Java Best Practices – Char to Byte and Byte to Char conversions
Char to Byte and Byte to Char conversions
Character to byte and byte to character conversions are considered common tasks among Java developers who are programming against a networking environment, manipulate streams of byte data, serialize String objects, implementing communication protocols etc. For that reason Java provides a handful of utilities that enable a developer to convert a String (or a character array) to its byte array equivalent and vice versa.
The “getBytes(charsetName)” operation of the String class is probably the most commonly used method for converting a String into its byte array equivalent. Since every character can be represented differently according to the encoding scheme used, its of no surprise that the aforementioned operation requires a “charsetName” in order to correctly convert the String characters. If no “charsetName” is provided, the operation encodes the String into a sequence of bytes using the platform’s default character set.
Another “classic” approach for converting a character array to its byte array equivalent is by using the ByteBuffer class of the NIO package. An example code snippet for the specific approach will be provided later on.
Both the aforementioned approaches although very popular and indisputably easy to use and straightforward greatly lack in performance compared to more fine grained methods. Keep in mind that we are not converting between character encodings. For converting between character encodings you should stick with the “classic” approaches using either the “String.getBytes(charsetName)” or the NIO framework methods and utilities.
When all characters to be converted are ASCII characters, a proposed conversion method is the one shown below :
public static byte[] stringToBytesASCII(String str) < char[] buffer = str.toCharArray(); byte[] b = new byte[buffer.length]; for (int i = 0; i < b.length; i++) < b[i] = (byte) buffer[i]; >return b; >
The resulted byte array is constructed by casting every character value to its byte equivalent since we know that all characters are in the ASCII range (0 – 127) thus can occupy just one byte in size.
Using the resulted byte array we can convert back to the original String, by utilizing the “classic” String constructor “new String(byte[])”
For the default character encoding we can use the methods shown below to convert a String to a byte array and vice – versa :
public static byte[] stringToBytesUTFCustom(String str) < char[] buffer = str.toCharArray(); byte[] b = new byte[buffer.length >8); b[bpos + 1] = (byte) (buffer[i]&0x00FF); > return b; >
Every character type in Java occupies 2 bytes in size. For converting a String to its byte array equivalent we convert every character of the String to its 2 byte representation.
Using the resulted byte array we can convert back to the original String, by utilizing the method provided below :
public static String bytesToStringUTFCustom(byte[] bytes) < char[] buffer = new char[bytes.length >> 1]; for(int i = 0; i < buffer.length; i++) < int bpos = i return new String(buffer); >
We construct every String character from its 2 byte representation. Using the resulted character array we can convert back to the original String, by utilizing the “classic” String constructor “new String(char[])”
Last but not least we provide two example methods using the NIO package in order to convert a String to its byte array equivalent and vice – versa :
public static byte[] stringToBytesUTFNIO(String str)
public static String bytesToStringUTFNIO(byte[] bytes)
For the final part of this article we provide the performance comparison charts for the aforementioned String to byte array and byte array to String conversion approaches. We have tested all methods using the input string “a test string”.
First the String to byte array conversion performance comparison chart :

The horizontal axis represents the number of test runs and the vertical axis the average transactions per second (TPS) for each test run. Thus higher values are better. As expected, both “String.getBytes()” and “stringToBytesUTFNIO(String)” approaches performed poorly compared to the “stringToBytesASCII(String)” and “stringToBytesUTFCustom(String)” suggested approaches. As you can see, our proposed methods achieve almost 30% increase in TPS compared to the “classic” methods.
Lastly the byte array to String performance comparison chart :
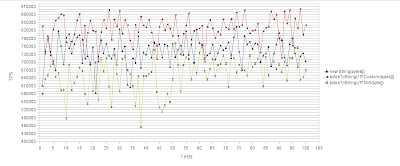
The horizontal axis represents the number of test runs and the vertical axis the average transactions per second (TPS) for each test run. Thus higher values are better. As expected, both “new String(byte[])” and “bytesToStringUTFNIO(byte[])” approaches performed poorly compared to the “bytesToStringUTFCustom(byte[])” suggested approach. As you can see, our proposed method achieved almost 15% increase in TPS compared to the “new String(byte[])” method, and almost 30% increase in TPS compared to the “bytesToStringUTFNIO(byte[])” method.
In conclusion, when you are dealing with character to byte or byte to character conversions and you do not intent to change the encoding used, you can achieve superior performance by utilizing custom – fine grained – methods rather than using the “classic” ones provided by the String class and the NIO package. Our proposed approach achieved an overall of 45% increase in performance compared to the “classic” approaches when converting the test String to its byte array equivalent and vice – versa.
After taking into consideration the proposition from several of our readers to utilize the “String.charAt(int)” operation instead of using the “String.toCharArray()” so as to convert the String characters into bytes, I altered our proposed methods and re-executed the tests. As expected, further performance gains where achieved. In particular, an extra 13% average increase in TPS was recorded for the “stringToBytesASCII(String)” method and an extra 2% average increase in TPS was recorded for the “stringToBytesUTFCustom(String)”. So you should use the altered methods as they perform even better than the original ones. The updated methods are shown below :
public static byte[] stringToBytesASCII(String str) < byte[] b = new byte[str.length()]; for (int i = 0; i < b.length; i++) < b[i] = (byte) str.charAt(i); >return b; >
public static byte[] stringToBytesUTFCustom(String str) < byte[] b = new byte[str.length() >8); b[bpos + 1] = (byte) (strChar&0x00FF); > return b; >
[Перевод] Java Best Practices. Преобразование Char в Byte и обратно
Сайт Java Code Geeks изредка публикует посты в серии Java Best Practices — проверенные на production решения. Получив разрешение от автора, перевёл один из постов. Дальше — больше.
Продолжая серию статей о некоторых аспектах программирования на Java, мы коснёмся сегодня производительности String, особенно момент преобразования character в байт-последовательность и обратно в том случае, когда используется кодировка по умолчанию. В заключение мы приложим сравнение производительности между неклассическими и классическими подходами для преобразования символов в байт-последовательность и обратно.
Все изыскания базируются на проблемах в разработке крайне эффективных систем для задач в области телекоммуникации (ultra high performance production systems for the telecommunication industry).
Перед каждой из частей статьи очень рекомендуем ознакомиться с Java API для дополнительной информации и примеров кода.
Эксперименты проводились на Sony Vaio со следующими характеристиками:
ОС: openSUSE 11.1 (x86_64)
Процессор (CPU): Intel® Core(TM)2 Duo CPU T6670 @ 2.20GHz
Частота: 1,200.00 MHz
ОЗУ (RAM): 2.8 GB
Java: OpenJDK 1.6.0_0 64-Bit
Со следующими параметрами:
Одновременно тредов: 1
Количество итераций эксперимента: 1000000
Всего тестов: 100
Преобразование Char в Byte и обратно:
Задача преобразования Char в Byte и обратно широко распространена в области коммуникаций, где программист обязан обрабатывать байтовые последовательности, сериализовать String-и, реализовывать протоколы и т.д.
Для этого в Java существует набор инструментов.
Метод «getBytes(charsetName)» класса String, наверное, один из популярнейших инструментов для преобразования String в его байтовый эквивалент. Параметр charsetName указывает на кодировку String, в случае отсутствия оного метод кодирует String в последовательность байт используя стоящую в ОС по умолчанию кодировку.
Ещё одним классическим подходом к преобразованию массива символов в его байтовый эквивалент является использование класса ByteBuffer из пакета NIO (New Input Output).
Оба подхода популярны и, безусловно, достаточно просты в использовании, однако испытывают серьёзные проблемы с производительностью по сравнению с более специфическими методами. Помните: мы не конвертируем из одной кодировки в другую, для этого вы должны придерживаться «классических» подходов с использованием либо «String.getBytes (charsetName)» либо возможностей пакета NIO.
В случае ASCII мы имеем следующий код:
public static byte[] stringToBytesASCII(String str) < char[] buffer = str.toCharArray(); byte[] b = new byte[buffer.length]; for (int i = 0; i < b.length; i++) < b[i] = (byte) buffer[i]; >return b; > Массив b создаётся путём кастинга (casting) значения каждого символа в его байтовый эквивалент, при этом учитывая ASCII-диапазон (0-127) символов, каждый из которых занимает один байт.
Массив b можно преобразовать обратно в строку с помощью конструктора «new String(byte[])»:
System.out.println(new String(stringToBytesASCII("test"))); Для кодировки по умолчанию мы можем использовать следующий код:
public static byte[] stringToBytesUTFCustom(String str) < char[] buffer = str.toCharArray(); byte[] b = new byte[buffer.length >8); b[bpos + 1] = (byte) (buffer[i]&0x00FF); > return b; > Каждый символ в Java занимает 2 байта, для преобразования строки в байтовый эквивалент нужно перевести каждый символ строки в его двухбайтовый эквивалент.
public static String bytesToStringUTFCustom(byte[] bytes) < char[] buffer = new char[bytes.length >> 1]; for(int i = 0; i < buffer.length; i++) < int bpos = i return new String(buffer); > Мы восстанавливаем каждый символ строки из его двухбайтового эквивалента и затем, опять же с помощью конструктора String(char[]), создаём новый объект.
Примеры использования возможностей пакета NIO для наших задач:
public static byte[] stringToBytesUTFNIO(String str) < char[] buffer = str.toCharArray(); byte[] b = new byte[buffer.length public static String bytesToStringUTFNIO(byte[] bytes)
А теперь, как и обещали, графики.
String в byte array:
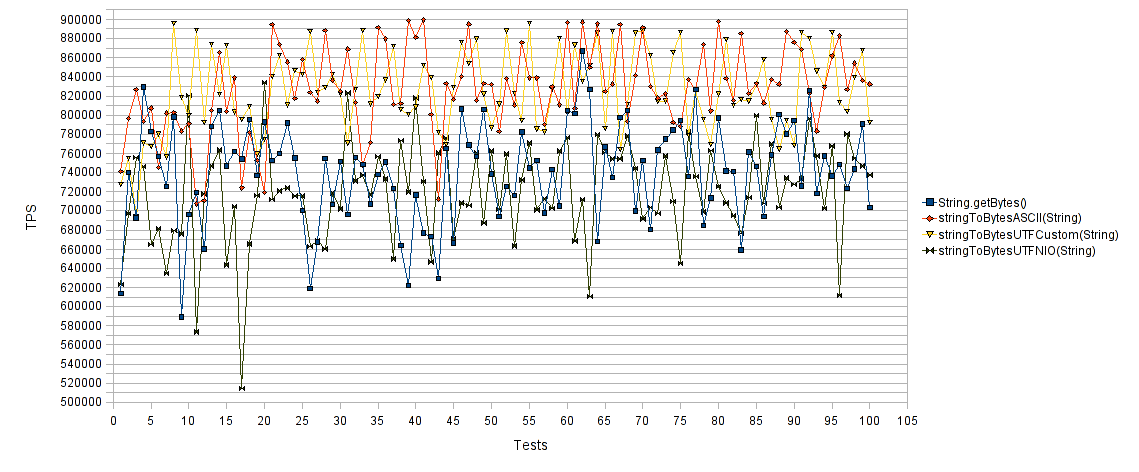
Ось абсцисс — количество тестов, ординат — количество операций в секунду для каждого теста. Что выше — то быстрее. Как и ожидалось, «String.getBytes()» и «stringToBytesUTFNIO(String)» отработали куда хуже «stringToBytesASCII(String)» и «stringToBytesUTFCustom(String)». Наши реализации, как можно увидеть, добились почти 30% увеличения количества операций в секунду.
Byte array в String:
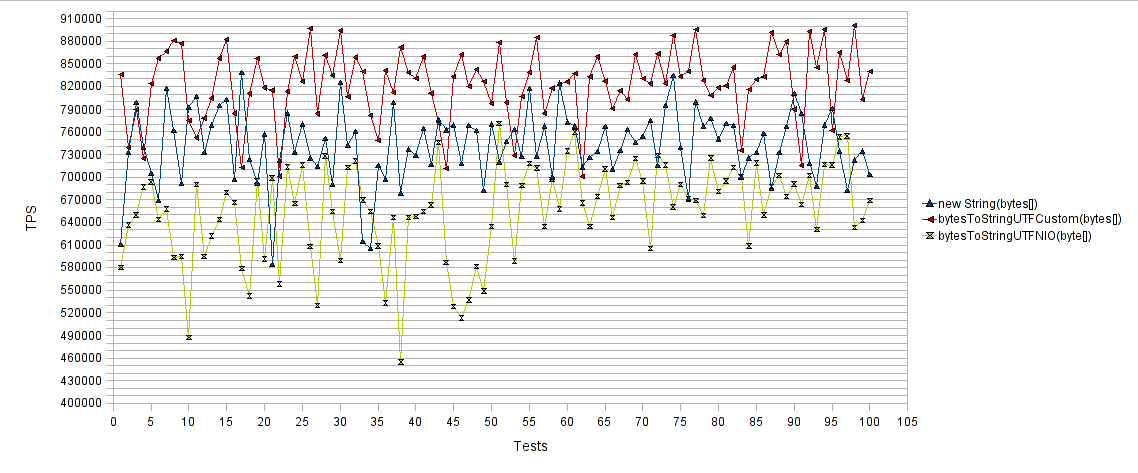
Результаты опять же радуют. Наши собственные методы добились 15% увеличения количества операций в секунду по сравнению с «new String(byte[])» и 30% увеличения количества операций в секунду по сравнению с «bytesToStringUTFNIO(byte[])».
В качестве вывода: в том случае, если вам необходимо преобразовать байтовую последовательность в строку или обратно, при этом не требуется менять кодировки, вы можете получить замечательный выигрыш в производительности с помощью самописных методов. В итоге, наши методы добились в общем 45% ускорения по сравнению с классическими подходами.