- Как использовать символы Unicode в CSS
- Использование символов Unicode в свойстве Content
- Пример использования свойства Content
- Пример использования символов Unicode в свойстве Content
- Некоторые символы Unicode
- Using Unicode And Special Characters Within The content Property In CSS
- Why Not Just Include Unicode Characters in the Code File?
- Enjoyed This Post? ❤️ Share the Love With Your Friends! ❤️
- You Might Also Enjoy Some of My Other Posts
- Reader Comments
- Post A Comment — ❤️ I’d Love To Hear From You! ❤️
- Css unicode content
- Answer by Dakota Meyer
- Answer by Jeremias Le
- Answer by Edgar Rollins
Как использовать символы Unicode в CSS
Для использования символов Unicode в CSS первым делом нужно объявить соответствующую кодировку; рекомендуется UTF-8. Это делается с помощью так называемого эт-правила @charset в самом начале файла, то есть первой строкой:
Синтаксис: сначала указывается @charset ; затем — ровно ОДИН пробел; затем — имя кодировки в ДВОЙНЫХ кавычках; затем — точка с запятой. Синтаксис должен быть точно таким, как указан здесь, Это ВАЖНО, так как иначе будет ошибка. То есть нельзя использовать между @charset и названием кодировки больше или меньше одного пробела; нельзя заключать имя кодировки в одинарные кавычки; обязательно нужно ставить точку с запятой в конце; также ничего нельзя писать ПЕРЕД @charset , включая комментарии, то есть первым символом в файле должен быть «эт» (@; «собака», по-нашему).
Однако одного обявления кодировки мало: нужно чтобы и само содержимое файла стилей было закодировано в объявленой кодировке. Что это значит.
Эт-правилом @charset мы просто указываем браузеру какой алгоритм кодирования ему нужно использовать, чтобы правильно прочесть содержимое файла, однако само содержимое может быть закодировано по другому алгоритму и тогда, как вы понимаете, браузер обработает файл некорректно. Обычно в большинстве редакторов кода текущая кодировка файла вместе с другой полезной информацией отображается в строке статуса (в нижней части окна), а изменить её можно через меню — эта возможность есть, поищите; описывать в данном посте где именно она находится для всех редакторов, коих сотни, а то и тысячи, по понятным причинам я не стал; если не найдёте, напишите мне — я вам подскажу.
Если вы будете изменять кодировку файла, то учтите, что в некоторых редакторах может быть два пункта меню, которые могут сбить вас с толку: Кодировать в
.
Преобразовать в Нужно выбрать именно Преобразовать в .
На самом деле указывать кодировку в файле стилей необязательно ЕСЛИ она обявлена в HTML-документе, но ещё раз напомню: кодировка содержимого файла должна совпадать с объявленной. Это, кстати, касается не только CSS, но и абсолютно любых других областей — ведь если вы говорите, что следующие данные нужно обработать по алгоритму указанной кодировки, то вы же и должны предоставить закодированные этим же алгоритмом данные.
Я так заостряю ваше внимание на том, что помимо объявления кодировки нужно чтобы и данные были в той же кодировке, так как на этом очень часто спотыкаются и не понимают почему всё в кракозябрах.
Тем не менее, хоть и кодировку в файле стилей объявлять необязательно ЕСЛИ она обявлена в HTML-документе, как я уже сказал выше, всё равно лучше это сделать, так как мало ли что ☺:
Рекомендую ВСЕГДА ВЕЗДЕ объявлять кодировки и использовать, по крайней мере в Web’е, именно UTF-8!
Использование символов Unicode в свойстве Content
Рассмотрим CSS-свойство content , которое используется совместно с псевдоэлементами ::before и ::after . В данном свойстве указывается контент, который будет помещён перед или после элемента, к которому применяется соответствующий псевдоэлемент:
selector::before, selector::after < content: "строка"; >строка любой набор символов, который выводится как есть, кроме экранированных последовательнойстей (см. далее).
Пример использования свойства Content
Контент, добавленный с помощью свойства content не выделяется курсором мыши и не копируется в буфер обмена.
Пример использования символов Unicode в свойстве Content
Допустим, нужно вывести с помощью свойства content после некоторого элемента смайлик (☺), который имеет номер в Unicode u+263a ; это запишется так:
То есть номер символа в Unicode нужно просто проэкранировать обратным слешем (\).
Также отмечу — впередистоящие нули можно не указывать: \0030 идентично \30 .
Второй способ — это указать символ непосредственно:
Чтобы добавляемые через content пробельные символы Unicode (пробелы, табуляции и переводы строк) отображались как есть (имеется в виду предварительное форматирование), для элемента должно быть определено свойство white-space со значением pre или подобным ему.
Некоторые символы Unicode
| # | Название по-русски | Название по-английски | Вид | Мнемоника | HTML-код | Unicode |
|---|---|---|---|---|---|---|
| 1 | Горизонтальная табуляция | Horizontal Tabulation | u+0009 | |||
| 2 | Перевод строки (разделитель строк в Unix) | New Line (Nl) | u+000a | |||
| 3 | Вертикальная табуляция | Vertical Tabulation | u+000b | |||
| 4 | Пробел | Space | u+0020 | |||
| 5 | Двойная кавычка (универсальная) | Quotation Mark | « | " | " | u+0022 |
| 6 | Амперсанд | Ampersand | & | & | & | u+0026 |
| 7 | Апостроф (одинарная кавычка) | Apostrophe | ‘ | ' | ' | u+0027 |
| 8 | Знак меньше | Less-Than Sign | < | < | u+003c | |
| 9 | Знак больше | Greater-Than Sign | > | > | > | u+003e |
| 10 | Неразрывный пробел | No-Break Space | u+00a0 |
К слову, заметим, что мнемоники (частично) соответствуют названию символа по-английски; пример: — N o- B reak SP ace.
Using Unicode And Special Characters Within The content Property In CSS
I’m in love with the Right Arrow character. That’s the HTML entity, → , or the Unicode character U+02192 . It renders like this (→). I’ve started to use it a lot with various calls-to-action in my user interface (UI). But, I don’t always want it to be part of the DOM (Document Object Model) since it’s just decorative. So, I sometimes define it in the CSS using the content property of a pseudo element. But, I can never freaking remember the proper escape sequence for Unicode. As such, I wanted to put this post together as a note to self that I can quickly look up the next time I can’t remember how to use Unicode and HTML entities within the content property in CSS.
To use Unicode in the content property, I need to use \ followed by the hexadecimal code point value. So, for the right arrow ( U+02192 ), I would use:
This Unicode escape sequence format appears to swallow any space character that immediately follows the code point. Meaning, if I wanted to include the Copyright character ( U+00A9 ) followed immediately by the year, I could do this:
The space between the Unicode escape and the «2022» year won’t be rendered — it’s there only to prevent the «2022» token from being interpreted as part of the Unicode escape. If I wanted to render a space, I’d have to include two spaces in the content property:
To see this in action, I’ve put together a small demo in which I use a few Emoji as part of the content property:
As a bonus note-to-self, I’m also attempting to use the Unicode values in a console.log() statement as well. And, when we run this in the browser we get the following output:
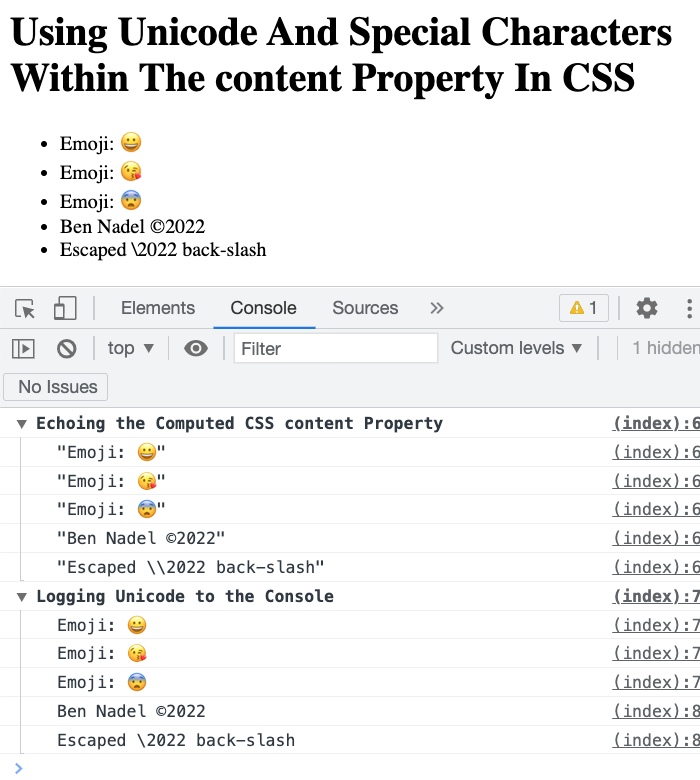
And there you have it! Unicode characters are being rendered in the DOM (Document Object Model) via the CSS content property by using the Unicode escape sequence. Hopefully, by writing this down, I won’t forget.
Why Not Just Include Unicode Characters in the Code File?
This may sound silly or anachronistic. And, maybe I’m just getting old. But, I don’t like having any characters in my code that I can’t represent with a key-stroke on the physical keyboard. I know that there are Unicode character keyboard utilities in Mac ( CMD+CTRL+Space ) and Windows; but, I feel emotionally constrained by my physical keyboard.
Want to use code from this post? Check out the license.
Enjoyed This Post? ❤️ Share the Love With Your Friends! ❤️
You Might Also Enjoy Some of My Other Posts
Reader Comments
I always enjoy your journeys into whatever corner of tech that sparks your interest. If you want to dive deeper into emoji (not the movie 😉) — I had a lot of fun looking at modifiers (works a bit like ligatures).
Here is a very simple pen that uses CSSVariables to hold the unicode values (it makes it a bit easier to use and remember)
All the best to you and Lucy 🤗
That’s a really cool CodePen! This is some next-level Emoji stuff. It took me years just to stop calling them «Emoticons» 🤪 Now, I «Emoji» at a 1st-grade level. Baby steps. But, this is really interesting. Is this a universal thing? Meaning, is this the way Emoji were originally designed to work? Or, is this platform-specific? I don’t know enough even about the concept of ligatures, but I believe the combination of characters is baked into the concept of how Unicode works, right? Like an «e» next to an accent character kind of thing.
Anyway, thank you for the kind words as well. Very interesting stuff!
Post A Comment — ❤️ I’d Love To Hear From You! ❤️
I believe in love. I believe in compassion. I believe in human rights. I believe that we can afford to give more of these gifts to the world around us because it costs us nothing to be decent and kind and understanding. And, I want you to know that when you land on this site, you are accepted for who you are, no matter how you identify, what truths you live, or whatever kind of goofy shit makes you feel alive! Rock on with your bad self!
I am the co-founder and a principal engineer at InVision App, Inc — the world’s leading online whiteboard and productivity platform powering the future of work. I also rock out in JavaScript and ColdFusion 24×7 and I dream about chained Promises resolving asynchronously.
Css unicode content
The general format for a Unicode character inside a string is \000000 to \FFFFFF – a backslash followed by six hexadecimal digits. You can leave out leading 0 digits when the Unicode character is the last character in the string or when you add a space after the Unicode character. See the spec below for full details.,If the number is outside the range allowed by Unicode (e.g., «\110000» is above the maximum 10FFFF allowed in current Unicode), the UA may replace the escape with the «replacement character» (U+FFFD). If the character is to be displayed, the UA should show a visible symbol, such as a «missing character» glyph (cf. 15.2, point 5).,by providing exactly 6 hexadecimal digits: «\000026B» («&B»), Stack Overflow for Teams Where developers & technologists share private knowledge with coworkers
Why don’t you just save/serve the CSS file as UTF-8?
If that’s not good enough, and you want to keep it all-ASCII:
Answer by Dakota Meyer
I want this apply css content code is period? plz let me know,I found an awesome list of Unicode symbols and dingbats that extend the list above… http://inamidst.com/stuff/unidata, nitesh Permalink to comment# March 10, 2016 I want this apply css content code is period? plz let me know Reply , Jon Permalink to comment# September 8, 2011 I found an awesome list of Unicode symbols and dingbats that extend the list above… http://inamidst.com/stuff/unidata Reply
Answer by Jeremias Le
Many of the little symbols that we regularly use as bullets, arrows, etc. already exist as unicode symbols. [[more intro]],Unicode.org Character Charts,Find the code for the symbol you would like to use, some useful links are:,If the example includes a «U+» replace that with a «» to get them to render correctly.
Answer by Edgar Rollins
You can use a character’s hexadecimal Unicode code point value in the CSS content property by escaping it (i.e. using a backslash followed by the character’s hexadecimal numeric sequence). , To add a Unicode character to the CSS content property, you can do either of the following: , You can add a Unicode character directly to the CSS content property, for example, like so: ,Use the Character’s Hexadecimal Unicode Code Point Value.
You can add a Unicode character directly to the CSS content property, for example, like so:
For example, the copyright symbol is represented as U+00A9 . To add it via the CSS content property, you would escape it like so:
By convention, an escaped hexadecimal number should be six characters long. Typically, to shorten it, leading zeros are omitted as they’re optional (as you can see in the example above). In case you opt for excluding the leading zeros, please remember to separate multiple words and/or character escapes by a space, such as in the following example:
If you don’t separate characters by space, then the characters in the range of A–F , a–f or 0–9 that follow an escaped character would be interpreted as a part of its number sequence. For example:
You could, of course, instead make the escape sequence six characters long and avoid having to add a space altogether like so: