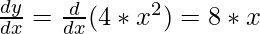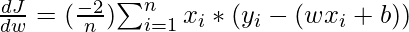What is gradient descent ?
It is an optimization algorithm to find the minimum of a function. We start with a random point on the function and move in the negative direction of the gradient of the function to reach the local/global minima.
Example by hand :
Question : Find the local minima of the function y=(x+5)² starting from the point x=3
Solution : We know the answer just by looking at the graph. y = (x+5)² reaches it’s minimum value when x = -5 (i.e when x=-5, y=0). Hence x=-5 is the local and global minima of the function.
Now, let’s see how to obtain the same numerically using gradient descent.
Step 1 : Initialize x =3. Then, find the gradient of the function, dy/dx = 2*(x+5).
Step 2 : Move in the direction of the negative of the gradient (Why?). But wait, how much to move? For that, we require a learning rate. Let us assume the learning rate → 0.01
Step 3 : Let’s perform 2 iterations of gradient descent
Step 4 : We can observe that the X value is slowly decreasing and should converge to -5 (the local minima). However, how many iterations should we perform?
Let us set a precision variable in our algorithm which calculates the difference between two consecutive “x” values . If the difference between x values from 2 consecutive iterations is lesser than the precision we set, stop the algorithm !
Gradient descent in Python :
Step 1 : Initialize parameters
cur_x = 3 # The algorithm starts at x=3
rate = 0.01 # Learning rate
precision = 0.000001 #This tells us when to stop the algorithm
previous_step_size = 1 #
max_iters = 10000 # maximum number of iterations
iters = 0 #iteration counter
df = lambda x: 2*(x+5) #Gradient of our function Step 2 : Run a loop to perform gradient descent :
i. Stop loop when difference between x values from 2 consecutive iterations is less than 0.000001 or when number of iterations exceeds 10,000
while previous_step_size > precision and iters < max_iters:
prev_x = cur_x #Store current x value in prev_x
cur_x = cur_x - rate * df(prev_x) #Grad descent
previous_step_size = abs(cur_x - prev_x) #Change in x
iters = iters+1 #iteration count
print("Iteration",iters,"\nX value is",cur_x) #Print iterations
print("The local minimum occurs at", cur_x) Output : From the output below, we can observe the x values for the first 10 iterations- which can be cross checked with our calculation above. The algorithm runs for 595 iterations before it terminates. The code and solution is embedded below for reference.
How to implement a gradient descent in Python to find a local minimum ?
Gradient Descent is an iterative algorithm that is used to minimize a function by finding the optimal parameters. Gradient Descent can be applied to any dimension function i.e. 1-D, 2-D, 3-D. In this article, we will be working on finding global minima for parabolic function (2-D) and will be implementing gradient descent in python to find the optimal parameters for the linear regression equation (1-D). Before diving into the implementation part, let us make sure the set of parameters required to implement the gradient descent algorithm. To implement a gradient descent algorithm, we require a cost function that needs to be minimized, the number of iterations, a learning rate to determine the step size at each iteration while moving towards the minimum, partial derivatives for weight & bias to update the parameters at each iteration, and a prediction function.
Till now we have seen the parameters required for gradient descent. Now let us map the parameters with the gradient descent algorithm and work on an example to better understand gradient descent. Let us consider a parabolic equation y=4x 2 . By looking at the equation we can identify that the parabolic function is minimum at x = 0 i.e. at x=0, y=0. Therefore x=0 is the local minima of the parabolic function y=4x 2 . Now let us see the algorithm for gradient descent and how we can obtain the local minima by applying gradient descent:
Algorithm for Gradient Descent
Steps should be made in proportion to the negative of the function gradient (move away from the gradient) at the current point to find local minima. Gradient Ascent is the procedure for approaching a local maximum of a function by taking steps proportional to the positive of the gradient (moving towards the gradient).
Step 1: Initializing all the necessary parameters and deriving the gradient function for the parabolic equation 4x 2 . The derivative of x 2 is 2x, so the derivative of the parabolic equation 4x 2 will be 8x.
x0 = 3 (random initialization of x)
learning_rate = 0.01 (to determine the step size while moving towards local minima)