Кодирование строк
Чтобы компьютер смог отобразить передаваемые ему символы, они должны быть представлены в конкретной кодировке. Навряд ли найдется человек, который никогда не сталкивался с кракозябрами: открываешь интернет-страницу, а там – набор непонятных знаков; хочешь прочесть книгу в текстовом редакторе, а вместо слов получаешь сплошные знаки вопроса. Причина заключается в неверной процедуре декодирования текста (если сильно упростить, то программа пытается представить американцу, например, букву «Щ», осуществляя поиск в английском алфавите).
Возникают вопросы: что происходит, кто виноват? Ответ не будет коротким.
1. Компьютер – человек
Так сложилось, что компьютерная техника оперирует единицами и нулями. На вашей же клавиатуре представлено не менее 100 клавиш. Все, что вы вводите при печати, в итоге преобразуется в те самые бинарные величины.
В этом суть кодировки. ПК запоминает любые буквы, числа и знаки в виде определенного значения из единиц и нулей. Для примера: английская буква «Y» в двоичном коде выглядит как «0b1011001» , а в шестнадцатеричном как «0x59» .
Для осмысленного диалога пользователя и компьютера требуется двусторонний переводчик:
– «человеческие» строки необходимо перекодировать в байты;
– «компьютерную» речь требуется преобразовать в воспринимаемые пользователем осмысленные структуры.
В языке Python за это отвечают функции encode / decode . Важно кодировать и декодировать сообщение в одинаковой кодировке, чтобы не столкнуться с проблемой бессмысленных наборов символов.
2. ASCII
Так как первые вычислительные машины были малоемкими, для представления в их памяти всего набора требуемых знаков хватало 7 бит (или 128 символов). Сюда входил весь английский алфавит в верхнем и нижнем регистрах, цифры, знаки, вспомогательные символы.

Поначалу этого вполне хватало. Кодировка получила имя ASCII (читается как «аски» или «эски»). В Пайтоне вы и сегодня можете посмотреть на символы ASCII. Для этого имеется встроенный модуль string .
import string print(string.ascii_letters) print(string.digits) print(string.punctuation) Результат выполнения кода abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ 0123456789 !"#$%&'()*+,-./:;?@[\]^_`<|>~ С другими свойствами модуля можете ознакомиться самостоятельно.
Время шло, компьютеризация общества ширилась, 128 символов стало не хватать. Оставшийся последний 8-ой бит также выделили для кодирования (а это еще 128 знаков). В итоге появилось большое количество кодировок (кириллическая, немецкая и т.п.). Такая ситуация привела к проблемам. Уже в то время англичанин, получающий электронное письмо из России, мог увидеть не русские буквы, а набор непонятных закорючек.
Потребовалось указание кодировок в заголовках документов.
3. Юникод-стандарт
Как вы считаете, сколько нужно символов, чтобы хватило всем и навсегда? 10_000? Конечно, нет. Уже сегодня более 100_000 знаков имеет свое числовое представление. И это не предел. Люди постоянно придумывают новые «буквы».
Откройте свой телефон и создайте пустое сообщение. Зайдите в раздел «смайликов». Да их тут больше сотни! И это не картинки в большинстве своем. Они являются символами определенной кодировки. Если вы застали времена, когда SMS-технологии только начинали развиваться, то этих самых «смайлов» было не более десятка. Лет через 10 их количество станет «неприличным».
Упомянутая выше кодировка ASCII в своем расширенном варианте породила большое количество новых. Основная беда: имея 128 вариантов обозначить символ, мы никак не сумеем внедрить туда буквы других языков. В частности, какой-нибудь символ под номером 201 в кириллице даст совсем не русскую букву, если отослать его в Румынию. Следовательно, говоря кому-то «посмотри на 201-ый символ» мы не даем никакой гарантии, что собеседник увидит то же.
Для решения задачи был разработан стандарт Unicode. Отметим, что это не определенная кодировка, а именно набор правил. Суть юникода – связь символа и определенного числа без возможного повторения. Если мы кого-то попросим показать символ, скрытый под номером «1000», то в любой точке планеты он будет одним и тем же графическим элементом.
Ascii can decode byte python
Last updated: Feb 18, 2023
Reading time · 3 min

# UnicodeDecodeError: ‘ascii’ codec can’t decode byte
The Python «UnicodeDecodeError: ‘ascii’ codec can’t decode byte in position» occurs when we use the ascii codec to decode bytes that were encoded using a different codec.
To solve the error, specify the correct encoding, e.g. utf-8 .
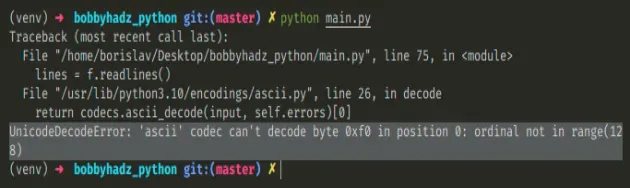
Here is an example of how the error occurs.
I have a file called example.txt with the following contents.
Copied!𝘈Ḇ𝖢𝕯٤ḞԍНǏ hello world
And here is the code that tries to decode the contents of example.txt using the ascii codec.
Copied!# ⛔️ UnicodeDecodeError: 'ascii' codec can't decode byte 0xf0 in position 0: ordinal not in range(128) with open('example.txt', 'r', encoding='ascii') as f: lines = f.readlines() print(lines)
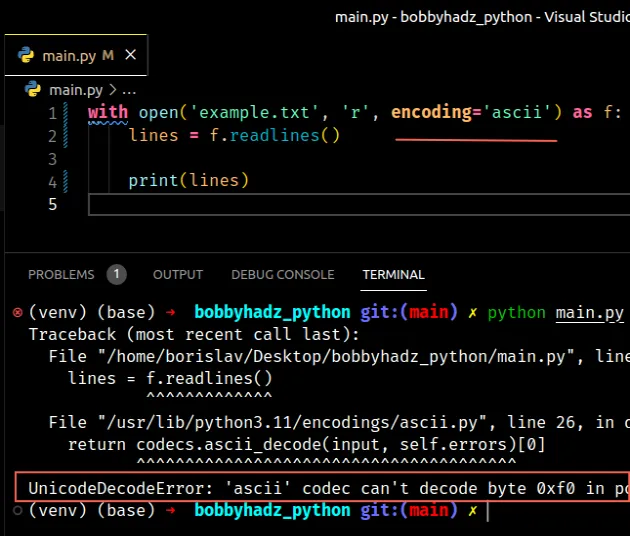
The error is caused because the example.txt file doesn’t use the ascii encoding.
Copied!𝘈Ḇ𝖢𝕯٤ḞԍНǏ hello world
If you know the encoding the file uses, make sure to specify it using the encoding keyword argument.
# Try setting the encoding to utf-8
Otherwise, the first thing you can try is setting the encoding to utf-8 .
Copied!# 👇️ set encoding to utf-8 with open('example.txt', 'r', encoding='utf-8') as f: lines = f.readlines() print(lines) # 👉️ ['𝘈Ḇ𝖢𝕯٤ḞԍНǏ\n', 'hello world']
You can view all of the standard encodings in this table of the official docs.
Encoding is the process of converting a string to a bytes object and decoding is the process of converting a bytes object to a string .
When decoding a bytes object, we have to use the same encoding that was used to encode the string to a bytes object.
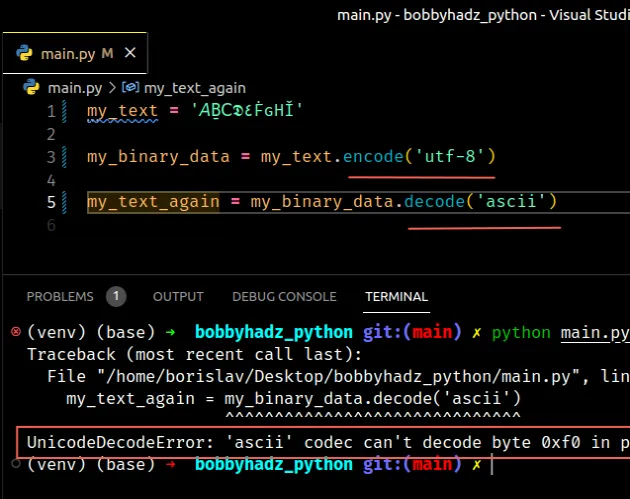
Here is an example that shows how using a different encoding to encode a string to bytes than the one used to decode the bytes object causes the error.
Copied!my_text = '𝘈Ḇ𝖢𝕯٤ḞԍНǏ' my_binary_data = my_text.encode('utf-8') # ⛔️ UnicodeDecodeError: 'ascii' codec can't decode byte 0xf0 in position 0: ordinal not in range(128) my_text_again = my_binary_data.decode('ascii')
We can solve the error by using the utf-8 encoding to decode the bytes object.
Copied!my_text = '𝘈Ḇ𝖢𝕯٤ḞԍНǏ' my_binary_data = my_text.encode('utf-8') # 👉️ b'\xf0\x9d\x98\x88\xe1\xb8\x86\xf0\x9d\x96\xa2\xf0\x9d\x95\xaf\xd9\xa4\xe1\xb8\x9e\xd4\x8d\xd0\x9d\xc7\x8f' print(my_binary_data) # ✅ specify correct encoding my_text_again = my_binary_data.decode('utf-8') print(my_text_again) # 👉️ '𝘈Ḇ𝖢𝕯٤ḞԍНǏ'
The code sample doesn’t cause an issue because the same encoding was used to encode the string into bytes and decode the bytes object into a string.
# Set the errors keyword argument to ignore
If you get an error when decoding the bytes using the utf-8 encoding, you can try setting the errors keyword argument to ignore to ignore the characters that cannot be decoded.
Copied!my_text = '𝘈Ḇ𝖢𝕯٤ḞԍНǏ' my_binary_data = my_text.encode('utf-8') # 👇️ set errors to ignore my_text_again = my_binary_data.decode('utf-8', errors='ignore') print(my_text_again)
Note that ignoring characters that cannot be decoded can lead to data loss.
Here is an example where errors is set to ignore when opening a file.
Copied!# 👇️ set errors to ignore with open('example.txt', 'r', encoding='utf-8', errors='ignore') as f: lines = f.readlines() # ✅ ['𝘈Ḇ𝖢𝕯٤ḞԍНǏ\n', 'hello world'] print(lines)
Opening the file with an incorrect encoding with errors set to ignore won’t raise an error.
Copied!with open('example.txt', 'r', encoding='ascii', errors='ignore') as f: lines = f.readlines() # ✅ ['\n', 'hello world'] print(lines)
The example.txt file doesn’t use the ascii encoding, however, opening the file with errors set to ignore doesn’t raise an error.
Copied!𝘈Ḇ𝖢𝕯٤ḞԍНǏ hello world
Instead, it ignores the data it cannot parse and returns the data it can parse.
# Make sure you aren’t mixing up encode() and decode()
Make sure you aren’t mixing up calls to the str.encode() and bytes.decode() method.
Encoding is the process of converting a string to a bytes object and decoding is the process of converting a bytes object to a string .
If you have a str that you want to convert to bytes, use the encode() method.
Copied!my_text = '𝘈Ḇ𝖢𝕯٤ḞԍНǏ' my_binary_data = my_text.encode('utf-8') # 👉️ b'\xf0\x9d\x98\x88\xe1\xb8\x86\xf0\x9d\x96\xa2\xf0\x9d\x95\xaf\xd9\xa4\xe1\xb8\x9e\xd4\x8d\xd0\x9d\xc7\x8f' print(my_binary_data) # ✅ specify correct encoding my_text_again = my_binary_data.decode('utf-8') print(my_text_again) # 👉️ '𝘈Ḇ𝖢𝕯٤ḞԍНǏ'
If you have a bytes object that you need to convert to a string, use the decode() method.
Make sure to specify the same encoding in the call to the str.encode() and bytes.decode() methods.
# Discussion
The default encoding in Python 3 is utf-8 .
Python 3 no longer has the concept of Unicode like Python 2 did.
Instead, Python 3 supports strings and bytes objects.
Using the ascii encoding to decode a bytes object that was encoded in a different encoding causes the error.
I wrote a book in which I share everything I know about how to become a better, more efficient programmer.