- Python Pandas Tutorial: A Complete Introduction for Beginners
- You should already know:
- Article Resources
- Other articles in this series
- What’s Pandas for?
- How does pandas fit into the data science toolkit?
- When should you start using pandas?
- Pandas First Steps
- Install and import
- Core components of pandas: Series and DataFrames
- Creating DataFrames from scratch
- pandas
- Latest version: 2.0.3
- Follow us
- Get the book
- Previous versions
Python Pandas Tutorial: A Complete Introduction for Beginners
Learn some of the most important pandas features for exploring, cleaning, transforming, visualizing, and learning from data.
You should already know:
- Python fundamentals – you should have beginner to intermediate-level knowledge, which can be learned from most entry-level Python courses
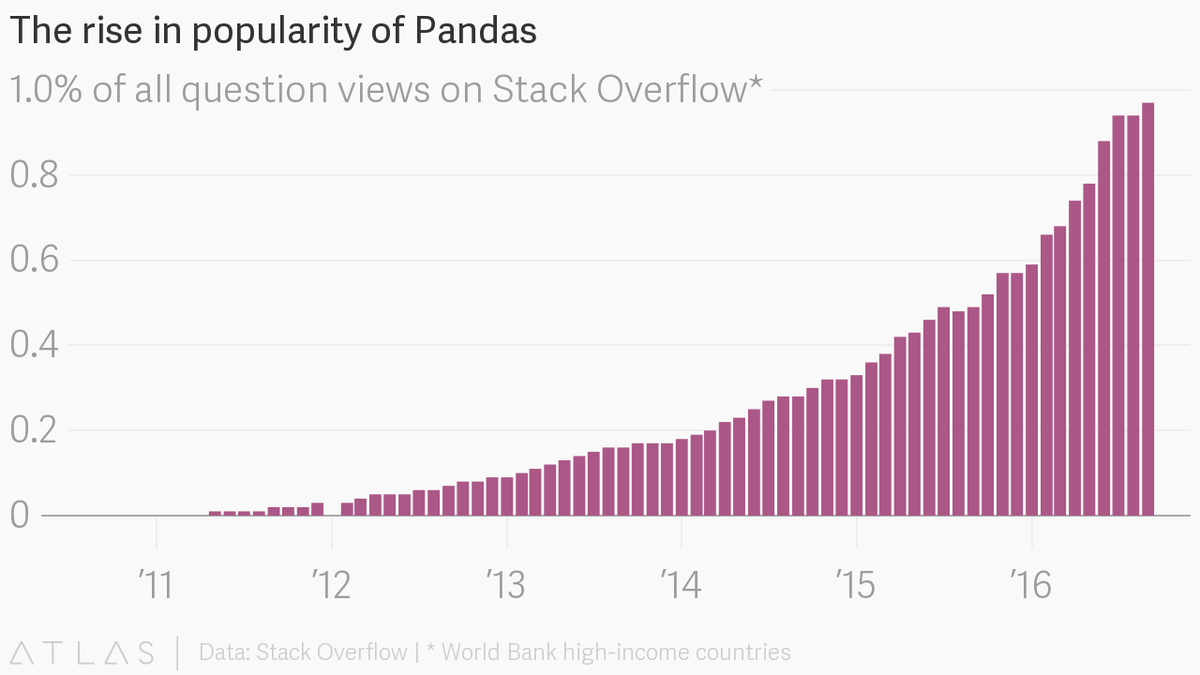
The pandas package is the most important tool at the disposal of Data Scientists and Analysts working in Python today. The powerful machine learning and glamorous visualization tools may get all the attention, but pandas is the backbone of most data projects.
[pandas] is derived from the term «panel data», an econometrics term for data sets that include observations over multiple time periods for the same individuals. — Wikipedia
If you’re thinking about data science as a career, then it is imperative that one of the first things you do is learn pandas. In this post, we will go over the essential bits of information about pandas, including how to install it, its uses, and how it works with other common Python data analysis packages such as matplotlib and scikit-learn.
Article Resources
Other articles in this series
What’s Pandas for?
Pandas has so many uses that it might make sense to list the things it can’t do instead of what it can do.
This tool is essentially your data’s home. Through pandas, you get acquainted with your data by cleaning, transforming, and analyzing it.
For example, say you want to explore a dataset stored in a CSV on your computer. Pandas will extract the data from that CSV into a DataFrame — a table, basically — then let you do things like:
- Calculate statistics and answer questions about the data, like
- What’s the average, median, max, or min of each column?
- Does column A correlate with column B?
- What does the distribution of data in column C look like?
Before you jump into the modeling or the complex visualizations you need to have a good understanding of the nature of your dataset and pandas is the best avenue through which to do that.

How does pandas fit into the data science toolkit?
Not only is the pandas library a central component of the data science toolkit but it is used in conjunction with other libraries in that collection.
Pandas is built on top of the NumPy package, meaning a lot of the structure of NumPy is used or replicated in Pandas. Data in pandas is often used to feed statistical analysis in SciPy, plotting functions from Matplotlib, and machine learning algorithms in Scikit-learn.
Jupyter Notebooks offer a good environment for using pandas to do data exploration and modeling, but pandas can also be used in text editors just as easily.
Jupyter Notebooks give us the ability to execute code in a particular cell as opposed to running the entire file. This saves a lot of time when working with large datasets and complex transformations. Notebooks also provide an easy way to visualize pandas’ DataFrames and plots. As a matter of fact, this article was created entirely in a Jupyter Notebook.
When should you start using pandas?
If you do not have any experience coding in Python, then you should stay away from learning pandas until you do. You don’t have to be at the level of the software engineer, but you should be adept at the basics, such as lists, tuples, dictionaries, functions, and iterations. Also, I’d also recommend familiarizing yourself with NumPy due to the similarities mentioned above.
If you’re looking for a good place to learn Python, Python for Everybody on Coursera is great (and Free).
Moreover, for those of you looking to do a data science bootcamp or some other accelerated data science education program, it’s highly recommended you start learning pandas on your own before you start the program.
Even though accelerated programs teach you pandas, better skills beforehand means you’ll be able to maximize time for learning and mastering the more complicated material.
Pandas First Steps
Install and import
Pandas is an easy package to install. Open up your terminal program (for Mac users) or command line (for PC users) and install it using either of the following commands:
Alternatively, if you’re currently viewing this article in a Jupyter notebook you can run this cell:
The ! at the beginning runs cells as if they were in a terminal.
To import pandas we usually import it with a shorter name since it’s used so much:
Now to the basic components of pandas.
Core components of pandas: Series and DataFrames
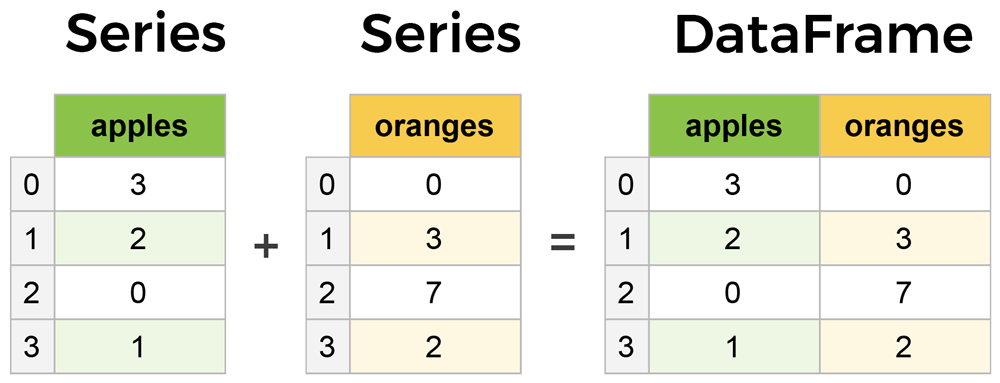
The primary two components of pandas are the Series and DataFrame .
A Series is essentially a column, and a DataFrame is a multi-dimensional table made up of a collection of Series.
DataFrames and Series are quite similar in that many operations that you can do with one you can do with the other, such as filling in null values and calculating the mean.
You’ll see how these components work when we start working with data below.
Creating DataFrames from scratch
Creating DataFrames right in Python is good to know and quite useful when testing new methods and functions you find in the pandas docs.
There are many ways to create a DataFrame from scratch, but a great option is to just use a simple dict .
Let’s say we have a fruit stand that sells apples and oranges. We want to have a column for each fruit and a row for each customer purchase. To organize this as a dictionary for pandas we could do something like:
And then pass it to the pandas DataFrame constructor:
pandas
pandas is a fast, powerful, flexible and easy to use open source data analysis and manipulation tool,
built on top of the Python programming language.Getting started
Documentation
Community
With the support of:
The full list of companies supporting pandas is available in the sponsors page.
Latest version: 2.0.3
Follow us
Get the book
Previous versions
- 2.0.2 (May 28, 2023)
changelog | docs | code - 2.0.1 (Apr 24, 2023)
changelog | docs | code - 2.0.0 (Apr 03, 2023)
changelog | docs | code - 1.5.3 (Jan 19, 2023)
changelog | docs | code
- 1.5.2 (2022-11-22)
changelog | docs | code - 1.5.1 (2022-10-19)
changelog | docs | code - 1.5.0 (2022-09-19)
changelog | docs | code - 1.4.4 (2022-08-31)
changelog | docs | code - 1.4.3 (2022-06-23)
changelog | docs | code - 1.4.2 (2022-04-02)
changelog | docs | code - 1.4.1 (2022-02-12)
changelog | docs | code - 1.4.0 (2022-01-22)
changelog | docs | code - 1.3.5 (2021-12-12)
changelog | docs | code - 1.3.4 (2021-10-17)
changelog | docs | code - 1.3.3 (2021-09-12)
changelog | docs | code - 1.3.2 (2021-08-15)
changelog | docs | code - 1.3.1 (2021-07-25)
changelog | docs | code - 1.3.0 (2021-07-02)
changelog | docs | code - 1.2.5 (2021-06-22)
changelog | docs | code - 1.2.4 (2021-04-12)
changelog | docs | code - 1.2.3 (2021-03-02)
changelog | docs | code - 1.2.2 (2021-02-09)
changelog | docs | code - 1.2.1 (2021-01-20)
changelog | docs | code - 1.2.0 (2020-12-26)
changelog | docs | code
© 2023 pandas via NumFOCUS, Inc. Hosted by OVHcloud.