- Как использовать метод Pandas.ExcelWriter в Python?
- Что такое функция Pandas.ExcelWriter() в Python?
- Синтаксис
- Параметры
- Возвращаемое значение
- Пример программы с Pandas ExcelWriter()
- Что такое функция Pandas DataFrame to_excel()?
- pandas.DataFrame.to_excel#
- Как экспортировать фрейм данных Pandas в Excel
- Пример 1: базовый экспорт
- Пример 2: Экспорт без индекса
- Пример 3: Экспорт без индекса и заголовка
- Пример 4: Экспорт и имя листа
Как использовать метод Pandas.ExcelWriter в Python?
Python Pandas — это библиотека для анализа данных. Она может читать, фильтровать и переупорядочивать небольшие и большие наборы данных и выводить их в различных форматах, включая Excel. ExcelWriter() определен в библиотеке Pandas.
Что такое функция Pandas.ExcelWriter() в Python?
Метод Pandas.ExcelWriter() — это класс для записи объектов DataFrame в файлы Excel в Python. ExcelWriter() можно использовать для записи текста, чисел, строк, формул. Он также может работать на нескольких листах.Для данного примера необходимо, чтоб вы установили на свой компьютер библиотеки Numpy и Pandas.
Синтаксис
pandas . ExcelWriter ( path , engine = None , date_format = None , datetime_format = None , mode = ’ w ’ , * * engine_krawgs )
Параметры
Все параметры установлены на значения по умолчанию.
Функция Pandas.ExcelWriter() имеет пять параметров.
- path: имеет строковый тип, указывающий путь к файлу xls или xlsx.
- engine: он также имеет строковый тип и является необязательным. Это движок для написания.
- date_format: также имеет строковый тип и имеет значение по умолчанию None. Он форматирует строку для дат, записанных в файлы Excel.
- datetime_format: также имеет строковый тип и имеет значение по умолчанию None. Он форматирует строку для объектов даты и времени, записанных в файлы Excel.
- Mode: это режим файла для записи или добавления. Его значение по умолчанию — запись, то есть ‘w’.
Возвращаемое значение
Он экспортирует данные в файл Excel.
Пример программы с Pandas ExcelWriter()
Вам необходимо установить и импортировать модуль xlsxwriter. Если вы используете блокнот Jupyter, он вам не понадобится; в противном случае вы должны установить его.
Напишем программу, показывающую работу ExcelWriter() в Python.
Содержимое файла Excel следующее.

В приведенном выше коде мы создали DataFrame, в котором хранятся данные студентов. Затем мы создали объект для записи данных DataFrame на лист Excel, и после записи данных мы сохранили лист. Некоторые значения в приведенном выше листе Excel пусты, потому что в DataFrame эти значения — np.nan. Чтобы проверить данные DataFrame, проверьте лист Excel.
Что такое функция Pandas DataFrame to_excel()?
Функция Pandas DataFrame to_excel() записывает объект на лист Excel. Мы использовали функцию to_excel() в приведенном выше примере, потому что метод ExcelWriter() возвращает объект записи, а затем мы используем метод DataFrame.to_excel() для его экспорта в файл Excel.
Чтобы записать один объект в файл Excel .xlsx, необходимо только указать имя целевого файла. Для записи на несколько листов необходимо создать объект ExcelWriter с именем целевого файла и указать лист в файле для записи.
На несколько листов можно записать, указав уникальное имя листа. При записи всех данных в файл необходимо сохранить изменения. Обратите внимание, что создание объекта ExcelWriter с уже существующим именем файла приведет к удалению содержимого существующего файла.
Мы также можем написать приведенный выше пример, используя Python с оператором.
pandas.DataFrame.to_excel#
DataFrame. to_excel ( excel_writer , sheet_name = ‘Sheet1’ , na_rep = » , float_format = None , columns = None , header = True , index = True , index_label = None , startrow = 0 , startcol = 0 , engine = None , merge_cells = True , inf_rep = ‘inf’ , freeze_panes = None , storage_options = None ) [source] #
Write object to an Excel sheet.
To write a single object to an Excel .xlsx file it is only necessary to specify a target file name. To write to multiple sheets it is necessary to create an ExcelWriter object with a target file name, and specify a sheet in the file to write to.
Multiple sheets may be written to by specifying unique sheet_name . With all data written to the file it is necessary to save the changes. Note that creating an ExcelWriter object with a file name that already exists will result in the contents of the existing file being erased.
Parameters excel_writer path-like, file-like, or ExcelWriter object
File path or existing ExcelWriter.
sheet_name str, default ‘Sheet1’
Name of sheet which will contain DataFrame.
na_rep str, default ‘’
Missing data representation.
float_format str, optional
Format string for floating point numbers. For example float_format=»%.2f» will format 0.1234 to 0.12.
columns sequence or list of str, optional
header bool or list of str, default True
Write out the column names. If a list of string is given it is assumed to be aliases for the column names.
index bool, default True
index_label str or sequence, optional
Column label for index column(s) if desired. If not specified, and header and index are True, then the index names are used. A sequence should be given if the DataFrame uses MultiIndex.
startrow int, default 0
Upper left cell row to dump data frame.
startcol int, default 0
Upper left cell column to dump data frame.
engine str, optional
Write engine to use, ‘openpyxl’ or ‘xlsxwriter’. You can also set this via the options io.excel.xlsx.writer or io.excel.xlsm.writer .
merge_cells bool, default True
Write MultiIndex and Hierarchical Rows as merged cells.
inf_rep str, default ‘inf’
Representation for infinity (there is no native representation for infinity in Excel).
freeze_panes tuple of int (length 2), optional
Specifies the one-based bottommost row and rightmost column that is to be frozen.
storage_options dict, optional
Extra options that make sense for a particular storage connection, e.g. host, port, username, password, etc. For HTTP(S) URLs the key-value pairs are forwarded to urllib.request.Request as header options. For other URLs (e.g. starting with “s3://”, and “gcs://”) the key-value pairs are forwarded to fsspec.open . Please see fsspec and urllib for more details, and for more examples on storage options refer here.
Write DataFrame to a comma-separated values (csv) file.
Class for writing DataFrame objects into excel sheets.
Read an Excel file into a pandas DataFrame.
Read a comma-separated values (csv) file into DataFrame.
Add styles to Excel sheet.
For compatibility with to_csv() , to_excel serializes lists and dicts to strings before writing.
Once a workbook has been saved it is not possible to write further data without rewriting the whole workbook.
Create, write to and save a workbook:
>>> df1 = pd.DataFrame([['a', 'b'], ['c', 'd']], . index=['row 1', 'row 2'], . columns=['col 1', 'col 2']) >>> df1.to_excel("output.xlsx")
To specify the sheet name:
>>> df1.to_excel("output.xlsx", . sheet_name='Sheet_name_1')
If you wish to write to more than one sheet in the workbook, it is necessary to specify an ExcelWriter object:
>>> df2 = df1.copy() >>> with pd.ExcelWriter('output.xlsx') as writer: . df1.to_excel(writer, sheet_name='Sheet_name_1') . df2.to_excel(writer, sheet_name='Sheet_name_2')
ExcelWriter can also be used to append to an existing Excel file:
>>> with pd.ExcelWriter('output.xlsx', . mode='a') as writer: . df.to_excel(writer, sheet_name='Sheet_name_3')
To set the library that is used to write the Excel file, you can pass the engine keyword (the default engine is automatically chosen depending on the file extension):
>>> df1.to_excel('output1.xlsx', engine='xlsxwriter')
Как экспортировать фрейм данных Pandas в Excel
Часто вас может заинтересовать экспорт фрейма данных pandas в Excel. К счастью, это легко сделать с помощью функции pandas to_excel() .
Чтобы использовать эту функцию, вам нужно сначала установить openpyxl , чтобы вы могли записывать файлы в Excel:
В этом руководстве будет объяснено несколько примеров использования этой функции со следующим фреймом данных:
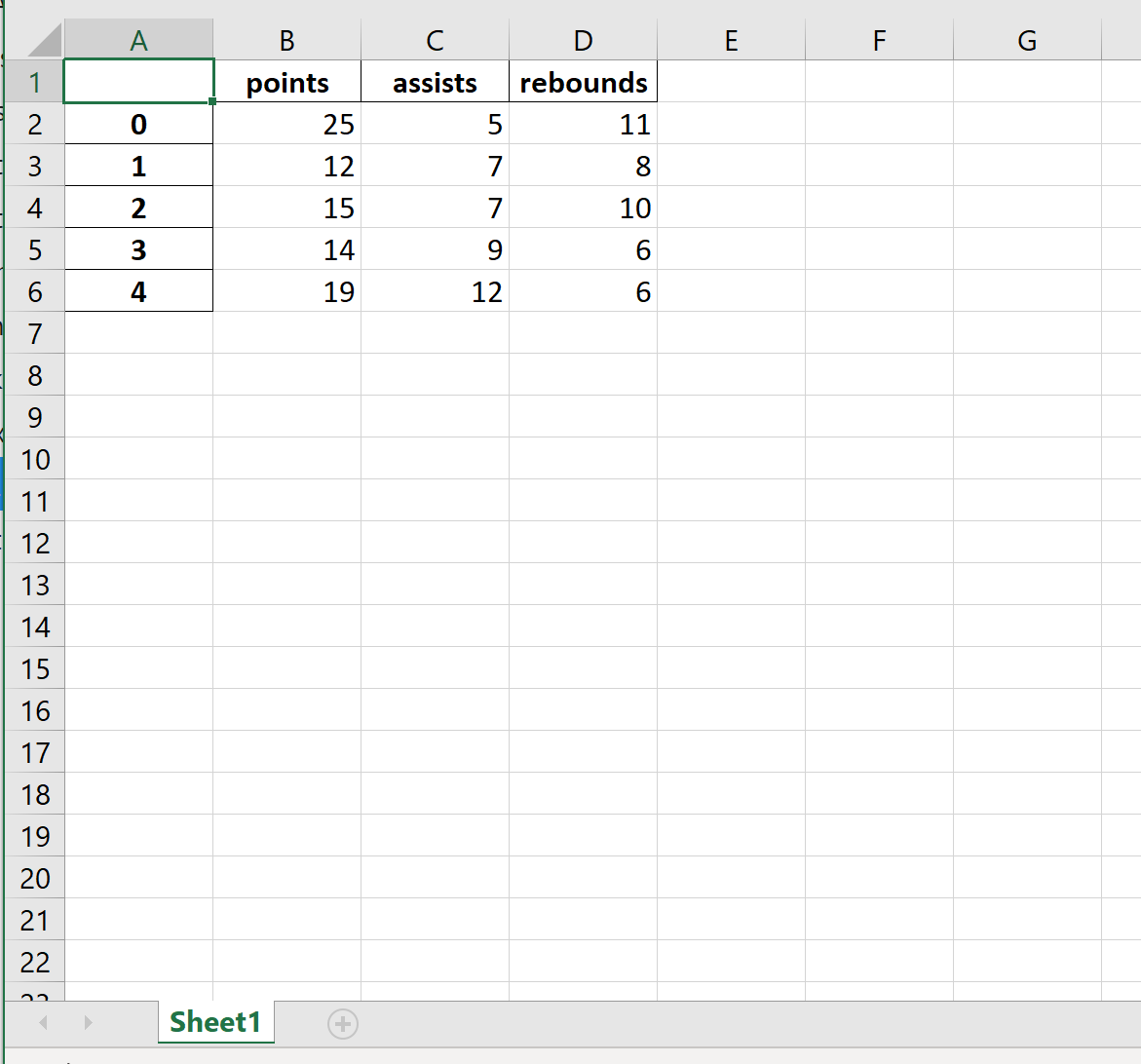
import pandas as pd #create DataFrame df = pd.DataFrame() #view DataFrame df points assists rebounds 0 25 5 11 1 12 7 8 2 15 7 10 3 14 9 6 4 19 12 6 Пример 1: базовый экспорт
В следующем коде показано, как экспортировать DataFrame по определенному пути к файлу и сохранить его как mydata.xlsx :
df.to_excel (r'C:\Users\Zach\Desktop\mydata.xlsx') Вот как выглядит фактический файл Excel:
Пример 2: Экспорт без индекса
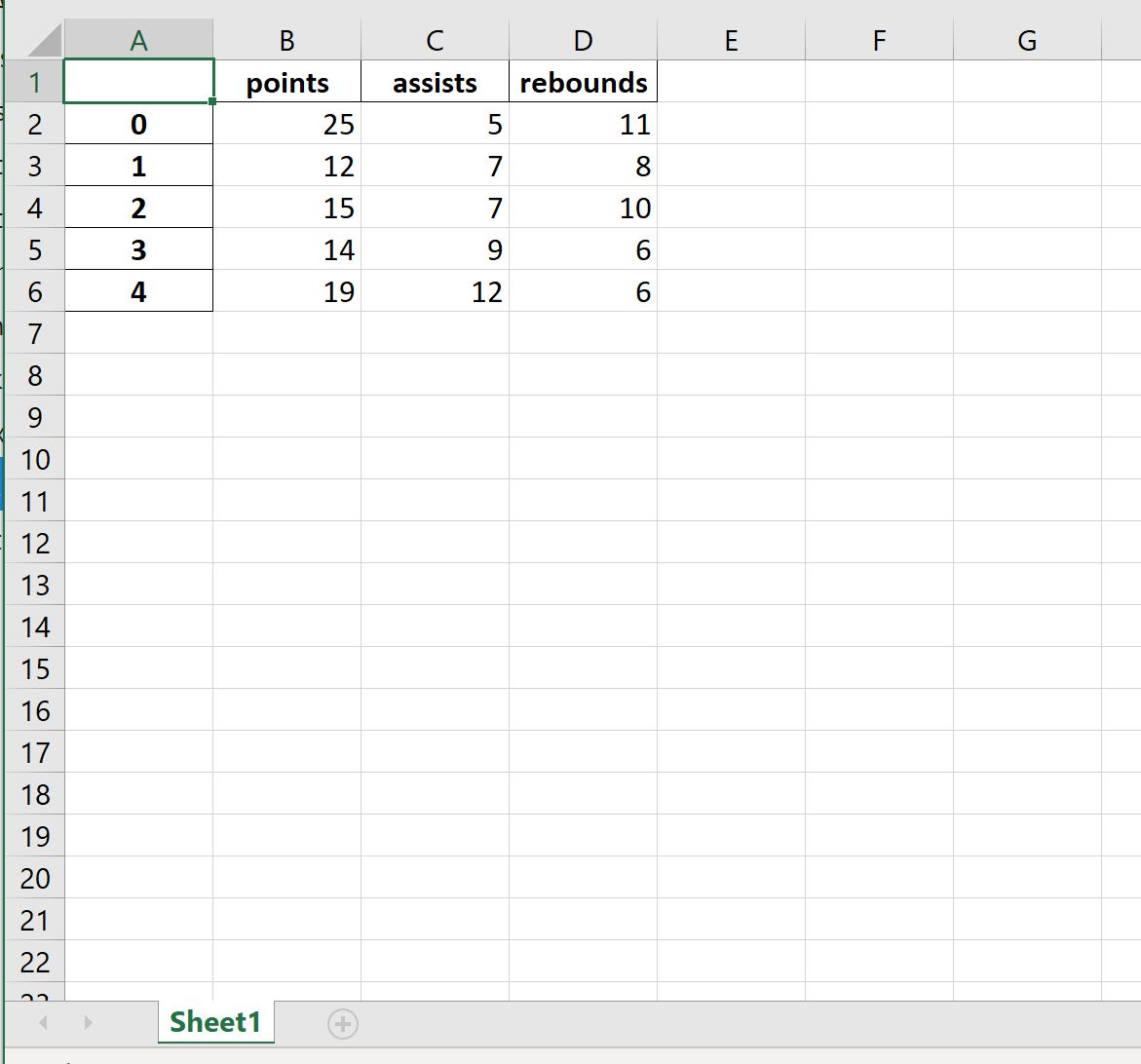
В следующем коде показано, как экспортировать DataFrame в определенный путь к файлу и удалить столбец индекса:
df.to_excel (r'C:\Users\Zach\Desktop\mydata.xlsx', index= False ) Вот как выглядит фактический файл Excel:
Пример 3: Экспорт без индекса и заголовка
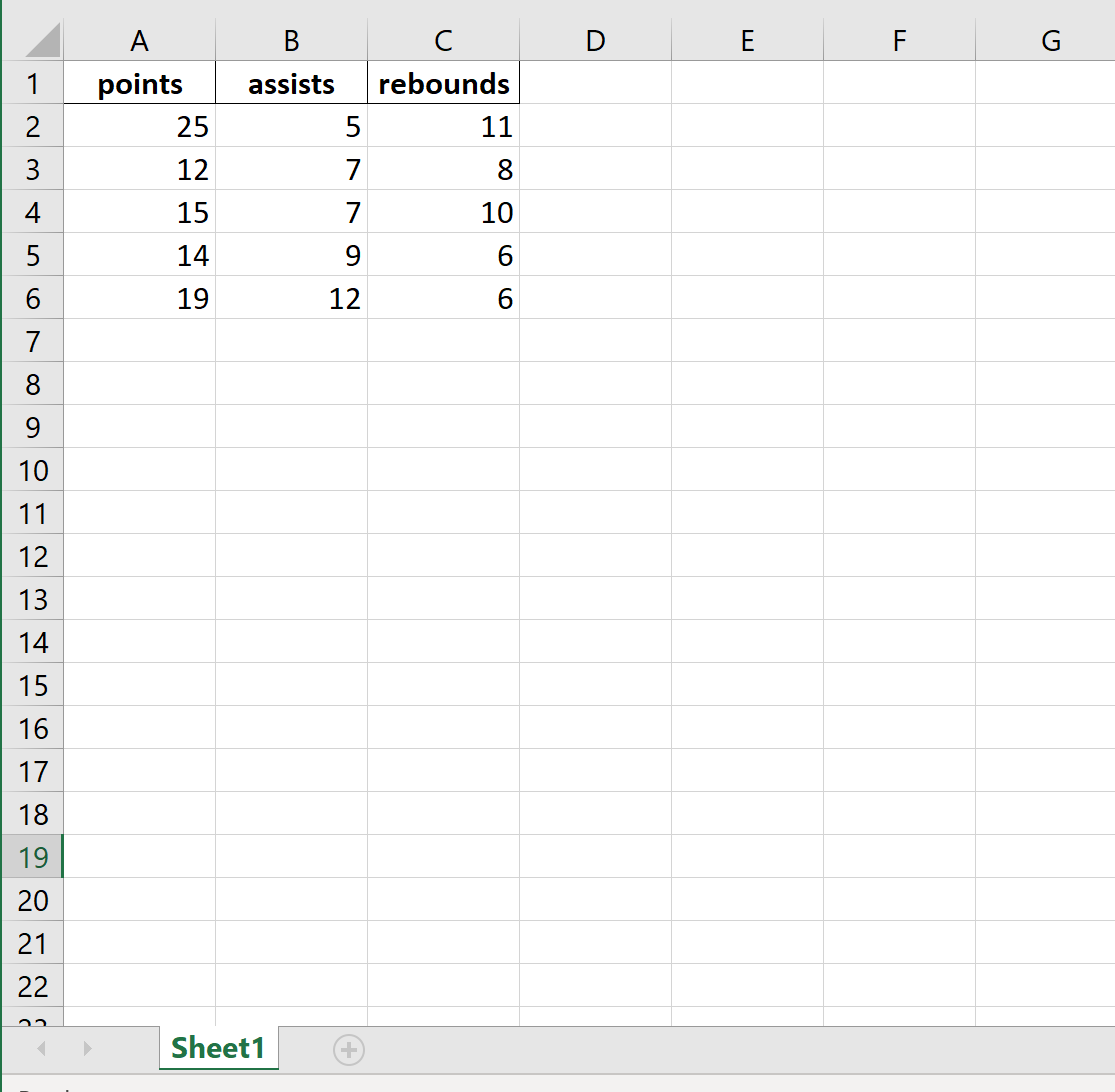
В следующем коде показано, как экспортировать DataFrame в определенный путь к файлу и удалить столбец индекса и строку заголовка:
df.to_excel (r'C:\Users\Zach\Desktop\mydata.xlsx', index= False, header= False ) Вот как выглядит фактический файл Excel:
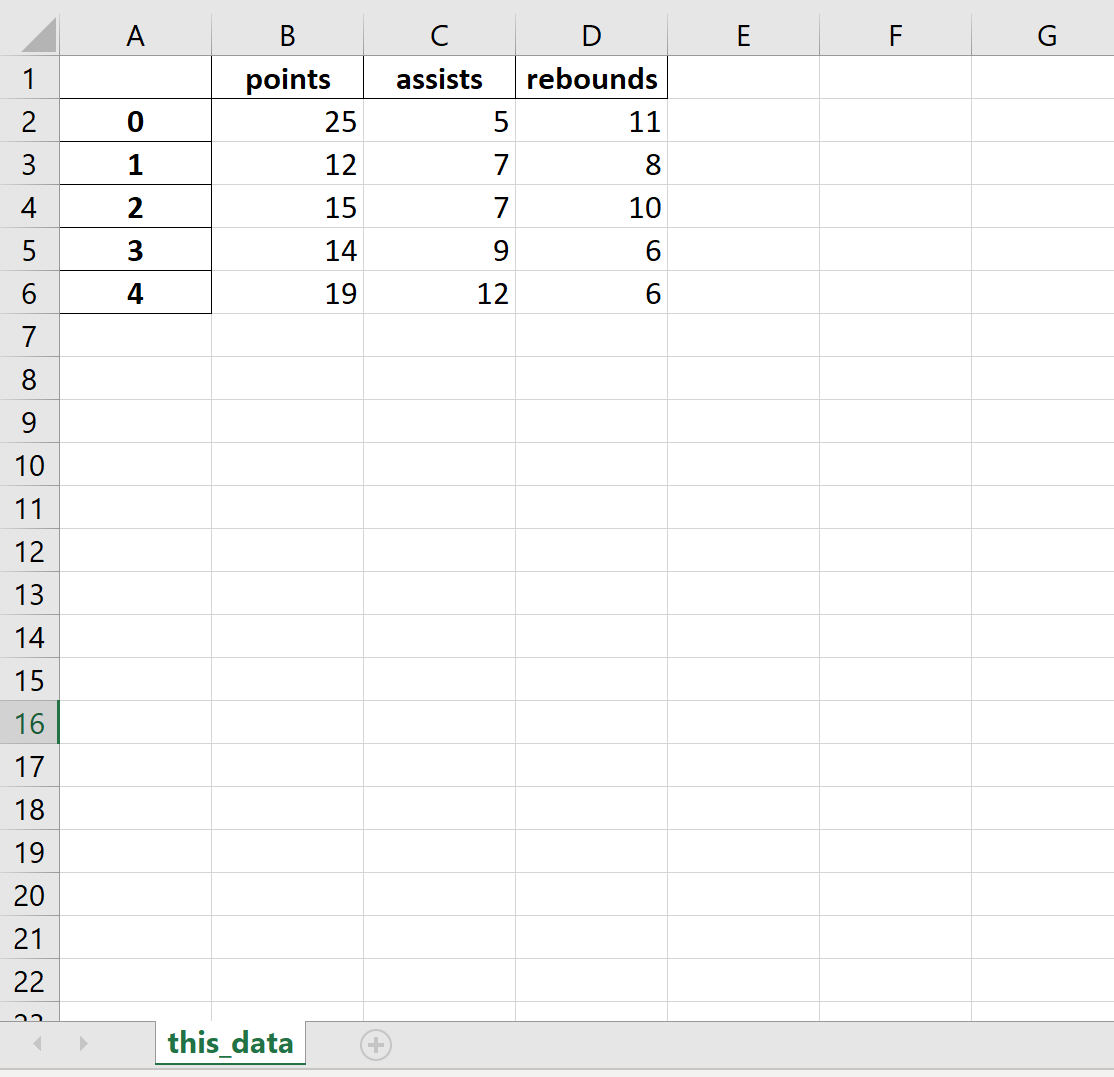
Пример 4: Экспорт и имя листа
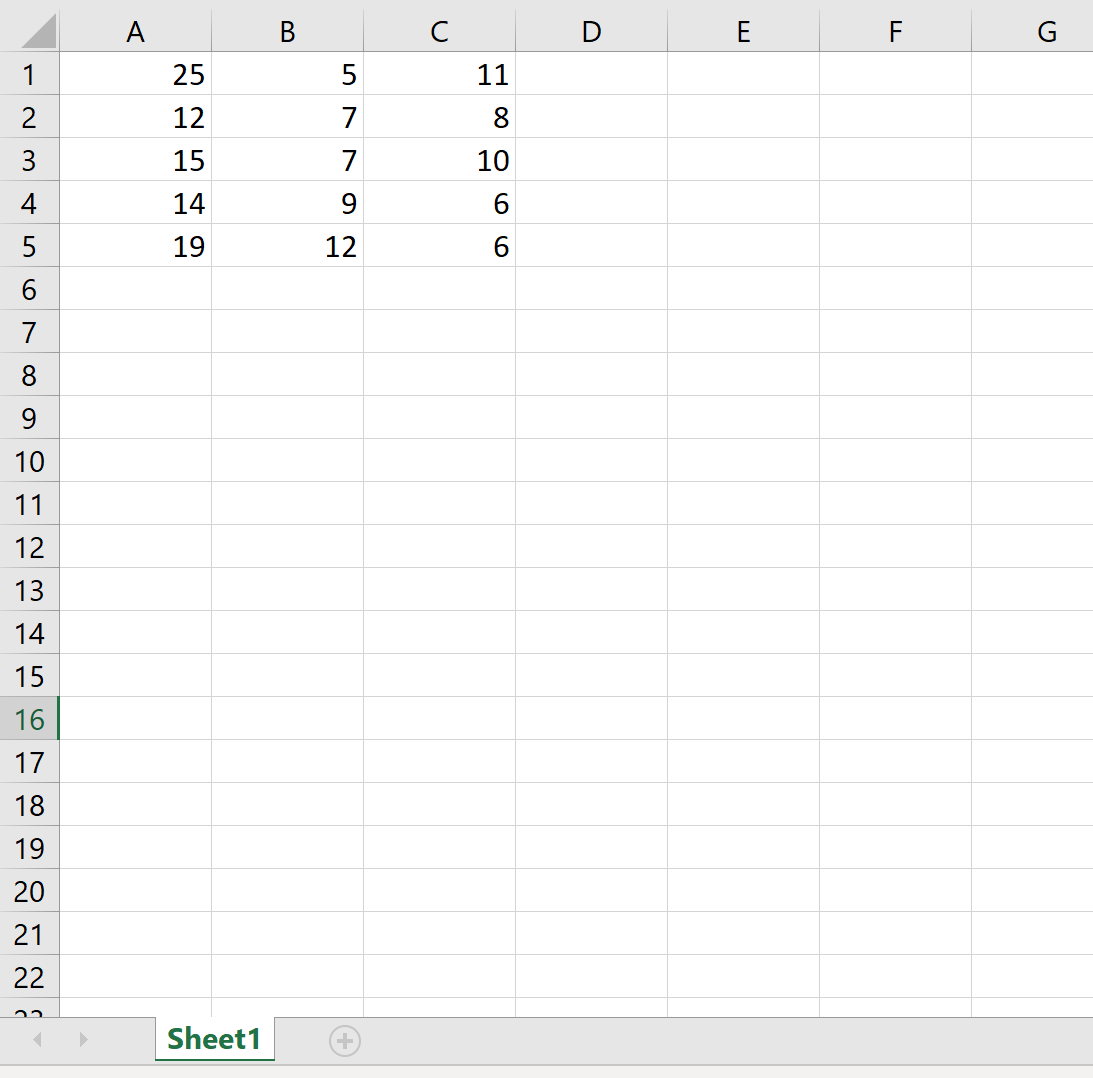
В следующем коде показано, как экспортировать DataFrame в определенный путь к файлу и назвать рабочий лист Excel:
df.to_excel (r'C:\Users\Zach\Desktop\mydata.xlsx', sheet_name='this_data') Вот как выглядит фактический файл Excel:
Полную документацию по функции to_excel() можно найти здесь .