- Python encode() and decode() Functions
- Encode a given String
- Handling errors
- Decoding a Stream of Bytes
- Importance of encoding
- Conclusion
- References
- Функции encode() и decode() в Python
- encode заданной строки
- Обработка ошибок
- Декодирование потока байтов
- Важность кодировки
- Python String encode() decode()
- Python String encode()
- Python Bytes decode()
Python encode() and decode() Functions
Python’s encode and decode methods are used to encode and decode the input string, using a given encoding. Let us look at these two functions in detail in this article.
Encode a given String
We use the encode() method on the input string, which every string object has.
input_string.encode(encoding, errors)
This encodes input_string using encoding , where errors decides the behavior to be followed if, by any chance, the encoding fails on the string.
encode() will result in a sequence of bytes .
inp_string = 'Hello' bytes_encoded = inp_string.encode() print(type(bytes_encoded))
This results in an object of , as expected:
The type of encoding to be followed is shown by the encoding parameter. There are various types of character encoding schemes, out of which the scheme UTF-8 is used in Python by default.
Let us look at the encoding parameter using an example.
a = 'This is a simple sentence.' print('Original string:', a) # Decodes to utf-8 by default a_utf = a.encode() print('Encoded string:', a_utf) Original string: This is a simple sentence. Encoded string: b'This is a simple sentence.'
NOTE: As you can observe, we have encoded the input string in the UTF-8 format. Although there is not much of a difference, you can observe that the string is prefixed with a b . This means that the string is converted to a stream of bytes, which is how it is stored on any computer. As bytes!
This is actually not human-readable and is only represented as the original string for readability, prefixed with a b , to denote that it is not a string, but a sequence of bytes.
Handling errors
There are various types of errors , some of which are mentioned below:
| Type of Error | Behavior |
| strict | Default behavior which raises UnicodeDecodeError on failure. |
| ignore | Ignores the un-encodable Unicode from the result. |
| replace | Replaces all un-encodable Unicode characters with a question mark ( ? ) |
| backslashreplace | Inserts a backslash escape sequence ( \uNNNN ) instead of un-encodable Unicode characters. |
Let us look at the above concepts using a simple example. We will consider an input string where not all characters are encodable (such as ö ),
a = 'This is a bit möre cömplex sentence.' print('Original string:', a) print('Encoding with errors=ignore:', a.encode(encoding='ascii', errors='ignore')) print('Encoding with errors=replace:', a.encode(encoding='ascii', errors='replace')) Original string: This is a möre cömplex sentence. Encoding with errors=ignore: b'This is a bit mre cmplex sentence.' Encoding with errors=replace: b'This is a bit m?re c?mplex sentence.'
Decoding a Stream of Bytes
Similar to encoding a string, we can decode a stream of bytes to a string object, using the decode() function.
encoded = input_string.encode() # Using decode() decoded = encoded.decode(decoding, errors)
Since encode() converts a string to bytes, decode() simply does the reverse.
byte_seq = b'Hello' decoded_string = byte_seq.decode() print(type(decoded_string)) print(decoded_string)
This shows that decode() converts bytes to a Python string.
Similar to those of encode() , the decoding parameter decides the type of encoding from which the byte sequence is decoded. The errors parameter denotes the behavior if the decoding fails, which has the same values as that of encode() .
Importance of encoding
Since encoding and decoding an input string depends on the format, we must be careful when encoding/decoding. If we use the wrong format, it will result in the wrong output and can give rise to errors.
The below snippet shows the importance of encoding and decoding.
The first decoding is incorrect, as it tries to decode an input string which is encoded in the UTF-8 format. The second one is correct since the encoding and decoding formats are the same.
a = 'This is a bit möre cömplex sentence.' print('Original string:', a) # Encoding in UTF-8 encoded_bytes = a.encode('utf-8', 'replace') # Trying to decode via ASCII, which is incorrect decoded_incorrect = encoded_bytes.decode('ascii', 'replace') decoded_correct = encoded_bytes.decode('utf-8', 'replace') print('Incorrectly Decoded string:', decoded_incorrect) print('Correctly Decoded string:', decoded_correct) Original string: This is a bit möre cömplex sentence. Incorrectly Decoded string: This is a bit m��re c��mplex sentence. Correctly Decoded string: This is a bit möre cömplex sentence.
Conclusion
In this article, we learned how to use the encode() and decode() methods to encode an input string and decode an encoded byte sequence.
We also learned about how it handles errors in encoding/decoding via the errors parameter. This can be useful for encryption and decryption purposes, such as locally caching an encrypted password and decoding them for later use.
References
Функции encode() и decode() в Python
Методы encode и decode Python используются для кодирования и декодирования входной строки с использованием заданной кодировки. Давайте подробно рассмотрим эти две функции.
encode заданной строки
Мы используем метод encode() для входной строки, который есть у каждого строкового объекта.
input_string.encode(encoding, errors)
Это кодирует input_string с использованием encoding , где errors определяют поведение, которому надо следовать, если по какой-либо случайности кодирование строки не выполняется.
encode() приведет к последовательности bytes .
inp_string = 'Hello' bytes_encoded = inp_string.encode() print(type(bytes_encoded))
Как и ожидалось, в результате получается объект :
Тип кодирования, которому надо следовать, отображается параметром encoding . Существуют различные типы схем кодирования символов, из которых в Python по умолчанию используется схема UTF-8.
Рассмотрим параметр encoding на примере.
a = 'This is a simple sentence.' print('Original string:', a) # Decodes to utf-8 by default a_utf = a.encode() print('Encoded string:', a_utf) Original string: This is a simple sentence. Encoded string: b'This is a simple sentence.'
Как вы можете заметить, мы закодировали входную строку в формате UTF-8. Хотя особой разницы нет, вы можете заметить, что строка имеет префикс b . Это означает, что строка преобразуется в поток байтов.
На самом деле это представляется только как исходная строка для удобства чтения с префиксом b , чтобы обозначить, что это не строка, а последовательность байтов.
Обработка ошибок
Существуют различные типы errors , некоторые из которых указаны ниже:
| Тип ошибки | Поведение |
| strict | Поведение по умолчанию, которое вызывает UnicodeDecodeError при сбое. |
| ignore | Игнорирует некодируемый Unicode из результата. |
| replace | Заменяет все некодируемые символы Юникода вопросительным знаком (?) |
| backslashreplace | Вставляет escape-последовательность обратной косой черты (\ uNNNN) вместо некодируемых символов Юникода. |
Давайте посмотрим на приведенные выше концепции на простом примере. Мы рассмотрим входную строку, в которой не все символы кодируются (например, ö ),
a = 'This is a bit möre cömplex sentence.' print('Original string:', a) print('Encoding with errors=ignore:', a.encode(encoding='ascii', errors='ignore')) print('Encoding with errors=replace:', a.encode(encoding='ascii', errors='replace')) Original string: This is a möre cömplex sentence. Encoding with errors=ignore: b'This is a bit mre cmplex sentence.' Encoding with errors=replace: b'This is a bit m?re c?mplex sentence.'
Декодирование потока байтов
Подобно кодированию строки, мы можем декодировать поток байтов в строковый объект, используя функцию decode() .
encoded = input_string.encode() # Using decode() decoded = encoded.decode(decoding, errors)
Поскольку encode() преобразует строку в байты, decode() просто делает обратное.
byte_seq = b'Hello' decoded_string = byte_seq.decode() print(type(decoded_string)) print(decoded_string)
Это показывает, что decode() преобразует байты в строку Python.
Подобно параметрам encode() , параметр decoding определяет тип кодирования, из которого декодируется последовательность байтов. Параметр errors обозначает поведение в случае сбоя декодирования, который имеет те же значения, что и у encode() .
Важность кодировки
Поскольку кодирование и декодирование входной строки зависит от формата, мы должны быть осторожны при этих операциях. Если мы используем неправильный формат, это приведет к неправильному выводу и может вызвать ошибки.
Первое декодирование неверно, так как оно пытается декодировать входную строку, которая закодирована в формате UTF-8. Второй правильный, поскольку форматы кодирования и декодирования совпадают.
a = 'This is a bit möre cömplex sentence.' print('Original string:', a) # Encoding in UTF-8 encoded_bytes = a.encode('utf-8', 'replace') # Trying to decode via ASCII, which is incorrect decoded_incorrect = encoded_bytes.decode('ascii', 'replace') decoded_correct = encoded_bytes.decode('utf-8', 'replace') print('Incorrectly Decoded string:', decoded_incorrect) print('Correctly Decoded string:', decoded_correct) Original string: This is a bit möre cömplex sentence. Incorrectly Decoded string: This is a bit m��re c��mplex sentence. Correctly Decoded string: This is a bit möre cömplex sentence.
Python String encode() decode()

While we believe that this content benefits our community, we have not yet thoroughly reviewed it. If you have any suggestions for improvements, please let us know by clicking the “report an issue“ button at the bottom of the tutorial.
Python String encode()
Python string encode() function is used to encode the string using the provided encoding. This function returns the bytes object. If we don’t provide encoding, “utf-8” encoding is used as default.
Python Bytes decode()
Python bytes decode() function is used to convert bytes to string object. Both these functions allow us to specify the error handling scheme to use for encoding/decoding errors. The default is ‘strict’ meaning that encoding errors raise a UnicodeEncodeError. Some other possible values are ‘ignore’, ‘replace’ and ‘xmlcharrefreplace’. Let’s look at a simple example of python string encode() decode() functions.
str_original = 'Hello' bytes_encoded = str_original.encode(encoding='utf-8') print(type(bytes_encoded)) str_decoded = bytes_encoded.decode() print(type(str_decoded)) print('Encoded bytes =', bytes_encoded) print('Decoded String =', str_decoded) print('str_original equals str_decoded =', str_original == str_decoded) Encoded bytes = b'Hello' Decoded String = Hello str_original equals str_decoded = True Above example doesn’t clearly demonstrate the use of encoding. Let’s look at another example where we will get inputs from the user and then encode it. We will have some special characters in the input string entered by the user.
str_original = input('Please enter string data:\n') bytes_encoded = str_original.encode() str_decoded = bytes_encoded.decode() print('Encoded bytes =', bytes_encoded) print('Decoded String =', str_decoded) print('str_original equals str_decoded =', str_original == str_decoded) 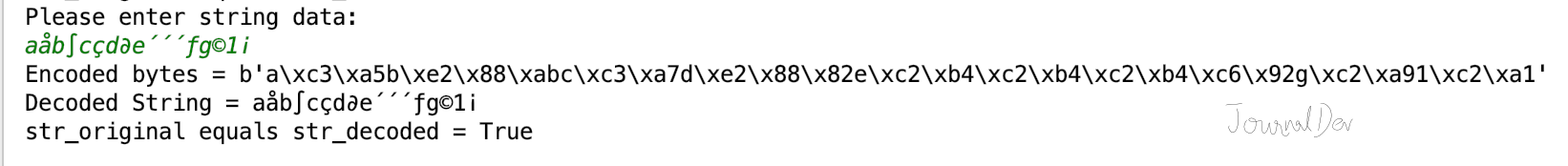
Output:
Please enter string data: aåb∫cçd∂e´´´ƒg©1¡ Encoded bytes = b'a\xc3\xa5b\xe2\x88\xabc\xc3\xa7d\xe2\x88\x82e\xc2\xb4\xc2\xb4\xc2\xb4\xc6\x92g\xc2\xa91\xc2\xa1' Decoded String = aåb∫cçd∂e´´´ƒg©1¡ str_original equals str_decoded = True You can checkout complete python script and more Python examples from our GitHub Repository. Reference: str.encode() API Doc, bytes.decode() API Doc
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases. Learn more about us