- Графы: разные виды представления графов. Алгоритмы Дейкстры и Флойда: реализация на Python. Минимальное остовное дерево
- Поиск в ширину — ПВШ (Breadth First Search — BFS)
- Поиск кратчайших путей в графах (объединение разделов по Дейкстре и Флойду)
- Алгоритм Дейкстры
- Алгоритм Флойда
- Алгоритм Прима
- Реализуем алгоритм поиска в глубину
- Алгоритм поиска в глубину
- Пример реализации поиска в глубину
- Псевдокод поиска в глубину (рекурсивная реализация)
- Реализация поиска в глубину на Python, Java и C/C++
- Сложность алгоритма поиска в глубину
- Применения алгоритма
Графы: разные виды представления графов. Алгоритмы Дейкстры и Флойда: реализация на Python. Минимальное остовное дерево
Метод обхода графа при котором в первую очередь переход делается из последней посещённой вершины (вершины хранятся в стеке). Обход в глубину получается естественным образом при рекурсивном обходе графа.
# Смежность вершин inc = < 1: [2, 8], 2: [1, 3, 8], 3: [2, 4, 8], 4: [3, 7, 9], 5: [6, 7], 6: [5], 7: [4, 5, 8], 8: [1, 2, 3, 7], 9: [4], >visited = set() # Посещена ли вершина? # Поиск в глубину - ПВГ (Depth First Search - DFS) def dfs(v): if v in visited: # Если вершина уже посещена, выходим return visited.add(v) # Посетили вершину v for i in inc[v]: # Все смежные с v вершины if not i in visited: dfs(i) start = 1 dfs(start) # start - начальная вершина обхода print(visited)
Поиск в ширину — ПВШ (Breadth First Search — BFS)
Метод обхода графа при котором в первую очередь переход делается из первой вершины, из которой мы ещё не ходили (вершины хранятся в очереди). Обход в глубину получается естественным образов при рекурсивном обходе графа.
Порядок обхода вершин при поиске в ширину

# Смежность вершин inc = < 1: [2, 8], 2: [1, 3, 8], 3: [2, 4, 8], 4: [3, 7, 9], 5: [6, 7], 6: [5], 7: [4, 5, 8], 8: [1, 2, 3, 7], 9: [4], >visited = set() # Посещена ли вершина? Q = [] # Очередь BFS = [] # Поиск в ширину - ПВШ (Breadth First Search - BFS) def bfs(v): if v in visited: # Если вершина уже посещена, выходим return visited.add(v) # Посетили вершину v BFS.append(v) # Запоминаем порядок обхода # print("v = %d" % v) for i in inc[v]: # Все смежные с v вершины if not i in visited: Q.append(i) while Q: bfs(Q.pop(0)) start = 1 bfs(start) # start - начальная вершина обхода print(BFS) # Выводится: [1, 2, 8, 3, 7, 4, 5, 9, 6] Поиск кратчайших путей в графах (объединение разделов по Дейкстре и Флойду)
Алгоритм Дейкстры
Алгоритм Дейкстры (Dijkstra’s algorithm) — алгоритм на графах, находящий кратчайшее расстояние от одной из вершин графа до всех остальных. Алгоритм работает только для графов без рёбер отрицательного веса (без рёбер с отрицательной «длиной»).
Примеры формулировки задачи
Вариант 1. Дана сеть автомобильных дорог, соединяющих города. Некоторые дороги односторонние. Найти кратчайшие пути от заданного города до каждого другого города (если двигаться можно только по дорогам).
Вариант 2. Имеется некоторое количество авиарейсов между городами мира, для каждого известна стоимость. Стоимость перелёта из A в B может быть не равна стоимости перелёта из B в A. Найти маршрут минимальной стоимости (возможно, с пересадками) от Копенгагена до Барнаула.
Идея алгоритма Дейкстры
Алгоритм состоит и 2 повторяющихся шагов:
- Добавление новой вершины («Расти» — GROW)
- «Релаксация», т.е. пересчёт расстояний до других вершин с учётом добавленной вершины (RELAX).
Обозначения:
Граф $G = (V,E)$, где $V$ — вершины, $E$ — рёбра.
$v_0$ — начальная вершина (от которой мы ищем кратчайшее растояние до всех остальных)
$R_i$ — известное нам расстояние от вершиеы $v_0$ до вершины $i$-ой.
$D$ — множество вершин до которых мы знаем кратчайшее расстояние от $v_0$.
Граф $G=(V,E)$, где $V$ — вершины, $E$ — рёбра.
$R_i$ — кратчайщее расстояние от $v_0$ до $i$-ой вершины
Инициализация алгоритма:
$R_ = 0$ — расстояние от $v_0$ до $v_0$ = 0.
$v = v_0$ — расти будем от вершины $v$.
Повторять (общий шаг алгоритма)
$GROW(V/D,v)$ — Добавляем вершину $v$ из множества $V/D$ в множество $D$.
$RELAX(V/D,v)$ — пробегаем достижимые из $v$ вершины до которых мы ещё не знаем кратчайшее расстояние и обновляем расстояния $R_i$ от вершины $v$.
$v$ — вершина с минимальным $R$ из множества $V/D$.
Каждой вершине $v$ из $V$ сопоставим значение $a[v]$ — минимальное известное расстояние от этой вершины до начальной $s$. Алгоритм работает пошагово — на каждом шаге он рассматривает одну вершину и пытается улучшить текущее расстояние до этой вершины. Работа алгоритма завершается, когда все вершины посещены, либо когда вычислены расстояния до всех вершин, достижимых из начальной.
Инициализация. Значение $a[s]$ самой начальной вершины полагается равным 0, значение остальных вершин — бесконечности (в программировании это реализуется присваиванием большого, к примеру, максимально возможного для данного типа, значения). Это отражает то, что расстояния от $s$ до других вершин пока неизвестны.
Шаг алгоритма. Если все вершины посещены, алгоритм завершается. В противном случае, из ещё не посещённых вершин выбирается вершина v, имеющая минимальное расстояние от начальной вершины $s$ и добавляется в список посещенных. Эта вершина находится, используя перебор всех непосещенных вершин. При этом суммируется расстояние от старта до одной из посещенных вершин u до непосещенной $v$. Для первого шага $s$ — единственная посещенная вершина с расстоянием от старта (то есть от себя самой), равным 0.
const MaxN = 1000; < Максимальное количество вершин >var a : array [1..MaxN] of extended; < Найденные кратчайшие расстояния >b : array [1..MaxN] of boolean; < Вычислено ли кратчайшее расстояние до вершины >p : array [1..MaxN,1..MaxN] of extended; < Матрица смежности >begin < До всех вершин расстояние - бесконечность >for i := 1 to n do a[i] := Inf; a[s] := 0.0; < И только до начальной вершины расстояние 0 >for i := 1 to n do b[i] := false; < Ни до одной вершины мы ещё не нашли кратчайшее расстояние >j := s; < Добавляемая вершина (стартовая) >repeat l := j; b[l] := True; < Добавили вершину > < Оббегаем все вершины смежные с только что добавленной >min := Inf; < Будем искать вершину с минимальным расстоянием от стартовой >for i := 1 to n do if not b[i] then begin < Если есть путь короче чем известный в i-ую вершину через l-тую, то запоминаем его >if a[i] < a[l] + p[l][i] then a[i] := a[l] + p[l][i]; < Если расстояние в эту вершину минимально, то запоминаем её как следующий кандидат на добавление >if a[i] < min then begin min := a[i]; j := i; end; end; until min = Inf; for i := 1 to n do if a[i] >= Inf then write('-1 ') < Вершины нельзя достичь из начальной >else write(a[i],' '); < Расстояние от начальной вершины = a[i] >end; Алгоритм Флойда
Алгоритм Флойда — Уоршелла — динамический алгоритм для нахождения кратчайших расстояний между всеми вершинами взвешенного ориентированного графа. Разработан в 1962 году Робертом Флойдом и Стивеном Уоршеллом.
Пусть вершины графа пронумерованы от 1 до $n$ и введено обозначение $d_^k$ для длины кратчайшего пути от $i$ до $j$, который кроме самих вершин $i,\; j$ проходит только через вершины $1 \ldots k$. Очевидно, что $d_^$ — длина (вес) ребра $(i,\;j)$, если таковое существует (в противном случае его длина может быть обозначена как $\infty$)
Существует два варианта значения $d_^,\;k \in \mathbb (1,\;\ldots,\;n)$:
- Кратчайший путь между $i,\;j$ не проходит через вершину $k$, тогда $d_^=d_^$
- Существует более короткий путь между $i,\;j$, проходящий через $k$, тогда он сначала идёт от $i$ до $k$, а потом от $k$ до $j$. В этом случае, очевидно, $d_^=d_^ + d_^$
Таким образом, для нахождения значения функции достаточно выбрать минимум из двух обозначенных значений.
Алгоритм Флойда — Уоршелла последовательно вычисляет все значения $d_^$, $\forall i,\; j$ для $k$ от 1 до $n$. Полученные значения $d_^$ являются длинами кратчайших путей между вершинами $i,\; j$.
for k := 1 to n do < k - промежуточная вершина >for i := 1 to n do < из i-ой вершины >for j := 1 to n do < в j-ую вершину >W[i][j] = min(W[i][j], W[i][k] + W[k][j]);
Алгоритм Прима
Алгоритм Прима — алгоритм построения минимального остовного дерева взвешенного связного неориентированного графа. Алгоритм впервые был открыт в 1930 году чешским математиком Войцехом Ярником, позже переоткрыт Робертом Примом в 1957 году, и, независимо от них, Э. Дейкстрой в 1959 году.
Построение начинается с дерева, включающего в себя одну (произвольную) вершину. В течение работы алгоритма дерево разрастается, пока не охватит все вершины исходного графа. На каждом шаге алгоритма к текущему дереву присоединяется самое лёгкое из рёбер, соединяющих вершину из построенного дерева, и вершину не из дерева.
Вход: Связный неориентированный граф $G(V,E)$
Выход: Множество $T$ рёбер минимального остовного дерева
Обозначения:
- $d_i$ — расстояние от $i$-й вершины до построенной части дерева
- $p_i$ — предок $i$-й вершины, то есть такая вершина $u$, что $(i,u)$ самое короткое рёбро соединяющее $i$ с вершиной из построенного дерева.
- $w(i,j)$ — вес ребра $(i,j)$
- $Q$ — приоритетная очередь вершин графа, где ключ — $d_i$
- $T$ — множество ребер минимального остовного дерева
Для каждой вершины $i \in V$: $d_i \gets \infty$, $p_i \gets nil$
Для каждой вершины $u$ смежной с $v$:
Реализуем алгоритм поиска в глубину

В этом туториале описан алгоритм поиска в глубину (depth first search, DFS) с псевдокодом и примерами. Кроме того, расписаны способы реализации поиска в глубину в C, Java, Python и C++.
“Поиск в глубину” или “обход в глубину” — это рекурсивный алгоритм по поиску всех вершин графа или дерева. Обход подразумевает под собой посещение всех вершин графа.
Алгоритм поиска в глубину
Стандартная реализация поиска в глубину помещает каждую вершину (узел, node) графа в одну из двух категорий:
Цель алгоритма состоит в том, чтобы пометить каждую вершину как “Пройденная”, избегая при этом циклов.
Алгоритм поиска в глубину работает следующим образом:
- Начните с того, что поместите любую вершину графа на вершину стека.
- Возьмите верхний элемент стека и добавьте его в список “Пройденных”.
- Создайте список смежных вершин для этой вершины. Добавьте те вершины, которых нет в списке “Пройденных”, в верх стека.
- Необходимо повторять шаги 2 и 3, пока стек не станет пустым.
Пример реализации поиска в глубину
Предлагаю рассмотреть на примере, как работает алгоритм поиска в глубину. Мы будем использовать неориентированный граф с пятью вершинами.

Начнем мы с вершины “0”. В первую очередь алгоритм поиска в глубину поместит ее саму в список “Пройденные” (на изображении “Visited”), а ее смежные вершины — в стек.
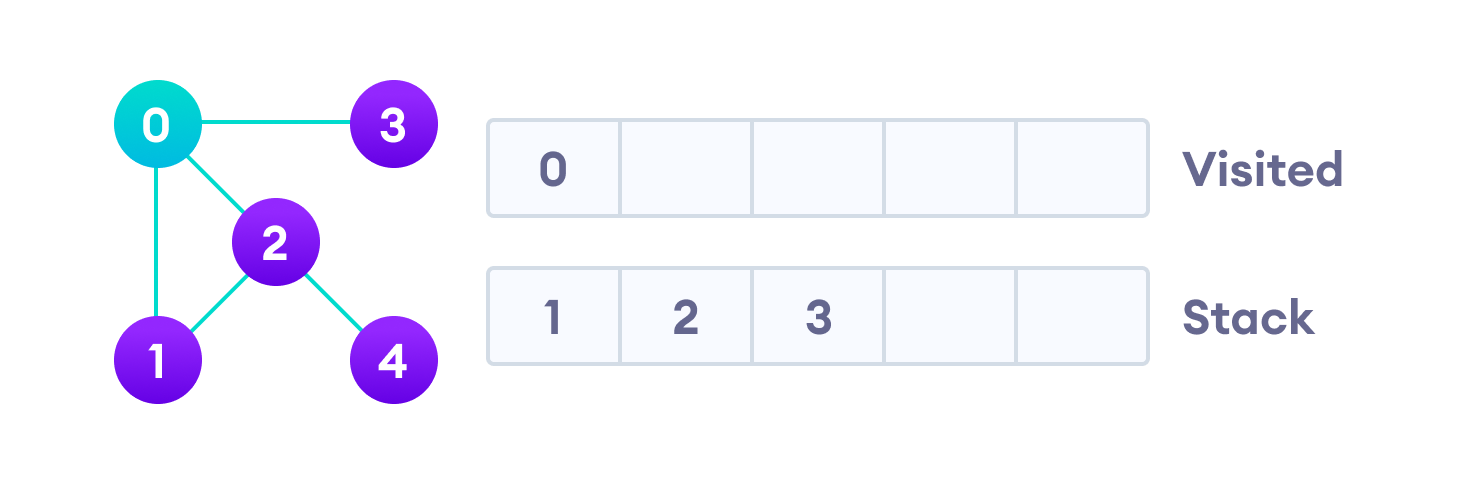
Затем мы берем следующий элемент сверху стека, т.е. к вершину “1”, и переходим к ее соседним вершинам. Поскольку вершина “0” уже пройдена, следующая вершина “2”.
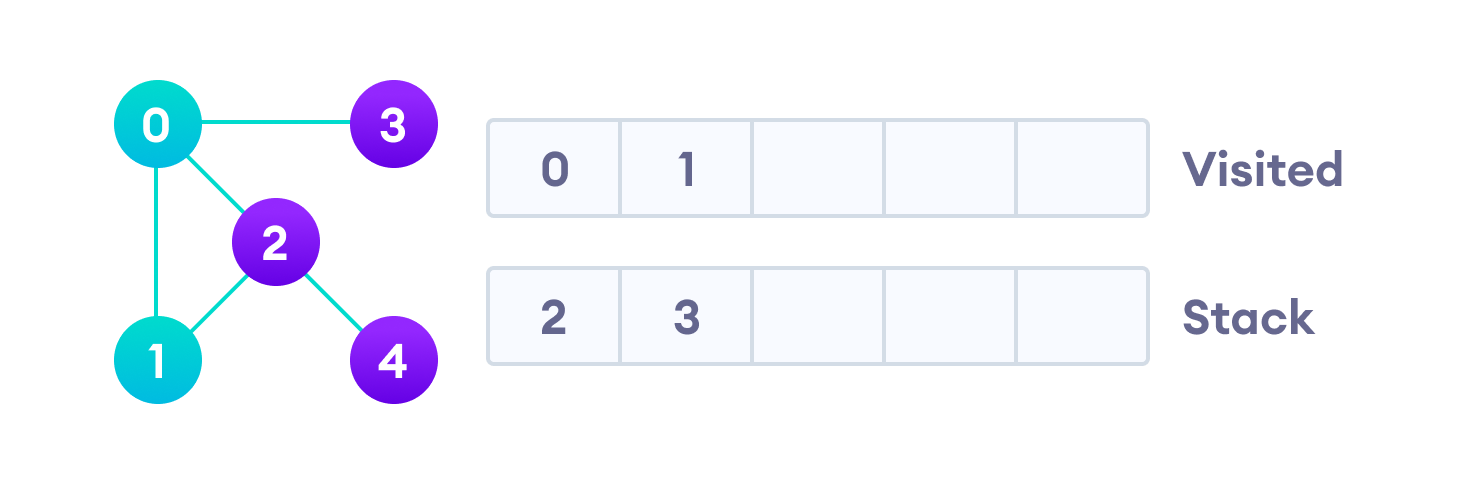
Вершина “2” смежна непройденной вершине “4”, следовательно мы добавляем ее наверх стека и проходим ее.
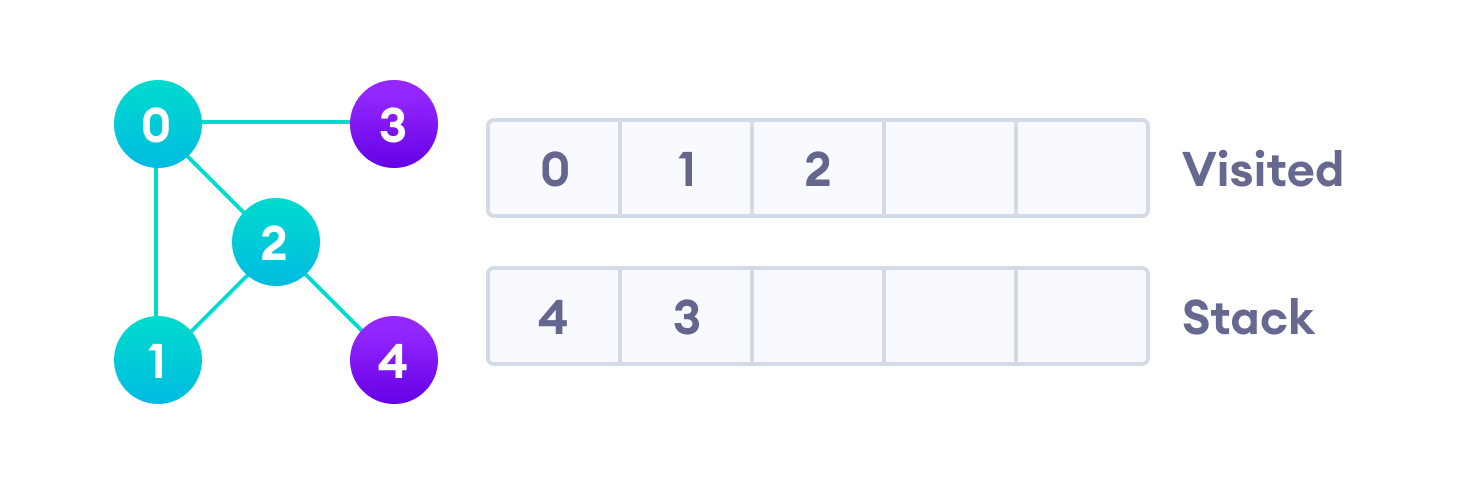

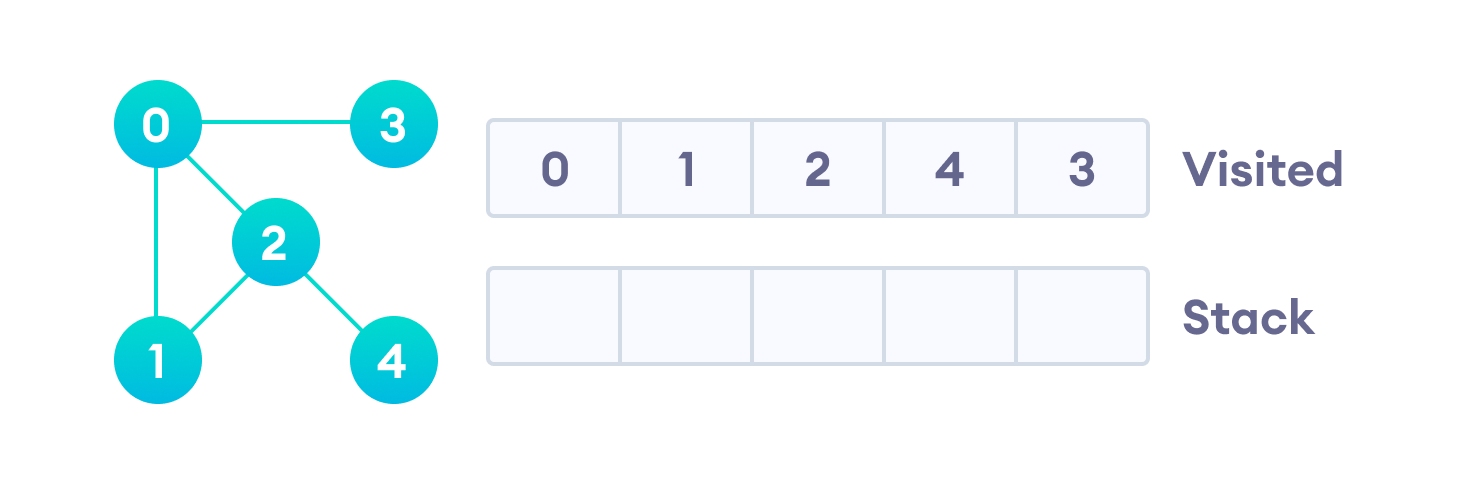
После того, как мы пройдем последний элемент (вершину “3”), в стеке не останется непройденных смежных вершин, и таким образом мы завершили обход графа в глубину.
Псевдокод поиска в глубину (рекурсивная реализация)
Ниже представлен псевдокод для алгоритма поиска в глубину. Обратите внимание, что в функции init() необходимо запускать функцию DFS на каждой вершине. Это связано с тем, что граф может иметь две разные несвязанные части, поэтому для того, чтобы убедиться, что мы покрываем каждую вершину, мы должны запускать алгоритм поиска в глубину на каждой вершине.
DFS(G, u) u.visited = true for each v ∈ G.Adj[u] if v.visited == false DFS(G,v) init()
Реализация поиска в глубину на Python, Java и C/C++
Ниже приведены примеры реально кода алгоритма поиска в глубину. Код был упрощен, чтобы мы могли сфокусироваться на самом алгоритме, а не на других деталях.
# Алгоритм поиска в глубину на Python # Алгоритм def dfs(graph, start, visited=None): if visited is None: visited = set() visited.add(start) print(start) for next in graph[start] - visited: dfs(graph, next, visited) return visited graph = dfs(graph, '0')// Алгоритм поиска в глубину на Java import java.util.*; class Graph < private LinkedListadjLists[]; private boolean visited[]; // Создание графа Graph(int vertices) < adjLists = new LinkedList[vertices]; visited = new boolean[vertices]; for (int i = 0; i < vertices; i++) adjLists[i] = new LinkedList(); > // Добавление ребер void addEdge(int src, int dest) < adjLists[src].add(dest); >// Алгоритм void DFS(int vertex) < visited[vertex] = true; System.out.print(vertex + " "); Iteratorite = adjLists[vertex].listIterator(); while (ite.hasNext()) < int adj = ite.next(); if (!visited[adj]) DFS(adj); >> public static void main(String args[]) < Graph g = new Graph(4); g.addEdge(0, 1); g.addEdge(0, 2); g.addEdge(1, 2); g.addEdge(2, 3); System.out.println("Following is Depth First Traversal"); g.DFS(2); >> // Алгоритм поиска в глубину на C #include #include struct node < int vertex; struct node* next; >; struct node* createNode(int v); struct Graph < int numVertices; int* visited; // Нам нужен int** для хранения двумерного массива. // Аналогично, нам нужна структура node** для хранения массива связанных списков. struct node** adjLists; >; // Алгоритм void DFS(struct Graph* graph, int vertex) < struct node* adjList = graph->adjLists[vertex]; struct node* temp = adjList; graph->visited[vertex] = 1; printf("Visited %d \n", vertex); while (temp != NULL) < int connectedVertex = temp->vertex; if (graph->visited[connectedVertex] == 0) < DFS(graph, connectedVertex); >temp = temp->next; > > // Создание вершины struct node* createNode(int v) < struct node* newNode = malloc(sizeof(struct node)); newNode->vertex = v; newNode->next = NULL; return newNode; > // Создание графа struct Graph* createGraph(int vertices) < struct Graph* graph = malloc(sizeof(struct Graph)); graph->numVertices = vertices; graph->adjLists = malloc(vertices * sizeof(struct node*)); graph->visited = malloc(vertices * sizeof(int)); int i; for (i = 0; i < vertices; i++) < graph->adjLists[i] = NULL; graph->visited[i] = 0; > return graph; > // Добавление ребра void addEdge(struct Graph* graph, int src, int dest) < // Проводим ребро от начальной вершины ребра графа к конечной вершине ребра графа struct node* newNode = createNode(dest); newNode->next = graph->adjLists[src]; graph->adjLists[src] = newNode; // Проводим ребро из конечной вершины ребра графа в начальную вершину ребра графа newNode = createNode(src); newNode->next = graph->adjLists[dest]; graph->adjLists[dest] = newNode; > // Выводим граф void printGraph(struct Graph* graph) < int v; for (v = 0; v < graph->numVertices; v++) < struct node* temp = graph->adjLists[v]; printf("\n Adjacency list of vertex %d\n ", v); while (temp) < printf("%d ->", temp->vertex); temp = temp->next; > printf("\n"); > > int main() // Алгоритм прохода в глубину в C++ #include #include using namespace std; class Graph < int numVertices; list*adjLists; bool *visited; public: Graph(int V); void addEdge(int src, int dest); void DFS(int vertex); >; // Инициализация графа Graph::Graph(int vertices) < numVertices = vertices; adjLists = new list[vertices]; visited = new bool[vertices]; > // Добавление ребер void Graph::addEdge(int src, int dest) < adjLists[src].push_front(dest); >// Алгоритм void Graph::DFS(int vertex) < visited[vertex] = true; listadjList = adjLists[vertex]; cout << vertex << " "; list::iterator i; for (i = adjList.begin(); i != adjList.end(); ++i) if (!visited[*i]) DFS(*i); > int main()
Сложность алгоритма поиска в глубину
Временная сложность алгоритма поиска в глубину представлена в виде O(V + E), где V — количество вершин, а E — количество ребер.
Пространственная сложность алгоритма равна O(V).
Применения алгоритма
- Для поиска пути.
- Для проверки двудольности графа.
- Для поиска сильно связанных компонентов графа.
- Для обнаружения циклов в графе.
Приглашаем всех желающих на открытый урок в OTUS «Теория графов. Термины и определения. Основные алгоритмы», регистрация доступна по ссылке.