@OneToOne
Есть еще один интересный и довольно специфический случай отношений между двумя Entity-классами – это отношение один-к-одному.
Я называю этот случай очень специфическим, так как это больше о Java-объектах, чем о базе данных. В базе данных есть всего два варианта связи между таблицами:
- Строка таблицы содержит ссылку на id другой таблицы.
- Служебная таблица используется для связи many-to-many.
В случае же с Entity-классами могут быть варианты, которые описываются несколькими аннотациями:
Ниже мы рассмотрим самые популярные из них.
5.2 @Embedded
Самый простой вариант связи one-to-one мы, кстати, уже рассмотрели – это аннотация @Embedded . В этом случае у нас два класса хранятся в одной таблице в базе.
Допустим, мы хотим хранить адрес пользователя в классе UserAddress:
@Embeddable class UserAddress < @Column(name="user_address_country") public String country; @Column(name="user_address_city") public String city; @Column(name="user_address_street") public String street; @Column(name="user_address_home") public String home; > Тогда нам нужно просто добавить поле с этим адресом в класс User:
@Entity @Table(name="user") class User < @Column(name="id") public Integer id; @Embedded public UserAddress address; @Column(name="created_date") public Date createdDate; > Все остальное сделает Hibernate: данные будут храниться в одной таблице, но при написании HQL-запросов тебе нужно будет оперировать именно полями классов.
select from User where address.city = 'Paris' 5.3 Односторонний OneToOne
Представим теперь ситуацию: у нас есть исходная таблица employee и task, который ссылается на employee. Но мы точно знаем, что на одного пользователя может быть назначена максимум одна задача. Тогда для описания этой ситуации мы можем воспользоваться аннотацией @OneToOne .
@Entity @Table(name="task") class EmployeeTask < @Column(name="id") public Integer id; @Column(name="name") public String description; @OneToOne @JoinColumn(name = "employee_id") public Employee employee; @Column(name="deadline") public Date deadline; > Hibernate будет следить за тем, чтобы не только у одной задачи был один пользователь, но и чтобы у одного пользователя была только одна задача. В остальном этот случай практически ничем не отличается от @ManyToOne .
5.4 Двусторонний OneToOne
Предыдущий вариант может быть немного неудобным, так как часто хочется не просто задаче присвоить сотрудника, но и сотруднику назначить задачу.
Для этого можно добавить поле EmployeeTask в класс Employee и выставить ему правильные аннотации.
@Entity @Table(name="employee") class Employee < @Column(name="id") public Integer id; @OneToOne(cascade = CascadeType.ALL, mappedBy="employee") private EmployeeTask task; > Важно! У таблицы employee нет поля task_id, вместо этого для установления связи между таблицами используется поле employee_id таблицы task.
Установление связи между объектами выглядит так:
Employee director = session.find(Employee.class, 4); EmployeeTask task = session.find(EmployeeTask.class, 101); task.employee = director; director.task = task; session.update(task); session.flush(); Для удаления связи ссылки тоже нужно удалить у обоих объектов:
Employee director = session.find(Employee.class, 4); EmployeeTask task = director.task; task.employee = null; session.update(task); director.task = null; session.update(director); session.flush(); Отношение OneToOne в Hibernate и Spring
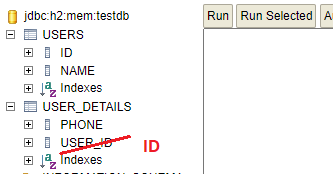
Что создает в таблице USER_DETAILS внешний ключ USER_ID, указывающий на ID в таблице USER:
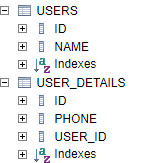
При этом класс User тоже может ссылаться на UserDetails (или не ссылаться, на схему это не влияет).
insert into users (id, name) values (1,'Ivan'); insert into users (id, name) values (2, 'John'); insert into users (id, name) values (3, 'Petr'); insert into user_details (id, phone, user_id) values (4, '154623', 1); insert into user_details (id, phone, user_id) values (5, '435', 2); insert into user_details (id, phone, user_id) values (6, '3454', 3);
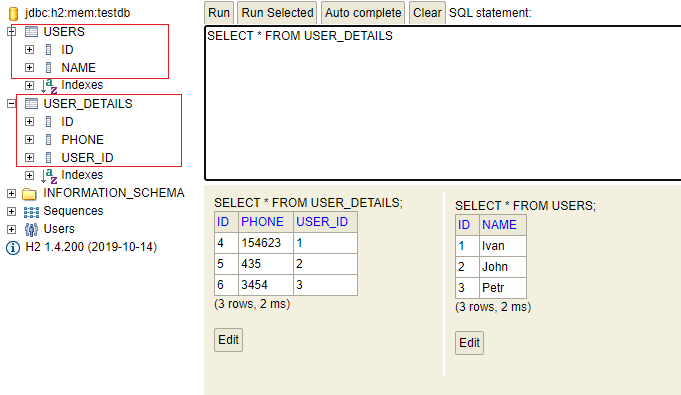
Недостатки
- лишний столбец
- если User тоже в свою очередь ссылается на UserDetails, то его настройка fetch = FetchType.LAZY не работает. То есть при поиске пользователя генерируется не один, а два SQL оператора:
@DataJpaTest class UserRepositoryTest < @Autowired private UserRepository userRepository; @Test @DisplayName("ищет user EAGER") public void whenFindUser_ThenEager() < OptionaloptionalUser = userRepository.findById(1l); Assertions.assertTrue(optionalUser.isPresent()); > > генерирует два SQL оператора:
select user0_.id as id1_1_0_, user0_.name as name2_1_0_ from users user0_ where user0_.id=? select userdetail0_.id as id1_0_0_, userdetail0_.phone as phone2_0_0_, userdetail0_.user_id as user_id3_0_0_ from user_details userdetail0_ where userdetail0_.user_id=?
Лучший способ
Во-первых, можно убрать из схемы лишний столбец. Если у каждого UserDetails свой ровно один User, то зачем в таблице USER_DETAILS нужен автогенерируемый первичный ключ? Достаточно одного USER_ID — пусть он будет и первичный, и внешний:
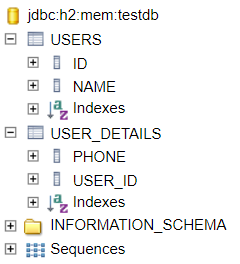
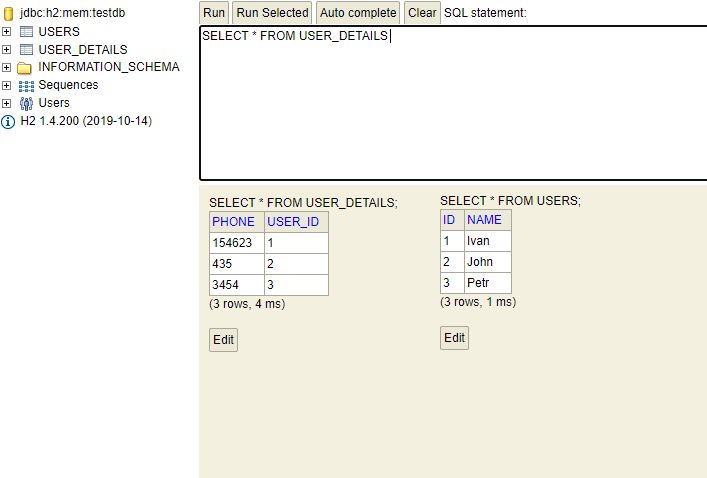
Чтобы создать такую схему, надо в UserDetails аннотировать поле user аннотацией @MapsId:
@Entity public class UserDetails
Также у поля id выше в убрана аннотация @GeneratedValue. Теперь id не генерируется автоматически, а заполняется идентификатором User.
Помимо более чистой структуры БД, для поля userDetails сущности User начинает работать FetchType.LAZY, то есть при поиске User по id уже выполняется один select, а не два.
Но все же из User лучше обратную ссылку убрать:
Заполним новую схему данными:
insert into users (id, name) values (1,'Ivan'); insert into users (id, name) values (2, 'John'); insert into users (id, name) values (3, 'Petr'); insert into user_details (phone, user_id) values ('154623', 1); insert into user_details (phone, user_id) values ('435', 2); insert into user_details (phone, user_id) values ('3454', 3); Выполним тот же тест, и получим один оператор select:
select user0_.id as id1_1_0_, user0_.name as name2_1_0_ from users user0_ where user0_.id=?
Зная идентификатор User, всегда можно извлечь UserDetails по такому же идентификатору. И уж тогда получить второй select.
Переименование внешнего/первичного ключа
Чтобы сменить название внешнего ключа (который по сути является первичным) в таблице user_details с user_id на id, нужно использовать аннотацию @JoinColumn:
@MapsId @JoinColumn(name = "id") private User user;
Итоги
Таким образом, второй вариант с @MapsId предпочтительней: лучше совместить внешний и первичный ключ, а также делать одностороннее отношение (без обратного поля с mappedBy). Это оптимально для производительности.
Есть также вариант сопоставить 1:1 с помощью @SecondaryTable.
Отношение OneToOne в Hibernate и Spring: 9 комментариев
Так этот проект использует Hibernate или это чистое JPA?
Просто я в файле pom.xml не вижу ни одной подключенной библиотеки Hibernate. Типа зависимости hibernate-core.
Так же нет hibernate.cfg.xml файла, где прописаны настройки Hibernate.
Или они не обязательны?
Можете немного просвятить в этом вопросе.
Это Spring Boot, тут есть зависимость spring-boot-starter-data-jpa, и в список ее зависимостей как раз и входит hibernate. Файл hibernate.cfg.xml тут не нужен, настройки переходят в application.yml (специфика Spring Boot).
При сохранении нового объекта UserDetails через JpaRepository методом save() выполняется два insert: insert into users, затем insert into user_details. Как избавиться от первого insert?
Т.к. объект User уже до этого был сохранен в БД возникает ошибка уникальности «duplicate key value violates unique constraint»
Все правильно, что выполняется два insert, отношение же OneToOne, так и должно быть.
Проблема в другом — в data.sql уже добавлены три пользователя с (их мы выбираем в примере). А в классе User стоит @GeneratedValue(strategy = GenerationType.SEQUENCE) без уточнений, это означает, что создается последовательность hibernate_sequence с начальным значением 1, и с помощью нее генерируются новые id. Поэтому при первом же добавлении генерируется и возникает ошибка. Исправить это просто. Либо уточнить параметры генератора, сделать начальное значение как минимум с 4:
@Id
@GeneratedValue(strategy = GenerationType.SEQUENCE, generator = «users_id_seq-generator»)
@SequenceGenerator(name = «users_id_seq-generator», sequenceName= «users_id_seq»,
initialValue = 4, allocationSize = 10)
private long id;
Либо делать @GeneratedValue(strategy = GenerationType.IDENTITY) — так id будет генерироваться без использования sequence. Это будет просто автоинкрементный столбец, где новое значение генерируется в зависимости от предыдущего. Такой вариант и отправлен сейчас в репозиторий вместе с примером сохранения user, спасибо за замечание.
Если по логике объект User может существовать и без UserDetails, то каким образом нужно сохранить новый объект UserDetails чтобы не возникало ошибки(из-за первого insert)?
Так User без UserDetails вроде можно сохранить:
User user=new User();
user.setName(«Jane»);
userRepository.save(user); А вот UserDetails без User сохранить нельзя, используя @MapsId, потому что с ним такая структура в базе генерируется: первичный ключ в UserDetails (он же является внешним) берется из первичного ключа User. Нет User — нет UserDetails. Если все же надо сохранять UserDetails без User, то @MapsId не надо использовать.
Это все понятно, я все пытаюсь объяснить проблему когда User уже сохранен в БД и его больше не нужно сохранять.
User user = userRepo.getById(4L);
UserDetails ud = new UserDetails();
ud.setUser(user);
userDetailsRepo.save(ud) // тут ошибка
выполняя первый insert он пытается сохранить нового User, но он уже есть в БД с id 4. Цель — сохраняя UserDetails сохранить только его и не трогать таблицу с User. Есть идеи?
У меня такой тест срабатывает (при условии что userdetails c правда нет, то есть если из data.sql убрать строку insert into user_details (phone, id) values (‘3454’, 3);):
@Test
@Commit
public void shouldSaveUserDetailsWhenUserExists() User user = userRepository.getOne(3l);
UserDetails ud = new UserDetails();
ud.setPhone(«123»);
ud.setUser(user);
userDetailsRepository.save(ud);
>
Если мы убираем аннотацию @OneToOne на сущности User, то пропадает возможность воспользоваться cascade, нужного, например, для удаления удаления User. Значит, нужно в методе удаления юзера сначала проверять, существуют ли для него userdetails, затем удалять их и только после этого удалять юзера. В итоге мы получаем, достаточно длинный sql..
Или же есть другие варианты?
Добавить комментарий Отменить ответ
Прошу прощения: на комментарии временно не отвечаю.