4 раза.

Версии Java для тестов: Oracle JDK7u80 и JDK8u111 — 64-Bit Server VM. CPU — Intel Core i5-5250U поколения Broadwell, OS — macOS Sierra 10.12.2, RAM — 8-Gb.
Ну и если интересно, ссылка на код теста — исходники теста.
Жду замечаний, улучшений и прочее.
Saved searches
Use saved searches to filter your results more quickly
You signed in with another tab or window. Reload to refresh your session. You signed out in another tab or window. Reload to refresh your session. You switched accounts on another tab or window. Reload to refresh your session.
Lock-free (Non-blocking) Data Structures in Java
License
byronlai/lock-free-data-structures
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
Name already in use
A tag already exists with the provided branch name. Many Git commands accept both tag and branch names, so creating this branch may cause unexpected behavior. Are you sure you want to create this branch?
Sign In Required
Please sign in to use Codespaces.
Launching GitHub Desktop
If nothing happens, download GitHub Desktop and try again.
Launching GitHub Desktop
If nothing happens, download GitHub Desktop and try again.
Launching Xcode
If nothing happens, download Xcode and try again.
Launching Visual Studio Code
Your codespace will open once ready.
There was a problem preparing your codespace, please try again.
Latest commit
Git stats
Files
Failed to load latest commit information.
README.md
Lock-free Data Structures in Java
Lock-free (non-blocking) stack and linked list implemented using compare and swap in Java. Lock-free data structures allow concurrent access to the structure without the use of mutex, semaphores or other kinds of thread synchronization. Lock free data structures allow higher level of concurrency because threads are not blocked.
For more information, check out my article at IBM developerWorks.
- push(T value) Push the given element to the stack
- peek() Return the top element in the stack
- pop() Remove the top element in the stack
- addFirst(T value) Prepend the element to the linked list
- addAfter(T value) Append the element to the linked list
- remove(T value) Remove the element in the linked list
Lock Free Stack using Java
In a multi-threaded environment, the lock-free algorithms provide a way in which threads can access the shared resources without the complexity of Locks and without blocking the threads forever. These algorithms become a programmer’s choice as they provide higher throughput and prevent deadlocks.
This is mainly because designing lock-based algorithms, for concurrency brings its own challenges on the table. The complexity of writing efficient locks and synchronization to reduce thread contention is not everyone’s cup of tea. And besides, even after writing the complex code, many times, hard-to-find bugs occur in the production environments, where multiple threads are involved, which becomes even more difficult to resolve.
Keeping this perspective, we will be talking about how we can apply a lock-free algorithm to one of the widely used data structures in Java, called the Stack. As we know Stack is used in many real-life applications like Undo/redo functions in a Word processor, Expression evaluation and syntax parsing, in Language Processing, in supporting recursions and also our own JVM is Stack oriented. So, let’s have some insight into how to write a lock-free stack. Hope it ignites your mind enough to read and gain knowledge on this topic, further.
Atomic Classes in Java
Java provides a plethora of classes that support lock-free and thread-safe programming. The Atomic API provided by Java, java.util.concurrent.atomic package contains many advanced classes and features which provide concurrency control without having to use locks. The AtomicReference is also one such class in the API which provides a reference to the underlying object references that can be read and written atomically. By atomic, we mean the reads from and writes to these variables are thread-safe. Please refer to the below link for details.
CAS Inside – CompareAndSwap Operation:
The most important operation which is the basic building block for the lock-free algorithms is the compare and swap. It compiles into a single hardware operation, which makes it faster as the synchronization appears on a granular level. Also, this operation is available in all the Atomic Classes. CAS aims at updating the value of a variable/reference by comparing it with its current value.
Applying CAS for a Non-Blocking Stack:
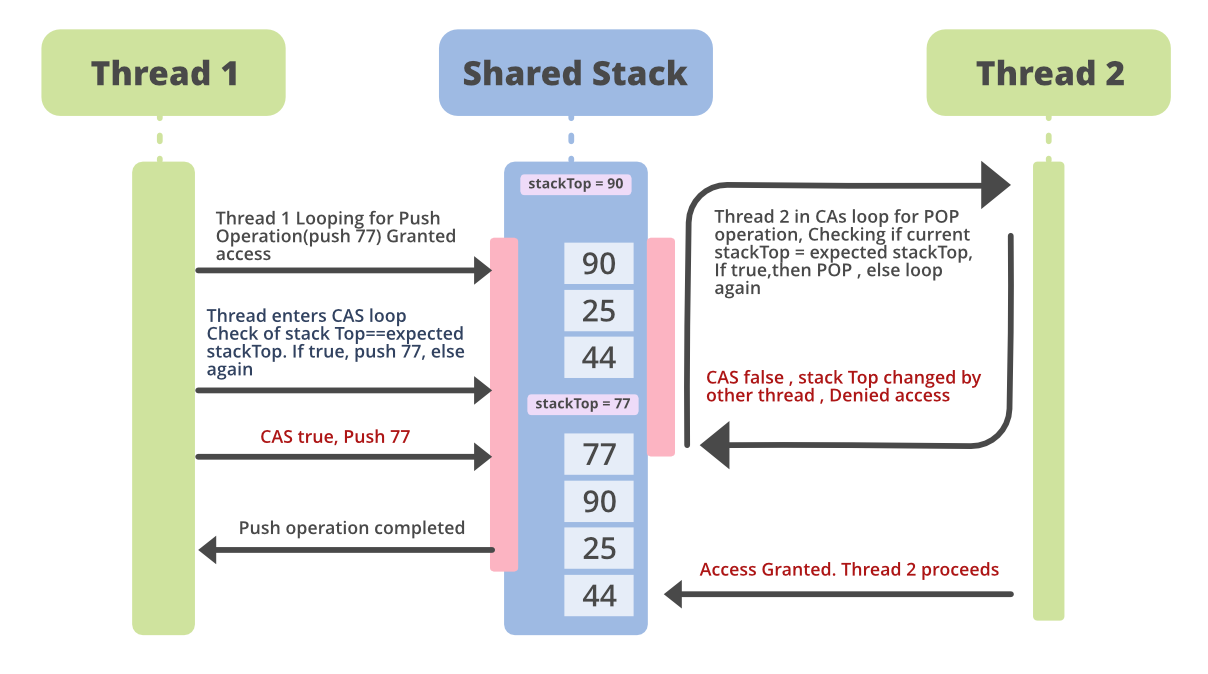
A non-blocking stack basically means that the operations of the stack are available for all the threads and no thread is blocked. To use CAS in the stack operations, a loop is written wherein the value of the top node (called stack top) of the stack is checked using CAS. If the value of stackTop is as expected, it is replaced with the new top value, else nothing is changed and the thread goes into the loop again.
Let’s say we have an Integer Stack. Suppose, thread1 wants to push a value 77 on to the stack when the top of the stack value is 90. And thread2 wants to pop the top of the stack which is 90, currently. If thread1 tries to access the Stack and is granted access because no other thread is accessing it at that time, then the thread first gets the latest value of stack top. Then it enters the CAS loop and checks the stack top with the expected value (90). If the two values are the same, ie: CAS returned true, which means no other thread has modified it, the new value (77 in our case) is pushed on to the stack. And 77 becomes the new stack top. Meanwhile, thread2 keeps looping the CAS, until CAS returns true, for popping an item from the top of the stack. This is pictured below in the diagram.
Code Example for the Non-Blocking Stack :
The Stack code sample is shown below. In this example, there are two stacks defined. One which uses traditional synchronization(named ClassicStack here) to achieve concurrency control. The other stack uses the compare-and-set operation of AtomicReference class for establishing a lock-free algorithm(named as LockFreeStack here). Here we are counting the number of operations performed by the Stack in a span of 1/2 a second. We compare the performance of the two stacks below :