- Extract pdf images python
- Read Pdf file in Python
- Extract Images from pdf
- Extract text from pdf using PyPDF2
- Final Words
- FAQs
- How do I extract images from a PDF?
- How do I convert a PDF to an image in Python?
- How do I read a scanned PDF in Python?
- How do I convert a PDF to a DataFrame in Python?
- How do I convert PDF to PNG in Python?
- Can I resize the images when I extract them from a PDF file using PyPDF2?
- Are there any other libraries I can use to extract images from a PDF in Python?
- Извлечение изображений из файла PDF с помощью Python и библиотек Fitz и Pillow
- Extract Images from PDF using Python
- Extract images from PDF using Python
- Complete code
Extract pdf images python
In this tutorial, we will learn about how to extract images from pdf in python with different python libraries.
Here first, we will learn about how to read pdf files in python, then extract them, and at last, we will save them.
Read Pdf file in Python
We cannot read pdf files directly using python. Instead, we need to install the necessary libraries using pip package installation.
To read pdf files, we will use the PyMuPDF python package that can access files like PDF, OpenXPS, XPS, EPUB, and many other extensions. And to install PyMuPDF, we can follow the below step.
We will use fitz() function, which is used to read or process pdf or other files with PyMuPDF.
Then we will use a fantastic python package called Pillow, which is used for image processing and image manipulation.
To install Pillow, we will use the below pip command.
We have to install the necessary libraries now. After that, we can follow the below steps to extract images from pdf files.
Extract Images from pdf
Step 1: First, we will import the required packages.
import fitz # PyMuPDF import io from PIL import Image
Step 2: Now, we will read and process the pdf file into python.
# file path you want to extract images from file = "DemoFile.pdf" # open the file pdf_file = fitz.open(file)
Step 3: In the final step, we will do the main code of the program by iterating a pdf file using for loop to process pdf pages one by one.
# iterate over PDF pages for page_index in range(len(pdf_file)): # get the page itself page = pdf_file[page_index] image_list = page.getImageList() # printing number of images found in this page if image_list: print(f"[+] Found a total of images in page ") else: print("[!] No images found on page", page_index) for image_index, img in enumerate(page.getImageList(), start=1): # get the XREF of the image xref = img[0] # extract the image bytes base_image = pdf_file.extractImage(xref) image_bytes = base_image["image"] # get the image extension image_ext = base_image["ext"] # load it to PIL image = Image.open(io.BytesIO(image_bytes)) # save it to local disk image.save(open(f"image_.", "wb")) Here we will first check the number of pages inside the pdf file, and one by one, it will process the pages on the pdf file and detect the images inside the page, and once it finds it and saves it in the desired locations.
Inside the iterator, we are making a list of all the images available inside the page using the getImageList(), and after that, we use the extractImage() function.
Also, if you are interested to learn Mouse and Keyboard automation using Python, you must check this out.
The whole program will look as follow.
import fitz # PyMuPDF import io from PIL import Image # file path you want to extract images from file = "DemoFile.pdf" # open the file pdf_file = fitz.open(file) # iterate over PDF pages for page_index in range(len(pdf_file)): # get the page itself page = pdf_file[page_index] image_list = page.getImageList() # printing number of images found in this page if image_list: print(f"[+] Found a total of images in page ") else: print("[!] No images found on page", page_index) for image_index, img in enumerate(page.getImageList(), start=1): # get the XREF of the image xref = img[0] # extract the image bytes base_image = pdf_file.extractImage(xref) image_bytes = base_image["image"] # get the image extension image_ext = base_image["ext"] # load it to PIL image = Image.open(io.BytesIO(image_bytes)) # save it to local disk image.save(open(f"image_.", "wb")) Extract text from pdf using PyPDF2
In this method, we will use the PyPDF2 package to extract the text, and in the method, we don’t require other packages like the above method. We can directly extract text from pdf.
To install the PyPDF2 package, we will follow the below command on your respected operating systems.
You can also use the PyPDF or PyPDF3 version, but all three versions will work.
Once the PyPDF2 package is installed, we will start to wring the program to read the pdf file, convert all the pages into text, and print it on the given destination terminal or IDE.
Follow the below steps to extract text from the pdf file.
Step 1: The first step will be to import the PyPDF2 package.
#import the PyPDF2 module import PyPDF2
Step 2: Now, we will read the pdf file and process it will the PyPDF2 using PdfFileReader() function.
#open the PDF file PDFfile = open('DemoFile.pdf', 'rb') PDFfilereader = PyPDF2.PdfFileReader(PDFfile) Step 3: Here, we will find the number of pages in our pdf files. This will print the total number of pages with an index starting from zero.
#print the number of pages print(PDFfilereader.numPages)
Step 4: Now, we will specify the page we want to extract and print the text content of the given page.
#provide the page number pages = PDFfilereader.getPage(8) #extracting the text in PDF file print(pages.extractText())
The extractText() function will extract all the text from the page specify in getPage() function.
Step 5: We will close a pdf file as our text has been extracted.
#close the PDF file PDFfile.close()
The Whole program will look like this.
#import the PyPDF2 module import PyPDF2 #open the PDF file PDFfile = open('DemoFile.pdf', 'rb') PDFfilereader = PyPDF2.PdfFileReader(PDFfile) #print the number of pages print(PDFfilereader.numPages) #provide the page number pages = PDFfilereader.getPage(8) #extracting the text in PDF file print(pages.extractText()) #close the PDF file PDFfile.close() Final Words
In this article, we have learned how to extract images from text from the pdf file, and reading pdf files in python code is not easy; it needs separate libraries to process and read it. But with our easy tutorial, we can very quickly extract the images and text from the pdf file. Also, please let us know via email if you have a suggestion for our blogs.
FAQs
How do I extract images from a PDF?
PyMuPDF package is used to extract images from a pdf file in python.PyMuPDF extract images from PDF detecting all the images from the pdf file and please note that it will not convert pdf pages into images inside it will just extract image if there is one.
How do I convert a PDF to an image in Python?
There are many ways to convert a pdf to an image in python we can use the pdf2image library which is the most popular in converting pages into images.
How do I read a scanned PDF in Python?
Yes, you can read a scanned pdf in python using the PyMuPDF library.
How do I convert a PDF to a DataFrame in Python?
You can convert PDF to a DataFrame in python using pandas and tabula-py library but pdf must contain tabular data inside otherwise one data will be converted into a dataframe. It will Extract specific data from PDF using Python if it will get the tabular or table data.
How do I convert PDF to PNG in Python?
Yes you can convert pdf pages into png format in python using pdf2image python package, which very easy to code and it will convert all the pdf pages into images in what format you want. We can also Convert PDF to image python opencv but it will be very hand and take long to convert it.
Can I resize the images when I extract them from a PDF file using PyPDF2?
Yes, you can resize the images when you extract them from a PDF file using PyPDF2. Once you have accessed the image using the XObject attribute of the page object, you can use the resize method from the Image module of PIL to resize the image.
Are there any other libraries I can use to extract images from a PDF in Python?
Yes, there are other libraries you can use to extract images from a PDF in Python, such as PyMuPDF, pdfminer, and pdftotext. Each library has its own strengths and weaknesses, so you may want to try different libraries to see which one works best for your specific use case.
Извлечение изображений из файла PDF с помощью Python и библиотек Fitz и Pillow
В этом блоге мы узнаем, как читать и извлекать содержимое (как текст, так и изображения), вращать отдельные страницы и разбивать документы на отдельные страницы. В этой статье более подробно рассмотрим извлечение изображений из pdf-файлов с помощью Pillow и библиотеки Fitz.
Приведенный ниже код извлекает изображения из файла PDF с помощью библиотеки fitz . Сначала он открывает файл PDF с помощью fitz.open() и перебирает все страницы в PDF с помощью len(pdf_file) . Для каждой страницы он извлекает все изображения на странице с помощью page.get_images() и перебирает их с помощью enumerate() . Затем он извлекает байты изображения с помощью pdf_file.extract_image(xref) и загружает их в изображение PIL с помощью Image.open(io.BytesIO(image_bytes)) . Наконец, он сохраняет изображение на диск с помощью image.save() с именем файла, основанным на исходном имени файла, номере страницы и номере изображения.
Также обратите внимание, что fitz и pillow не является встроенной библиотекой Python, поэтому вам может потребоваться установить ее отдельно, используя pip install PyMuPDF Pillow .
import os import pandas as pd from PIL import Image from io import BytesIO import fitz import io file = 'useR_PrecTemp.pdf' print(file) target_name = f"" print(target_name) pdf_file = fitz.open(file) # print ("number of pages: %i" % doc.pageCount) # page1 = doc.load_page(0) # page1text = page1.get_text("text") # print(page1text) for page_index in range(len(pdf_file)): # get the page itself page = pdf_file[page_index] image_list = page.get_images() # printing number of images found in this page if image_list: print(f"[+] Found a total of images in page ") else: print("[!] No images found on page", page_index) for image_index, img in enumerate(page.get_images(), start=1): # get the XREF of the image xref = img[0] # extract the image bytes base_image = pdf_file.extract_image(xref) image_bytes = base_image["image"] # get the image extension #image_ext = base_image["ext"] # load it to PIL image = Image.open(io.BytesIO(image_bytes)) # save it to local disk image.save(f"__.jpeg")Вы получите вывод, как показано ниже:
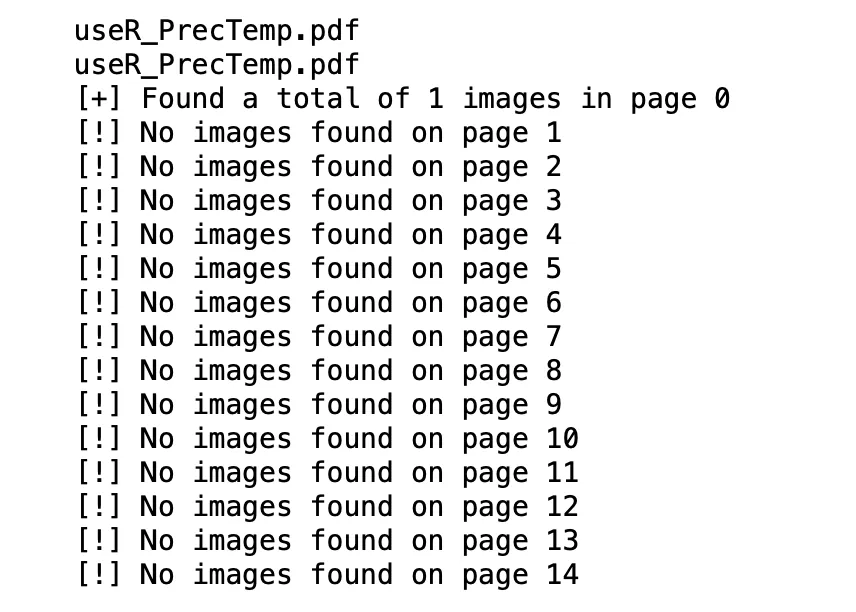
Этот код способен определить общее количество изображений, присутствующих на каждой странице файла PDF. Более того, он предназначен для сохранения каждого из этих изображений с их исходными именами файлов и соответствующим номером страницы, на которой они были обнаружены.
Каждый разработчик в своей жизни встречается с тем, что приходится конвертировать изображения PNG в изображение JPG. Приглагаем вам создать один такой скрипт, который преобразует изображения из одного формата файла (типа изображения) в другой — всего за 6 строк кода.
Не малую часть работы составляет также передача данных из одного сервиса в другой без потери качества. Задача тривиальна и требует решения. Нам поможет Python Flask: отправляем файлы и данные формы из одного сервиса в другой.
Extract Images from PDF using Python

In this tutorial we will explore how to extract images from PDF files using Python.
Table of Contents
Extract images from PDF using Python
Let’s start with importing the required dependencies:
Define the path to PDF file:
Open the file using fitz module and extract all images information:
Now, let’s take a look at the images information we extracted:
[(9, 0, 640, 491, 8, 'DeviceRGB', '', 'Image9', 'DCTDecode'), (10, 0, 640, 427, 8, 'DeviceRGB', '', 'Image10', 'DCTDecode'), (13, 0, 640, 427, 8, 'DeviceRGB', '', 'Image13', 'DCTDecode')]where each tuple represents the following:
(xref, smask, width, height, bpc, colorspace, alt. colorspace, name, filter)Now let’s add some error handling code in case the PDF file we work with has no images:
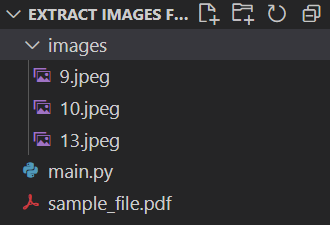
After we have extracted the images information from the PDF file, we can extract the actual images and save them on the computer:
After running the code, you should see the extracted images appear in the images folder:
Complete code
') #Save all the extracted images for i, img in enumerate(images_list, start=1): #Extract the image object number xref = img[0] #Extract image base_image = pdf_file.extract_image(xref) #Store image bytes image_bytes = base_image['image'] #Store image extension image_ext = base_image['ext'] #Generate image file name image_name = str(i) + '.' + image_ext #Save image with open(os.path.join(images_path, image_name) , 'wb') as image_file: image_file.write(image_bytes) image_file.close()